Umple is a technology for Model-Oriented Programming.
The Umple home page is https://www.umple.org. To download Umple for the command line or an IDE, go to https://umple.org/dl. To use Umple online as a web app, go to https://try.umple.org
Umple allows you to do the following things:
The term "Umple" derives from "UML Programming Language", "Simple" and "Ample".
The quickest way to get started with Umple is to go to UmpleOnline, and select an example listed under 'EXAMPLES'. Each of the user manual pages also allows you to instantly load the examples into UmpleOnline.
To learn more about Umple, read the links on the left of this page, or go to the Umple Home page. In particular, you should browse the tutorials and videos about Umple
See here for the statement regarding privacy and other risks when using Umple.
As is customary when introducing a new language, here are some 'hello world' examples for Umple.
The first two examples demonstrate executable Umple programs with embedded Java main programs. Load these examples into UmpleOnline by clicking on the links. The click 'Execute It' to see the output. Or generate Java code by clicking on the 'Generate It' button; then click on the 'download zip file' link and run 'javac' on the result, followed by 'java' on the resulting class file.
About the first example below: This contains just Java code and is the same as a plain Java program; it illustrates a key feature of Umple: Umple adds features to existing languages: Code in the original language can and does remain the same. Umple just replaces and simplifies some (or a lot) of it.
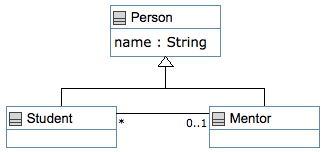
About the second example below: This shows some very simple features of Umple: An attribute, an association, a generalization, some Java methods and the mixin capability:
Umple and UML: Here is the class diagram of the second example in UML. If you click on the 'open in UmpleOnline' link, you will see the UML diagram generated. You can then edit the UML diagram to change the code, or change the code to edit the UML diagram.
About the third and fourth examples below: These are the same as the first two examples, except that they contain embedded main programs in Python and C++. After you load these into UmpleOnline, select either Python or C++ from the 'GENERATE' menu, then select 'Generate It'.
/*
* Simple Hello World example for Umple.
* Compile this with Umple and it will generate Java
* that is essentially the same.
*
* You could just as readily compile this code directly
* with javac. However, this serves as the starting point:
* Other examples in this manual show other things you
* can do with Umple
*/
class HelloWorld {
public static void main(String [ ] args) Java {
System.out.println("Hello World");
}
public static void main(String [ ] args) Python {
print("Hello World")
}
}
Load the above code into UmpleOnline
/*
* Introductory example of Umple showing classes,
* attribute, association, generalization, methods
* and the mixin capability. Generate java and run this.
*
* The output will be:
* The mentor of Tom The Student is Nick The Mentor
* The students of Nick The Mentor are [Tom The Student]
*/
class Person {
name; // Attribute, string by default
String toString () Java {
return(getName());
}
String __str__ () Python {
return self.getName()
}
}
class Student {
isA Person;
}
class Mentor {
isA Person;
}
association {
0..1 Mentor -- * Student;
}
class Person {
// Notice that we are defining more contents for Person
// This uses Umple's mixin capability
public static void main(String [ ] args) Java {
Mentor m = new Mentor("Nick The Mentor");
Student s = new Student("Tom The Student");
s.setMentor(m);
System.out.println("The mentor of "
+ s + " is " + s.getMentor());
System.out.println("The students of "
+ m + " are " + m.getStudents());
}
public static void main(String [ ] args) Python {
import Mentor
import Student
m = Mentor.Mentor("Nick The Mentor")
s = Student.Student("Tom The Student")
s.setMentor(m)
print("The mentor of " + str(s) + " is " + str(s.getMentor()))
print("The students of " + str(m) + " are " + str(m.getStudents()))
}
}
Load the above code into UmpleOnline
/*
* Simple Hello World example for Umple.
* Compile this with Umple specifying either
* -g Python or -g Cpp
*
* Or specify in UmpleOnline either Python or C++
* in the generate menu
*/
class HelloWorld {
public static void main(String [ ] args) Python{
print("Hello World")
}
public static void main(String [ ] args) Cpp{
cout<<"Hello World!";
}
}
Load the above code into UmpleOnline
/*
* Introductory example of Umple showing classes,
* attribute, association, generalization, methods
* and the mixin capability.
* Generate either Python or Cpp and run this.
*
* The output will be:
* The mentor of Tom The Student is Nick The Mentor
* The students of Nick The Mentor are [Tom The Student]
*
* If you try to execute this with Java, it will
* indicate there is no Java main program. See
* the separate Java example in the user manual.
*/
class Person {
name; // Attribute, string by default
String __str__() Python {
return self.getName()
}
}
class Student {
isA Person;
}
class Mentor {
isA Person;
}
association {
0..1 Mentor -- * Student;
}
class Person {
// Notice that we are defining more contents for Person
// This uses Umple's mixin capability
public static void main(String [ ] args) Python{
import Mentor
import Student
m = Mentor.Mentor("Nick The Mentor")
s = Student.Student("Tom The Student")
s.setMentor(m)
print("The mentor of " + str(s) + " is " + str(s.getMentor()))
print("The students of " + str(m) + " are " + str(list(map(str, m.getStudents()))))
}
public static void main(String [ ] args) Cpp {
// Creating a mentor and a student.
Mentor m("Nick The Mentor");
Student s("Tom The Student");
// Associating the student with the mentor
s.setMentor(&m);
m.addStudent(&s);
// Retrieving and printing the mentor of the student.
cout << "The mentor of " << s.getName() << " is " << s.getMentor()->getName() << endl;
// Retrieving the list of students of the mentor.
vector<Student*>* students = m.getStudents();
cout << "The students of " << m.getName() << " are: " << endl;
// Iterating over the students and printing their names.
for (Student* student : *students) {
cout << student->getName() << endl;
}
return 0;
}
}
Load the above code into UmpleOnline
This page describes how to use Umple, either online, as a downloadable command-line compiler, or in various integrated development environments.
Umple files conventionally use the extension .ump. You use one or more of the following tools to edit, view and compile sets of .ump files.
java -jar umple.jar <options> <filename.ump> ...
brew install umpleon a Mac (also available for Linux). This will install the latest stable release, and will update automatically after any new release. Once installed, run as
umple <options> <filename.ump> ...Note that homebrew will try to install openjdk as a dependency in homebrew first (if not already there). If you have Java installed outside of homebrew, you can avoid an unneeded installation by specifying --ignore-depenencies.
The command line compiler can handle thousands of files and millions of lines of Umple code if needed (Umple is written in itself, demonstrating this works well). The command line compiler can be incorporated into product toolchains using technology like Gradle or ant.
Requirement: Docker installed on your computer.
Umple provides a Docker image of Umpleonline that allows you to explore all the features of Umple through a web browser, with the server running locally on your computer. To use this, do the following after installing Docker. Further information can be found on Umple's Docker Hub page
docker pull umple/umpleonline
docker run --rm -ti -p 8000:8000 -v ~/umpledata:/var/www/ump umple/umpleonline >/dev/null
You can also accomplish the above by downloading and installing our script called udock and passing it the optional argument -d {dir} for your local storage directory (otherwise data will be stored in a temporary directory)
More information about Umple in Docker can be found at https://umple.org/docker
New Docker images are produced for each release of Umple, with occasional interim images. A list of Docker images can be found at the Umpleonline DockerHub site. The image tagged 'latest' will be downloaded by default.
Organizing the contents of an Umple (.ump) file
An Umple file will contain a number of top level items we call directives. These can be:
The specific entities you can create include the following
Methods in classes
Much of the code in an Umple file is processed by the Umple compiler, and used to generate code in a 'base' or 'native' language (e.g, Java, PHP or Ruby) for the final system. However methods are treated differently: They are passed through essentially unchanged to the resulting system.
If you include methods in Umple code, you generally have to ensure that any given Umple file has methods of just one chosen target language (Java, PHP, Ruby. etc.). A special syntax is, however, available if you want to generate code in more than one target language.
Anything that Umple can't parse itself may be interpreted to be a method; this can result in unintended results: What you intend to be some Umple code such as an attribute or association may end up being treated as 'extra code', i.e. a method, and passed through unchanged (normally with a warning).
The resulting system will contain many more methods than those that you explicitly include. This is because one of the key points about Umple is that it generates a high percentage of the methods you would normally need to write by hand if you were programming directly in the target language. In other words, when you compile Umple constructs such as associations, attributes and state machines, you are generating many methods that you can call; the set of methods you can call is the generated API. You can find out the API by using Javadoc, or a similar tool, on the generated code, or you can look at the quick reference manual page. One of the options in UmpleOnline is to generate Javadoc output.
Organizing a system containing many files
If your system is large, you should divide it into many files. One way to do this is to follow the Java convention of having one .ump file per class. Another common approach is to have one or more files for the model code (just the pure UML elements such as classes with their attributes, associations and state machines) and separate files for the methods; you can in fact have some files for Java methods, and other files for PHP or Ruby methods. The same model can then be used to develop systems that are deployed in multiple base languages.
The fact that Umple allows for multiple definitions to be added to create a complete definition, also means that you can create mixins. A mixin is a file that has some definitions that can be added to add extra features to a system. You can therefore organize your system, in whole or in part, by feature. The various pieces of code needed to implement a feature (including entire new classes, or bits such as associations and methods to add to existing classes), can therefore be grouped together. There are limits to this, however: At the current time, this mechanism does not allow you to override existing elements, which you might need to do to add a feature. Taken together, these mechanisms allow for a form of product-line development.
Examples of Mixins
The below video shows some ways to incorporate mixins to Umple classes. Follow the following links to watch further examples for:
Here are some arguments to make to help convince you, your management and your colleagues to adopt model-oriented programming and Umple in particular:
Here are some common arguments against adopting a new software development technology, and how they don't apply in model-oriented programming:
The following tags are used to group certain keywords
The following are the key philosophies that govern the evolution of the Umple language and model-oriented programming technology. These are derived from those that first appeared in a paper published in WCRE 2010.
In the following, L refers to a programming language such as Java, Python, PHP or Ruby for which Umple can generate code, or which can be embedded in Umple.
Also in the following, Modeling refers to representing programs at a higher level of abstraction than in a programming language, either textually or with diagrams.
P1. Modeling is programming and vice versa: UML and other modeling concepts can be expressed textually in Umple; hence, one can model in UML using Umple. For a programmer, Umple looks like a programming language, therefore, to such a person they are just programming more abstractly.
P2. An Umple programmer should never need to edit generated code to accomplish any task. The need for round-tripping (editing generated code and then reflecting the edits back into the model) is avoided.
P3. An Umple compiler can accept and generate code that uses nothing but modeling abstractions. The resulting executable can be a module providing an API rather than a complete program. If it has a ‘main’ method and a few extra algorithmic methods it can be a complete program. P3 is a corollary of P1.
P4. A program without Umple features can be compiled by an Umple compiler. This is the inverse of P3. In other words, any program P in base language L compiled by an Umple/L compiler will generate P. This provides a convenient starting point for a programmer who wants to begin using Umple incrementally: They can just change from using an L compiler to an Umple/L compiler.
P5. A programmer can incrementally add Umple features to an existing program. This allows for iterative conversion of a base-language L program into Umple/L, with each step being a straightforward refactoring. We call this process umplification.
P6. Umple extends the base language in a minimally invasive and safe way. A programmer familiar with language L should see the addition of an Umple feature as just a natural extension of L. In other words, Umple appears harmonious with L. As an example, for C-family languages this is accomplished by co-opting the curlybracket block idiom and adding a very small number of additional keywords. Another way of looking at this is that Umple can be seen as a pre-processor added to the base language, that uses a syntax that is very similar to the base language. This should eliminate or reduce any fear that adopting Umple should somehow mean learning a new language. Umple can be used in very small amounts if needed. And those fearful of what would happen if Umple were to ‘go away’ can rest assured that they would still have good quality generated code which could in this circumstance be modified.
P7. Umple features can be created and viewed diagrammatically or textually. One can use model (e.g. UML) diagramming tools to generate an Umple program that contains only modeling abstractions, as in P2. Similarly, since Umple features map directly to modeling constructs such as UML class diagrams and state diagrams, one can easily render any Umple program as a UML diagram. This can be done in real-time using an Umple editor such as UmpleOnline that supports Umple textual code, as well as modeling visualizations. Elements of code that are not Umple abstractions, such as the bodies of methods, are omitted from the diagram.
P8. Umple goes beyond UML, since it directly implements patterns, separation of concerns mechanisms, and other programming idioms. Umple can, for example, generate code for the singleton pattern. Such capabilities further increase Umple’s level of abstraction.
P9. The base language code added to an Umple program corresponds to UML’s concept of an action language. To use UML for model-driven development, i.e. complete generation of an application from a UML model, UML calls for the use of an action language for the algorithmic details. UML diagrammatic modeling tools currently allow snippets of action language to be specified for elements such as state machine actions. Users of these tools have to switch between the visual editor for manipulating the modeling elements, and the textual editor for manipulating the action language snippets. This context switching from diagram to text makes it difficult to understand an entire program when using traditional UML tools.
Umple code can result in generation of various languages. Code from these languages can be inserted into Umple, or Umple can be inserted into code for the languages. The resulting systems can be used as part of larger projects involving these languages.
Here is the status of the programming languages currently:
Umple also generates a rich assortment of other outputs. The complete current list can be seen using the command line with the --help option; the list also appears below.
Several Graphviz diagrams can be generated (UML class diagrams, UML state diagrams, Entity-relationship diagrams, etc.), as can formal methods code in NuXmv and Alloy, and various forms of analysis outputs such as state tables and metrics.
Comments provide a mechanism to document your work to provide some insight into why you are performing a certain action, as opposed to simply showing how.
Comments should be used just like in any programming language.
Comments immediately before class definitions, attribute definitions, association definitions and method definitions, as well as comments embedded in methods will be output into the generated code. Comments before definitions in Java will use Javadoc style; this means that when you generate JavaDoc output the API documentation will contain the comments. You are encouraged to create your Java comments using Javadoc tags.
Comments can be either inlineComments, or multilineComments.
// The Umple system is both fun
// and efficient to development with
Load the above code into UmpleOnline
// The Umple system is both fun and
// efficient to development with
/*
This apple can only be compared to
other apples
*/
Load the above code into UmpleOnline
Use two slashes to place comments after any text on the line. The comment ends at the end of the line. This is the same syntax as in Java, C++ and several other languages.
// Umple is both fun and efficient to develop with
Load the above code into UmpleOnline
Use multiline comments starting with slash-star and ending with star-slash to document your work. You should put a comment block, for example, at the beginning of each file.
This syntax is the same as in Java and C++.
/*
This apple can only be compared to
other apples
*/
Load the above code into UmpleOnline
Requirements allow for the same comment to appear in different sections of the code without typing out the comment multiple times.
They consist of two components: the requirement definition, which contains the comment statement to be added, and the requirement implementation, which specifies where the requirement statement should be added.
Multiple requirements can be called through an implementsReq statement.
A requirement can be tagged with multiple entities like classes, attributes, associations, state machines, traits, methods, interface etc.
A requirement is introduced with the req keyword, followed by an identifier and an optional requirement-language tag. The body is enclosed in curly braces:
req <ReqIdentifier> [<reqLanguage>] { ... }
The supported requirement languages are:
who, when, what, and why sub-blocks.userStep and systemResponse sub-blocks.An implementsReq statement attaches one or more requirements to the surrounding entity. It can appear at the top level (binding to a following mixset or class), inside a class, trait, state machine, attribute, association, or method:
implementsReq <ReqIdentifier> [(<QualityClassName>)] [, <ReqIdentifier> [(<QualityClassName>)]]* ;
The optional parenthesised argument selects a specific quality class of the referenced requirement, which is required when using implementsReq to differentiate alternative designs on a non-functional property:
implementsReq Speed(High), Security(Perfect);
mixset DesignA { ... }
See also:
req R01 {
This is a comment we would like to add
multiple times in different locations.
The identifier used for this requirement is
R01.
}
req R02 {
This is a second requirement statement.
}
implementsReq R01;
class Example {
implementsReq R02;
var1;
var2; implementsReq R01, R02;
}
Load the above code into UmpleOnline
req R1 {
First requirement with the identifier R1.
}
req R2 {
Second requirement with the identifier R2.
}
req R3 {
Third requirement with the identifier R3.
}
req R4 {
Fourth requirement with the identifier R4.
}
req R5 {
Fifth requirement with the identifier R5.
}
req R6 {
Sixth requirement with the identifier R6.
}
// Requirements tagged with class
implementsReq R3;
class A {
// Requirements tagged with attribute
implementsReq R2;
att1;
}
// A second class
class B {
// Requirement tagged with association
implementsReq R2;
* -> * A;
// Requirement tagged with state machine
implementsReq R3;
sm {
s1 {
e -> s2;
}
s2 {
}
}
// Requirement tagged with method
implementsReq R5;
String m1(String s) {
return(s);
}
}
// Requirement tagged with trait
implementsReq R4;
trait C {
g;
}
// Requirement tagged with interface
implementsReq R6;
interface Itest {
String m2(String s);
}
Load the above code into UmpleOnline
Examples of requirements documents in Umple that can be used to generate code
This page provides examples of Umple requirements using both plain-text and structured userStory styles. They show possible ways of specifying requirements. They can be used to guide you before manually creating a model, or to use UmpleOnline AI capabilities to generate actual Umple code.
// The following is a (partial) set of requirements for
// a hotel booking that can be used to experiment
// with generating class diagrams and state machines in Umple // using AI,
// or merely as an example of how requirements can be
// specified in Umple.=
// Req H008 was used in the following thesis by Parva Pathak
// https://ruor.uottawa.ca/items/b3679a91-5445-45ce-b289-bfddba3010f6
req H001 {
The hotel chain keeps a list of hotels in the system, each
with their address and set of rooms
}
req H002 {
There can be various types of rooms, characterized by
quality of the view (Number of guests allowed, Excellent,
good, poor), Number of Queen beds, Number of King beds,
Number of Single beds., whether there is a safe, whether
there is a pullout couch, and whether it is a suite such
that the bedroom is behind a separate door)
}
req H003 {
Each type of room is given a price that will be advertised
for it for each day. Prices are set up 9 months in
advanced, but can be changed dynamically.
}
req H004 {
Each room has a type.
}
req H005 {
On any given day (overnight from one night to the following
morning), each room can be either available, allocated to a
guest, or unavailable due to maintenance.
}
req H006 {
When a room is booked, the price each day for the booking
is confirmed (it will be the room-type price, or less if
discounts are given).
}
req H007 {
A booking has a start date, an end date, a number of adults and a number of children.
}
req H008 {
The hotel runs a system that allows users to book rooms online, providing the following operations:
{
The user can optionally login to the hotel website
The user can choose a location
The user can choose a hotel
The user can choose the number of guests
The user can choose the date range of the visit
The user can choose a room type
The user can pay for the hotel
The user can cancel the booking
}
}
Load the above code into UmpleOnline
// The following is a (partial) set of requirements for
// the process of getting a driver's license in Ontario,
// Canada.
// It can be used for generating state machines in Umple
// using AI,
// or merely as an example of how requirements can be
// specified in Umple.=
// Requirements 1-8 were used in the following thesis by
// Parva Pathak
// https://ruor.uottawa.ca/items/b3679a91-5445-45ce-b289-bfddba3010f6
// It has been extended to also add knowledge for generating
// a class diagram
req L01-LicenseTypes {
The user can have no license, a G1 license, a G2 license or
a G license
}
req L02-G1Test {
To get a G1, a test must be complete
}
req L03-G2Test {
To get a G2, the user must have a G1 and a test must be
completed
}
req L04-GTest {
To get a G, the user must have a G2 and a test must be
completed
}
req L05-Expiry {
Each type of license can expire.
}
req L06-nonrenewG1orG2 {
If a G1 or G2 expires then the license is lost
}
req L07-renewG {
If a G expires it can be renewed
}
req L08-suspension {
Each type of license can be suspended
}
req L09-licensedata {
A license has a licences number and an issued date
}
req L11-holderdata-{
The system will keep the following information about the
holder of a license: Name, Date of Birth, Address
}
req L12-testdata {
The system will keep track of the tests of each license
holder or applicant (who has not yet passed a test), along
with the score on each test.
}
Load the above code into UmpleOnline
// The following is a (partial) set of requirements for
// the card game Blackjack, that can be used to experiment
// with generating state machines in Umple using AI,
// or merely as an example of how requirements can be
// specified in Umple.
// It was used in the following thesis by Parva Pathak
// https://ruor.uottawa.ca/items/b3679a91-5445-45ce-b289-bfddba3010f6
req 001dealing {The player and dealer will be dealt cards}
req 002playerchoice {The player can choose to hit or stand}
req 003dealerchoice {The dealer can choose to hit or stand}
req 004dealerwin {If dealer gets a blackjack the dealer wins}
req 005playermaywin {If the player stands and the dealer has
a lower score the player wins}
req 006dealermaywin {If the player stands and the dealer has
a higher score the dealer wins}
req 007samescoremore {If the dealer and player have the same
score the game will push}
Load the above code into UmpleOnline
// The following is a (partial) set of requirements for
// a credit card approval system that can be used to
// experiment
// with generating state machines in Umple using AI,
// or merely as an example of how requirements can be
// specified in Umple.=
// It was used in the following thesis by Parva Pathak
// https://ruor.uottawa.ca/items/b3679a91-5445-45ce-b289-bfddba3010f6
req CC1 {
The different stages of the approval process must be
included (Pre Approval, Cancelled, Complete, Failed)
}
req CC2 {
The status of the account must be included
(On Hold, Not On Hold)
}
req CC3 {
The transaction can be successful or fail
}
Load the above code into UmpleOnline
// The following is a set of requirements for an agent loop
// system that can be used to experiment with generating
// state machines in Umple using AI, or merely as an example
// of how requirements can be specified in Umple.
req AL01-IdleEntry {
The agent loop waits in an idle mode until a run is started or continued,
then it enters the assistant turn.
}
req AL02-AssistantTurnToolRequest {
During the assistant turn, if the assistant requests tool execution,
the agent loop enters the tool turn.
}
req AL03-AssistantTurnCompletion {
During the assistant turn, if the assistant completes its response,
the agent loop proceeds to a queue check step.
}
req AL04-AssistantTurnFailureOrAbort {
During the assistant turn, if the assistant fails or aborts,
the agent loop ends the run.
}
req AL05-ToolTurnPermissionGate {
During the tool turn, if a requested tool requires permission,
the agent loop pauses to await a permission decision.
}
req AL06-ToolTurnReturnToAssistant {
During the tool turn, when tool execution completes,
the agent loop returns to the assistant turn.
}
req AL07-ToolTurnSteeringInterrupt {
During the tool turn, a steering interrupt can immediately return the loop
to the assistant turn.
}
req AL08-PermissionGranted {
When awaiting tool permission, granting permission allows the agent loop
to resume tool execution.
}
req AL09-PermissionDenied {
When awaiting tool permission, denying permission returns the agent loop
to the assistant turn without continuing tool execution.
}
req AL10-QueueCheckContinue {
After the assistant completes, if a queued message is available,
the agent loop continues with another assistant turn.
}
req AL11-QueueCheckEnd {
After the assistant completes, if no queued message is available,
the agent loop ends the run.
}
req AL12-ResetToIdle {
After the run ends, the agent loop can be reset back to idle.
}
req AL13-QueuedProcessing {
The agent loop processes queued messages in order, and queue checking only
occurs after an assistant completion.
}
Load the above code into UmpleOnline
req US1 userStory {
As a customer, I want to reset my password so that I can regain access to my account.
}
Load the above code into UmpleOnline
req US2 userStory {
who { customer }
when { password is forgotten }
what { reset my password }
why { regain access to my account }
}
Load the above code into UmpleOnline
req US3 userStory {
who { administrator }
what { manage users }
}
Load the above code into UmpleOnline
// Quality requirements introduce named quality classes
// (discrete levels of a non-functional property) that can
// later be bound to alternative designs via implementsReq.
req Speed quality {
High {}
Medium {}
Low {}
}
req Security quality {
Perfect {}
SlightlyRisky {}
Weak {}
}
Load the above code into UmpleOnline
// implementsReq binds a requirement (and optionally a specific
// quality class) to the following entity. Each mixset below is
// an alternative design tagged with its own quality levels.
req Speed quality {
High {}
Low {}
}
req Security quality {
Perfect {}
Basic {}
}
implementsReq Speed(High), Security(Perfect);
mixset DesignA {
class FastSecureCar {}
}
implementsReq Speed(Low), Security(Basic);
mixset DesignB {
class SlowCar {}
}
use DesignA;
Load the above code into UmpleOnline
// Full example producing the alternative-design comparison
// table. The reqQC suboption of PlainRequirementsDoc emits an
// HTML table with one row per quality requirement and one
// column per quality-tagged mixset.
generate PlainRequirementsDoc;
suboption "reqQC";
require subfeature [1..1 of {DesignA, DesignB}];
req Speed userStory {
who { architect }
what { compare speed across designs }
}
req Speed quality {
High {}
Low {}
}
req Security userStory {
who { architect }
what { compare security across designs }
}
req Security quality {
Perfect {}
Basic {}
}
implementsReq Speed(High), Security(Perfect);
mixset DesignA {
class FastSecureCar {}
}
implementsReq Speed(Low), Security(Basic);
mixset DesignB {
class SlowCar {}
}
use DesignA;
Load the above code into UmpleOnline
Requirements can be sorted by ID using the suboption 'reqSortID' and Statement by using the suboption 'reqSortStat'.
The default is to sort by ID when no suboption is provided.
Additionally there is also a suboption 'reqHideNotImpl' to filter out the not implemented requirements.
// This is an example to use reqSortID to sort requirements by thier ID.
suboption "reqSortID";
req A01 {
b requirement.
}
req Z01 {
a requirement.
}
implementsReq Z01;
class Example {
implementsReq A01;
var1;
}
Load the above code into UmpleOnline
// This is an example to use reqSortID to sort requirements by thier Statement.
suboption "reqSortStat";
req A01 {
b requirement.
}
req Z01 {
a requirement.
}
implementsReq Z01;
class Example {
implementsReq A01;
var1;
}
Load the above code into UmpleOnline
// This is an example to show how not implemented requirements can be hidden
suboption "reqHideNotImpl";
req B01 {
b is a requirement.
}
req A02 {
a is a requirement.
}
class Example1 {
implementsReq A02;
var1;
}
Load the above code into UmpleOnline
A requirement can be tagged with the quality language, which marks it as a non-functional requirement characterised by a set of named quality classes. Each class represents a discrete level or option for the property being described (for example High / Medium / Low for speed, or Perfect / SlightlyRisky / Weak for security).
Syntax:
req <ReqIdentifier> quality {
<QualityClassName> {}
<QualityClassName> {}
...
}
Quality classes are declared with empty bodies. Non-empty bodies are currently accepted by the parser but produce warning 403 and have no effect on generated output.
An implementsReq statement can reference a specific quality class using parenthesised arguments, and several bindings can be combined in a single statement:
implementsReq Speed(High); implementsReq Speed(High), Security(Perfect);
When alternative designs (typically different mixsets) are each tagged with quality classes referring to the same set of quality requirements, the designs can be compared on a common set of criteria. See Requirement Quality Comparison Table for the generated output, and Requirements for the general requirement-statement syntax.
// Quality requirements introduce named quality classes
// (discrete levels of a non-functional property) that can
// later be bound to alternative designs via implementsReq.
req Speed quality {
High {}
Medium {}
Low {}
}
req Security quality {
Perfect {}
SlightlyRisky {}
Weak {}
}
Load the above code into UmpleOnline
// implementsReq binds a requirement (and optionally a specific
// quality class) to the following entity. Each mixset below is
// an alternative design tagged with its own quality levels.
req Speed quality {
High {}
Low {}
}
req Security quality {
Perfect {}
Basic {}
}
implementsReq Speed(High), Security(Perfect);
mixset DesignA {
class FastSecureCar {}
}
implementsReq Speed(Low), Security(Basic);
mixset DesignB {
class SlowCar {}
}
use DesignA;
Load the above code into UmpleOnline
Once alternative designs have been tagged with quality classes through implementsReq (see Requirement Quality Classes), the Plain Requirements Doc generator can emit a comparison table. The table lists every quality requirement as a row and every quality-tagged mixset as a column, so the alternatives can be compared on a shared set of criteria.
The feature is activated with the reqQC suboption of the PlainRequirementsDoc generator. From inside an Umple file:
generate PlainRequirementsDoc; suboption "reqQC";
Or from the command line:
umple -g PlainRequirementsDoc -s reqQC your_model.ump
In UmpleOnline you can also select Requirements Doc with Comparison Table from the Generate dropdown, which invokes the same generator with reqQC pre-applied without requiring the suboption "reqQC"; directive in the source file.
The currently-active mixset (the one selected via a use statement or through the UmpleOnline feature-tree selector) is prefixed with an asterisk in the generated table header.
See also Sorting Requirements for other suboptions supported by the same generator, including reqSortID, reqSortStat, and reqHideNotImpl.
// Full example producing the alternative-design comparison
// table. The reqQC suboption of PlainRequirementsDoc emits an
// HTML table with one row per quality requirement and one
// column per quality-tagged mixset.
generate PlainRequirementsDoc;
suboption "reqQC";
require subfeature [1..1 of {DesignA, DesignB}];
req Speed userStory {
who { architect }
what { compare speed across designs }
}
req Speed quality {
High {}
Low {}
}
req Security userStory {
who { architect }
what { compare security across designs }
}
req Security quality {
Perfect {}
Basic {}
}
implementsReq Speed(High), Security(Perfect);
mixset DesignA {
class FastSecureCar {}
}
implementsReq Speed(Low), Security(Basic);
mixset DesignB {
class SlowCar {}
}
use DesignA;
Load the above code into UmpleOnline
Directives appear as the 'main' entries in an Umple file. The following are the main types:
Use statements allow you to decompose your system by embedding or referencing files containing other model elements (such as classes) into your current model, or to include optional code blocks defined in mixsets.
A model file or mixset is included only once; subsequent "use" commands for the same file will be ignored. Preceding a mixset name with '!' indicates to not use the mixset, and cancels out any previous use statement that requested to use the mixset.
A common technique is to create a 'master' Umple file that does nothing but have a list of use statements.
Parts of an individual class can be specified in separate files, and brought together using several use statements. For example the associations or attributes could be in one (or several) files, and the methods could be in one (or more) additional files.
Another way to decompose a system is to have a 'core' set of files that can be included in several different systems using 'use' statements.
Use statements function similarly to 'include' statements in other languages.
A file referred to by a use statement must be in the same directory as the file that has the use statement, or in a parent directory, or in a subdirectory named lib. There are also some builtin Umple files that can be loaded, with the prefix lib:. Finally an https URL may be used to load a file from the Internet
use Core.ump;
Load the above code into UmpleOnline
Namespaces allow you to group similar entities to promote cohesion, as well as reduce the possibility of name collision. Sub-namespaces are separated using a period (.).
In the first example, the classes Faculty and Student will be in namespace school.admin. In Java they will be generated into the admin package (directory) within the school package. Similarly, class Building will be in the elevator.structure namespace.
A previously defined namespace for an entity can be redefined using the "--redefine" option. If the "--redefine" option is not used, the namespace will not change and a warning will be issued (example 2).
Entities declared before any namespace or after "namespace default;" will be in the default package. Entities declared after "namespace -;" will not be in the last declared namespace. Instead, they will be in the default package. If declared after a non-default namespace, the namespace of an entity in the default namespace will be redefined (example 3).
There are some cases where an entity should be imported thus cannot be in the default package and will automatically be placed in another package (example 4). However, automatic import code generation in interfaces that extend interfaces in other packages is not supported yet.
namespace school.admin;
class Faculty{}
class Student{}
namespace elevator.structure;
class Building
{
1 -- * Classroom;
}
class Classroom{}
Load the above code into UmpleOnline
// Entities A, B and C are currently in
// namespace m.
namespace m;
class A{}
interface B{}
class C{}
// To redefine the namespace of an
// entity, use the --redefine option.
// B is now in namespace n.
namespace n --redefine;
interface B{}
// If --redefine is not used, a warning will
// be issued when trying to redefine the
// namespace of an entity
namespace p;
class C{}
// Using namepace -; will deactivate the last
// declared namespace. There will not be an
// attempt to redefine the namespace of interface
// B and a warning will not be issued
namespace -;
interface B{}
Load the above code into UmpleOnline
// Class A will be in the default namespace
class A{}
class B{}
// Class B was in the default namespace
// But now will be in namespace m
namespace m;
class B{}
class C{}
namespace -;
// Because namespace -; was used, namespace m
// is no longer active, and class D will be
// in the default namespace
class D{}
// Class C is in namespace m, but can
// be placed in the default namespace
namespace default --redefine;
class C{}
Load the above code into UmpleOnline
// Classes A is in the
// default namespace. Class B is in
// namespace m. Both are
// linked to each other via an association,
// therefore, and because they are not all
// in the same namespace, an import text
// should be generated. However, many programming
// languages do not support import from
// the default namespace so the namespace of
// A will become m because B is in m.
class A{}
namespace m;
class B{*--* A;}
namespace -;
// The same issue occurs when an
// entity in a non-default namespace
// extends or implements an entity
// in the default namespace
interface E{}
interface F{}
namespace n;
interface J{isA E;}
class K{isA F;}
// Here an import text will be generated for A in X
// because A is in a different namespace
// This feature is not yet supported for interfaces
// that extend interfaces in other namespaces
// and the import text will not be generated for K in Y
namespace p;
class X{isA A;}
// interface Y{isA E;}
// @@@skipcppcompile
Load the above code into UmpleOnline
The strictness directive is used to control certain messages that the Umple compiler may issue. It has five subdirectives that are specified by a second keyword following 'strictness':
The first two are 'modelOnly' or 'noExtraCode'. These are used when the programmer or modeller intends not to include base language code, and wants a warning to appear if base language code is found. Base language code is code in a language like Java or PHP that is discovered by Umple but not interpreted in any way. One example is the code in the bodies of methods; however, when parsing a class, any time Umple cannot parse what it finds, it assumes it must be base language code. It just emits the base language code for the base language compiler to deal with. However there are circumstances when the developer does not want this: The developer may be creating a pure model or may want that the only base language code would be in the body of methods. It is advantageous therefore to tell the compiler to raise a warning if it thinks it has found base language code in some other context, since otherwise, an ordinary Umple syntax error may go undetected, until the base language compiler is run on the code.
The second set of subdirectives are 'expect', 'allow' and 'disallow'. These are used to control the effect of certain messages. They are followed by a message number.
The strictness directives take effect on the entire system being built. The code of all Ump files of that system will be subject to the strictness subdirectives.
// Tell the compiler that error 25
// will appear (and fail if it does not)
strictness expect 25;
// Tell the compiler that if error 22
// occurs, not to fail the compile.
// However, this does not mean that
// code can be generated
strictness allow 22;
// UNDER DEVELOPMENT: The following
// is not operational yet
// Tell the compiler that base language
// code should not appear
strictness modelOnly;
// Tell the compiler that the only base
// language code could be in method bodies
// Any other unparsable 'extra code' in classes
// will be rejected.
strictness noExtraCode;
Load the above code into UmpleOnline
A class definition defines an object-oriented class available for use as a type in the system you are developing. Objects (chunks of data) are created as instances of the class. A class describes the structure of that data in terms of attributes (simple data like strings and numbers), associations (links to and from other objects), state machines, as well as many other things described in this manual.
To define a class in Umple, specify the keyword 'class', followed by the name of the class (starting in a capital letter in order to respect naming conventions as well as to avoid a warning) and then the body of the class within curly brackets.
The body can contain various elements that are listed in the Class Content page.
Traits can be used to add the same set of items to several unrelated classes..
The following UML diagram shows two classes: a Student class and an Address class, linked by an association. The corresponding Umple is below.
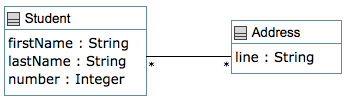
class Student
{
firstName; // attribute - defaults to String
lastName;
Integer number; // attribute with type Integer
* -- * Address; // Many-to-many association
// Method, whose content is not processed by Umple
public String fullName()
{
return getFirstName() + " " + getLastName();
}
}
class Address
{
String[] line; // Multi-valued attribute
}
Load the above code into UmpleOnline
An interface defines a list of abstract methods that are to be implemented in one or more classes. An interface can be composed of the following elements:
To implement an interface in a class, or to create subinterfaces, use an isA clause.
Umple also supports a feature called traits, that has some similarities to interfaces. However, traits concrete methods, attributes and state machines to also be contained in them.
In the following example, RegisterCapable is an interface that defines a single abstract method registerForCourse(). This is implemented concretely by CorporateClient and IndividualStudent.
interface RegisterCapable
{
depend school.util.*;
boolean registerForCourse(Course aCourse);
}
class Person {
name;
}
class CorporateClient {
isA RegisterCapable;
boolean registerForCourse(Course aCourse) {
// write code here
}
0..1 <- * Person employees;
}
class IndividualStudent {
isA Person, RegisterCapable;
boolean registerForCourse(Course aCourse) {
// write code here
}
}
class Course
{
name;
description;
* -- * Person registrants;
}
Load the above code into UmpleOnline
A class can contain any of the following items. Interfaces are limited to those indicated as [Allowed in interfaces]. A trait can contain most of the items, indicated as indicated as [Allowed in traits].
The isA keyword is used to denote an inheritance relationship (generalization) between two classes, or a class and the interfaces it implements, or a class and the traits it includes.
This corresponds to keywords such as 'extends', 'subclass', etc. in other languages. The isA keyword was chosen so as to be independent of other languages, and due to the strong conceptual similarity between interfaces, classes and traits.
Note that it is possible to avoid using the isA keyword for class generalization, by directly embedding a subclass inside a superclass. Note that this does not create an inner class in the Java sense, but instead creates a subclass. The two examples below give identical results.
The following is how a generalization appears in UML. The corresponding Umple is below. Note that in UmpleOnline, the expected layout for generalizations places superclasses above subclasses.
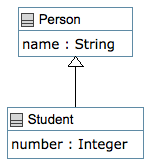
// A superclass-subclass relationship defined using the isA keyword
class Person
{
name;
}
class Student
{
isA Person;
Integer number;
}
Load the above code into UmpleOnline
// A superclass-subclass relationship defined
// by embedding the subclass in the superclass
class Person
{
name;
class Student
{
Integer number;
}
}
Load the above code into UmpleOnline
The depend clause is used to indicate a dependency to another namespace, class or interface.
See also this example of how to use the depend clause to arrange for Umple to work with external code.
namespace sports.core;
class Equipment
{
name;
Integer weight;
}
namespace sports.baseball;
class Baseball
{
depend sports.core.*;
public boolean isRequired(Equipment eq)
{
return eq.getName().equals("bat");
}
}
Load the above code into UmpleOnline
Custom constructors should normally not be provided in Umple. Consider using before and after keywords to adjust what the automatically-generated constructor does, or adjusting constructor parameters using keywords like lazy.
Umple generates its own constructors: The arguments are composed from the list of attributes in the class (in the order provided), as well as any associations with a 1 multiplicity at the other end. To avoid having an argument in the generated constructor, designate an attribute as 'lazy' or specify association multiplicity to be 0..1 instead of 1. Umple also generates code to constrain the value of what appears in each constructor if a constraint is specified.
An attribute represents some information held by a class.
The attribute can have many properties, and can be defaulted to a certain value.
It is important to distinguish an attribute from the concept of a 'field' or 'instance variable' in Java or another programming language. An attribute is a UML/Umple entity that represents simple data. In Java it will become a field, but there will also be methods associated with the Umple attribute to get it, set it, and constrain its value. An attribute may also automatically be added to the argument list of the constructor and constructed in the constructor. In addition to representing attributes, Java fields also represent the ends of associations. Both attributes and associations should be considered more abstract than fields.
A summary of the generated methods for each attribute can be found on the API summary page.
Umple state machines are a special kind of attribute, and Umple also allows you to inject code that will constrain or alter the values of attributes using aspect-oriented techniques.
The example below shows the basic properties of attributes.
class Group
{
// Simple Umple Integer. Note that code generation
// in different languages will use the simplest
// native type in that language. In Java it will
// use int.
// The initial value must be supplied through a
// constructor argument.
// The value can later be accessed through set and
// get methods (here setI and getI).
Integer i;
// const: Declares a constant (static final in Java).
const Integer Max = 100;
// immutable: A constructor argument is required so
// it can be set at construction time; cannot be
// changed after that since no set method is
// generated.
immutable String str;
// lazy: A constructor argument is not required.
// Numbers are initialized to zero.
// Objects (including Strings) are initialized to null,
// Booleans are initialized to false.
lazy Time t;
lazy Boolean b;
lazy s;
// settable: Set using a constructor argument and
// can be changed after that. This is the default,
// so the settable keyword can be omitted.
settable Date d;
// internal: No getter and setter methods created.
// Only for private use in internal methods. However
// in this case it is initalized using = The code
// following = is in the 'base' language, here Java.
internal Time t2 = new Time(
System.currentTimeMillis());
// unique: Every new object created must have a
// unique new value assigned.
// You can get the value. You can set it as well,
// but it has to be unique.
unique u;
// autounique: Every new object created will have a
// new integer assigned.
// You can get the value (an integer) but not set it.
autounique x;
// The value is initialized as shown in the constructor.
// There is no constructor argument generated.
String q = "chicken";
// defaulted: Set in the constructor to the default,
// and can be reset to the default any time by
// calling a reset method (here resetP()).
// Can also be set to any other value using setP().
// The default can be queried by calling getDefaultP().
defaulted String p = "robot";
// Similar to the above, except this shows that if
// no type is given, then the default type is String.
defaulted r = "";
}
// @@@skipcppcompile
Load the above code into UmpleOnline
The following example illustrates the data types available for Umple attributes. Except as specified, they will generate primitive datatypes in Java.
Initialization of values can be performed in a manner similar to Java or C++. Initialization of Dates uses yyyy-mm-dd format, and initialization of Times use hh:mm:dd format.
class Demo
{
Integer i;
Integer i2 = 5;
String str; // the default if no type is specified
str2;
str3 = "";
Float flt;
Double dbl;
Double dbl2 = 8.0;
Boolean bln;
Boolean bln2 = false;
Date dte; // In Java. uses the java.sql.Date class
Date dte2 = "2018-09-25";
Time tme; // In Java. uses the java.sql.Time class
Time tme2 = "14:56:50";
}
Load the above code into UmpleOnline
class DemoNonUmpleType
{
// If you use a non-umple type that is specific to a base
// programming language, then code will be generated
// consistent with that type, but generation of code
// independent of base language is no longer possible
int demoJavaInt;
}
Load the above code into UmpleOnline
You can declare a class as a data type of an attribute. This allows for declaration of a 'containment' relationship.
If the data type you are using for an attribute is an Umple class, users should also consider using an association, and particularly a composition instead. This allows drawing of diagrams and more consistency checks by the Umple compiler.
If you use the methods in the Umple-generated API to access the object stored in such an attribute, and pass this contained object to some remote subsystem, then that remote subsystem will be able to affect the containing object in a backhanded sort of way. This is considered content coupling in software engineering, and should be carefully controlled or avoided.
In the examples below, we show how using attribute notation is very similar to using a directed association, except that with attribute notation, you can set the value to null.
// This first example uses attribute notation
// The address is required on the constructor, but
// can be null. An instance of Address can be
// considered to be contained within the
// Person class.
//
// Although there is nothing currently preventing
// the same address instance from being re-used in
// multiple classes, it is strongly suggested to
// avoid that. If you want to reuse the same
// Address, then use association notation instead.
class Person {
name;
// The following uses a class as the attribute type
Address address;
}
class Address {
street;
city;
postalCode;
country;
}
Load the above code into UmpleOnline
// Contrast this example with the previous one
// Here we use a directed association instead of
// an attribute.
// Note that the multiplicity on the left is of no
// relevance. It is conventional to show it as *
// to indicate that the value could be attached to
// several objects.
//
// Here when you construct a Person, the address
// cannot be null.
class Person {
name;
* -> 1 Address;
}
class Address {
street;
city;
postalCode;
country;
}
Load the above code into UmpleOnline
// In this example, we have made the address
// optional. Now, it does not appear on the
// constructor. However when you add an address it
// still cannot be null.
//
// Note also that in this example, the role name
// 'address' is left off to show it is optional.
class Person {
name;
* -> 0..1 Address;
}
class Address {
street;
city;
postalCode;
country;
}
Load the above code into UmpleOnline
As in UML, Umple allows one to specify an attribute with multiple values.
We encourage the use of association notation in this context, however the attribute notation can be useful sometimes.
Initialization of multivalued attributes is also allowed, as shown in the example.
class Office {
Integer number;
Phone[] installedTelephones;
String[] emails = {"abc@umple.org", "def@umple.org"};
Integer [] incomingNumbers = {765432, 987654};
}
class Phone {
String digits;
String callerID;
}
// @@@skipcppcompile
Load the above code into UmpleOnline
If you want to avoid having an attribute change after it is initially set, but do not want to have an argument in the constructor, then use the combination of keywords 'lazy immutable'.
You can call the set method just once on such an attribute. The set method will return false if you try again. This is useful for interacting with architectures where objects are constructed for you, so you have no ability to specify constructor arguments.
Note that if the lazy keyword is omitted, then there will be no set method and an argument will be present in the constructor to initialize the attribute. See also the immutable pattern.
class A
{
lazy immutable z;
}
Load the above code into UmpleOnline
When declaring an attribute in Umple, you can specify an arbitrary expression after the equals sign to create an attribute that will be computed. There will be no set method on such an attribute.
Note that unless you use the simplest of expressions, you will be limited to only being able to generate code for the language of the expression.
You should make sure you call the get methods provided in the Umple-generated API (rather than directly accessing variables) and avoid having any side-effects in your expressions. Currently this is not enforced, but may be in the future.
For other examples of derived attributes see the sections on the Delegation pattern and sorted associations.
class Point
{
// Cartesian coordinates
Float x;
Float y;
// Polar coordinates
Float rho = {
Math.sqrt(Math.pow(getX(), 2)
+ Math.pow(getY(), 2))
}
Float theta =
{Math.toDegrees(Math.atan2(getY(),getX()))}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
class Rectangle {
Double height;
Double width;
Double area =
Java {height*width} Php {$height*$width}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
Attributes in Umple can be unique. Applying the unique keyword to an attribute ensures that each instance of the class in the currently running program has a unique value for that attribute.
In the first example, each player has a unique ranking. The ranking of a player can change but two players cannot have the same ranking.
The autounique keyword can be used to automatically assign a unique Integer to every new instance created (example 2).
Certain runtime errors can occur if attempts are made to violate uniqueness.
// Every player has a ranking.
// Rankings can be modified,
// but two different players
// can not have the same ranking.
class Player
{
unique Integer ranking;
}
Load the above code into UmpleOnline
// Unique registration numbers (Integer)
// are automatically assigned to every
// new registration created
class Registration
{
autounique registrationNumber;
}
Load the above code into UmpleOnline
The Umple language allows developers to define enumerations for either a single class, or to share between classes. An enumeration is a user-defined data type that is a set of constants.
As shown in the examples below, enumerations require the keyword "enum" followed by the name of the enumeration, and its values. If duplicate enumerations are detected, E095 Duplicate Enumerations will be raised. If enumerations outside of class bodies have the same name as the enumerations within class bodies, the enumerations within class bodies will be used in the generated code.
Model-level enumerations will be added to classes when they do not already have enumerations defined with the same name, and the enumeration is detected in attribute types, method return types, method parameter types, and/or event parameter types.
// In this example, the "Status" enumeration
// is defined for the "Student" class
class Student {
enum Status { FullTime, PartTime }
Status status;
}
Load the above code into UmpleOnline
// In this example, the "Status" enumeration
// is shared by the "GradStudent"
// and "UndergradStudent" class
enum Status { FullTime, PartTime }
class GradStudent {
Status status;
}
class UndergradStudent {
Status status;
}
Load the above code into UmpleOnline
// In this example, the "Status" enumeration
// is shared by the "GradStudent"
// and "UndergradStudent" class
// The "Semester" enumeration is only defined
// for the "UndergradStudent" class
enum Status { FullTime, PartTime }
class GradStudent {
Status status;
}
class UndergradStudent {
enum Semester { Spring, Summer, Fall, Winter }
Status status;
Semester semester;
}
Load the above code into UmpleOnline
// In this case, the "Month" enumeration
// defined in class A will be used in
// the generated code
namespace example;
enum Month {x,y,z}
class A{
enum Month {o,p,q}
Month m;
Month p;
}
Load the above code into UmpleOnline
An association defines a relationship from a class to another class. More specifically, it defines which links (i.e. references or pointers) may exist at run time between instances of the classes.
Umple supports binary associations (associations with just two ends). This definition includes reflexive associations, in which both ends are the same class.
An association can specify the following information:
The following is a UML diagram showing associations. The corresponding Umple is at the end of the page.
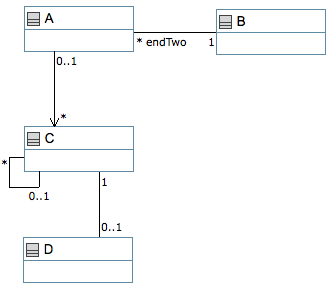
Associations can be presented in two ways in Umple.
There are several special kinds of associations in Umple.
Umple will report an error if an association refers to a non-existent class.
// Example code illustrating various
// kinds of associations
class A {}
// Class with inline association having role name
class B {
1 -- * A endTwo;
}
// Class with reflexive association
class C {
0..1 -- * C;
1 -- 0..1 D; // D is external
}
// Independently defined and directed association
association {
0..1 A -> * C;
}
// Class with composition
class E {
0..1 <@>- * A;
}
// Reference to a class defined elsewhere
external D {}
Load the above code into UmpleOnline
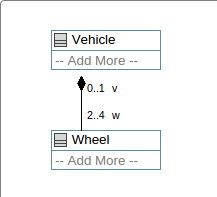
Multiplicity describes the allowable number of entities that can participate in one end of an association. In most cases you provide both a lower and upper bound, but the "many" (or "*") case assumes a zero lower bound.
The most common cases are:
Multiplicity must be specified for both ends of an association. At run time, code generated by Umple will ensure that the lower bounds and upper bounds are respected. Also the multiplicity determines which methods will be generated in the API for the model. For example, when * is specified, methods are generated to access all the associated objects, and to access an object at a specific index. The number of objects linked at run-time is called 'cardinality'.
If multiplicity is specified incorrectly, the compiler will generate an error message highlighting the line with the multiplicity error.
// When multiplicity is given as *, which is the
// same as 0..* there can be any number of links
// from an instance at the other end of the
// association to instances at this end
//
// The lower bound is zero and the upper bound is
// 'many'
class A
{
// an instance of A has many B's
1 -- * B;
// An instance of C has many A's
* -- 1 C;
}
class B {} class C {}
Load the above code into UmpleOnline
// When the mutiplicity is shown as two integers
// separated by .. then the first integer is the
// lower bound, and the second integer is the
// upper bound.
//
// Here, at one end of the association
// the lower bound is 0..1 (which means 'optional'
// and at the other end of the association
// the lower bound is 3 and the upper bound is 5
class D {
0..1 -- 3..5 E;
}
class E{}
// @@@skipcppcompile
Load the above code into UmpleOnline
// When the multiplicity is a single integer there
// must be exactly that number of objects linked
// at all times (including when the object at the
// other end is first created). Except for '1',
// such multiplicities are rare.
//
// Here, there must be exactly two objects (lower
// and upper bound are both 2)
class F {
0..1 -- 2 G;
}
class G{}
Load the above code into UmpleOnline
An association represents a relationship between two classes. Associations can be defined within a class, in a similar manner as you would define an attribute.
Contrast this with the same model defined using independently defined associations.
class Group
{
// a many-to-many association
// An item has zero or more groups and a group
// has zero or more items
* -- * Item;
// An item has an optional description
// The association is directed, so descriptions
// do not know which groups link to them
1 -> 0..1 Description;
}
class Item
{}
class Description
{}
Load the above code into UmpleOnline
An association can be defined separately from any class. Contrast this with the Umple code showing the same model with inline associations.
Specifying an association independently of the two associated classes, as in the example below, can sometimes make code clearer. Specifying the association inline in one of the two classes can be clearer in other cases, particularly when it is defined in the more important class. But the decision regarding which alternative to use is left to the designer.
class Group { }
class Item {}
class Description {}
association {
* Group -- * Item;
}
association {
1 Group -> 0..1 Description;
}
Load the above code into UmpleOnline
A role name is an additional name attached to an association. In the following example, the word 'supervisor' could be omitted, but it clarifies that the graduate student's professor is called his or her supervisor.
class Person {
name;
}
class GraduateStudent {
isA Person;
Integer id;
* -- 0..2 Professor supervisor;
}
class Professor {
isA Person;
rank;
}
Load the above code into UmpleOnline
The examples of associations in the previous user manual pages all showed cases where the lower-bound of the multiplicity at both ends is zero. For example there can be zero graduate students supervised by a professor, and zero professors might be assigned to supervise a graduate student initially.
Allowing a lower bound of zero means that one object can be created without having to first create the object(s) it is to be linked to. The vast majority of associations have a lower bound of zero at at least one of the two ends.
However there are a few situations where the lower bound at both ends of the association ought to be greater than zero. Here we will consider the one-to-one case. In the example below, a Company must always have one BoardOfDirectors and a BoardOfDirectors must always belong to one Company. But which should be created first? If we create the Company first, then a multiplicity constraint would be violated since for a period of time it would lack a Board. One solution would be to relax the constraint and decide that the association should not be 1-1. However Umple does allow 1-1 associations and creates a special API to allow both objects to be created at the same time.
The generated code has a constructor with the arguments normally found in the constructors of both associated classes. So in the following main program, the call to the constructor of Company with just a single argument (company name) will construct both the Company and the BoardOfDirectors and link them (the BoardOfDirectors class normally takes no argument on its constructor). If the constructor of BoardOfDirectors had had any arguments they could have been provided to the constructor of Company. The constructor of Board of Directors also could have been used to create both objects simultaneously.
It is worth noting that when a one-to-one association exists, there must always exist in the running system an equal number of both instances of both associated classes, and they must be linked in pairs.
Another observation is that modellers tend to over-use one-to-one associations. A superior modeling solution might be to merge the two classes; in this case just have a Company class.

// Core class of the example
// A company is a corporation
class Company {
name;
// A company must have a BoardOfDirectors
// that must be created at the same time
// as the Company itself
1 -- 1 BoardOfDirectors;
}
// BoardOfDirectors is in a 1-1 relationship
// with Company meaning that theoretically it
// could just be merged into the Company class
// However to facilitate separation of concerns
// it is sometimes best to keep such classes
// separate
class BoardOfDirectors {
// A BoardMember is just a member of one
// board (but a person can be on multiple
// boards using multiple BoardMembers)
1 -- * BoardMember;
}
// A board must have a set of members
// Former board members tracked
class BoardMember {
bio; // Brief description of background
lazy Date joinedBoard;
lazy Date leftBoard;
// One of the roles a person could play would
// be as a Board member
* boardMembership -- 1 Person;
}
// Generic Person class
class Person {
name;
Date dateOfBirth;
}
// Mixin with a main program demonstrating
// manipulation of 1--1 and other associations
class Company {
depend java.sql.Date;
public static void main(String [] args) {
// First create some instances of Person
// They are initially not on any boards
Person p1 = new Person("Alice",
Date.valueOf("1990-01-01"));
Person p2 = new Person("Bob",
Date.valueOf("1991-02-02"));
// Create a Company using the simpler of its
// two constructors that doesn't require a
// board to already exist. This will actually
// create the BoardOfDirectors at the same time
Company c = new Company("UmpleCorp");
BoardOfDirectors b = c.getBoardOfDirectors();
b.addBoardMember("Largest Shareholder", p1);
b.addBoardMember("Founder", p2);
// Output the results to prove that this works
System.out.println("Key company info: "+c);
System.out.println("Board members: "+
b.getBoardMembers());
}
}
Load the above code into UmpleOnline
A reflexive association is an association from a class to itself. There are two main types: Symmetric and Asymmetric.
Asymmetric Reflexive Associations: The ends of the association are semantically different from each other, even though the associated class is the same. Examples include parent-child, supervisor-subordinate and predecessor-successor.
The first and second examples below show courses having prerequisites that are other courses. It is necessary to specify a role name at one or both ends of the association to distinguish the ends. Also it is necessary to ensure that the lower bound is always zero on both ends. The reason for this is that otherwise an illogical situation would arise: For example, if you said that each course must have one or more pre-requisites, then what about the very first courses in the hierarchy? The compiler will report an error if the lower bound on a multiplicity is one or higher.
The following is how an asymmetric reflexive association appears in UML, as generated by UmpleOnline. The corresponding Umple code is in the first example below.
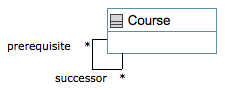
Symmetric Reflexive Associations: There is no logical difference in the semantics of each association end. The fourth example shows one of these: A set of courses that are mutually exclusive with each other essentially make up a set. If course A is mutually exclusive with B, then course B is mutually exclusive with A. In other words, students who have taken one course cannot take another in the set. Umple uses the keyword 'self' to identify this case. Note that at the current time the asociaton itself does not appear in UmpleOnline; this will be fixed.
// Example asymmetric association with role names
// on both ends
class Course {
* successor -- * Course prerequisite;
}
Load the above code into UmpleOnline
// Example asymmetric association with role name
// on one end
class Course {
* -- * Course prerequisite;
}
Load the above code into UmpleOnline
// Example asymmetric association with role name
// on the other end
class Person {
0..2 parents -- * Person;
}
Load the above code into UmpleOnline
// Example symmetric association. Note the use of
// the keyword self
class Course {
* self isMutuallyExclusiveWith;
}
Load the above code into UmpleOnline
A composition is a subtype of association where the delete is mandatory regardless of the multiplicity (enforced delete).
Compositions are used for associations where once the objects are associated, it makes sense for the deletion of one to cause the deletion of the other. This differs from the pre-existing associations, where the delete is dependent on the multiplicity.
For example, consider the case of a Vehicle and Wheel classes. With a regular association, the code would be as follows (where a Wheel can be associated to at most 1 Vehicles, and a Vehicle can have between 2 and 4 Wheels).
See Example 1
Here, the delete code for Vehicle does not delete the associated Wheels, since the multiplicity on Wheel is 0..1 which means the Wheel can exist without a Vehicle. However, on deleting a Vehicle it would make more sense for the associated Wheels to be deleted.
This is where compositions are useful. Rewriting the above example so that a Vehicle is composed with Wheel:
See Example 2
With the composition code, notice how the delete code for the Vehicle deletes all the Wheels associated, although the multiplicity is unchanged.
Compositions can be specified inline, or as separate associations (the same way as regular associations). The following two examples are equivalent to the Wheel-Vehicle example specified above.
See Examples 3 and 4
The following diagram is a representation of how the composition in the included examples is represented in UML, as generated in an editable class diagram by UmpleOnline.
Syntax
The syntax for compositions is the same as for regular associations, except for the arrow used. While in regular associations, the syntax is a -- b for "a associated with b", for compositions it is a <@>- b for "a composed with b", or a -<@> b for "b composed with a". In the class diagrams generated for compositions, the symbol is a filled-in diamond arrow.
class Vehicle {}
class Wheel {}
association {
0..1 Vehicle v -- 2..4 Wheel w;
}
// @@@skipcppcompile
Load the above code into UmpleOnline
class Vehicle {}
class Wheel {}
// vehicle composed with wheels
association {
0..1 Vehicle v <@>- 2..4 Wheel w;
}
Load the above code into UmpleOnline
class Vehicle {
0..1 v <@>- 2..4 Wheel w;
}
class Wheel {}
// @@@skipcppcompile
Load the above code into UmpleOnline
class Vehicle {}
class Wheel {
2..4 w -<@> 0..1 Vehicle v;
}
// @@@skipcppcompile
Load the above code into UmpleOnline
A specialization is a subset of duplicate associations where:
For example, consider the case of Vehicle and Wheel classes and an Optional One to Many association between them. A Wheel can only belong to one Vehicle, but the concept of a Vehicle can include any number of Wheels. Say, for instance, we wanted to create a new Bicycle class that extends Vehicle, but we would like to make use of the association that already exists with a stricter multiplicity (say, a Bicycle can have up to 2 Wheels).
Without specializations, we need to create a new association between Bicycle and Wheel and thus generate some unneeded code and duplicate data fields (both Vehicle and Bicycle would have a list of Wheels, which behave more or less the same). With specializations, simply stating that we want a new association between Bicycle and Wheel (as long as the names match up to the Vehicle to Wheel association) is enough to generate more appropriate code.
// Here we define our base classes
class Vehicle {}
class Wheel {}
// Here we define our subclasses
class Bicycle { isA Vehicle; }
class Unicycle { isA Vehicle; }
// This is the "parent association" so to speak.
// It defines the Vehicle to Wheel relationship
// with as much abstraction as possible.
association {
0..1 Vehicle -- 0..* Wheel vehicleWheel;
}
// Here, we'd like to extend the functionality of
// the previous association to work with
// subclasses of Vehicle, while utilizing as much
// of the existing code as possible.
// Specializations allow us to do this, since:
// -> Bicycle and Unicycle extend Vehicle;
// -> Wheel is part of the Wheel hierarchy;
// -> The bounds on the left are not less specific
// than the left bound of the parent
// association;
// -> The bounds on the right are not less
// specific than the right bound of the parent
// association;
// -> Finally, the role names are the same.
association
{ 0..1 Bicycle vehicle -- 0..2 Wheel vehicleWheel; }
association
{ 0..1 Unicycle vehicle -- 0..1 Wheel vehicleWheel; }
Load the above code into UmpleOnline
An association class defines an object-oriented pattern to manage * -- * (many to many) associations when data needs to be stored about each link of that association.
An association class is a class and can have the items found in an ordinary class (attributes, state machines, etc.).
However it always has two or more 1..many associations to other classes. Each of these is written as:
The first role name is generally omitted. It is only required if both participating class names are the same (i.e. a reflexive association class). There is an example of this below.
The first example below shows classic use of association classes. A Ticket can be sold to Person in order to attend a Seminar. A Seminar can have many Persons, and a Person can attend many Seminars, so one might imagine simply creating a * -- * association between these classes. However, we want to record the ticket number and price for each Person attending each Seminar. We encode these attributes in the Ticket association class.
For most purposes, an association class behaves in the same manner as though it was an ordinary class with two * -- 1 associations to the participating classes (Person and Seminar in this first example). This is shown in the second example below. However, we want to restrict the possibility of having more than one Ticket sold to the same Person for the same Seminar. Association classes add this constraint.
The third example below shows that it is possible to have more than two classes participate in an association class.
The fourth and fifth examples show the use of the role name for the association class itself. The use of such role names is mandatory when the association class on a reflexive many-many association, i.e. the associated classes are the same. In this example there are Members (e.g. people in a club) and some are assigned to be mentors of others. We want to record the date of each assignment, and we do that using an association class. But since both associated classes are the same (Member), we need to use role names on both ends to ensure all links can be navigated unambiguously. At the Assignment end we have menteeAssignments and mentorAssignments (note the plural) and at the Member end we have roles mentor and mentee.
If we do not use the role names in the 5th example, then error 19 will occur because it will not be possible to refer unambiguously to either side of the association.
// A person can attend many seminars,
// and a seminar can be attended by many people
// The relationship between Person and Seminar is
// thus many-to-many.
//
// There is, however, data to record about each
// ticket. This can be recorded as an
// association class
//
// Note the following doesn't currently render
// in UmpleOnline using Correct UML
// association class notation.
// There are plans to fix this.
associationClass Ticket
{
Integer ticketNumber;
Double price = 0.0;
* Person attendee;
* Seminar;
}
class Person
{
name;
}
class Seminar
{
Date when;
address;
}
Load the above code into UmpleOnline
// The following shows how we might model sales of
// Ticket for Seminars to Persons without using an
// association class. Note, however, that in this
// model, it would be possible to sell more than
// one ticket to a Person for the same Seminar.
// Using an association class would hence be
// better than this.
class Ticket
{
Integer ticketNumber;
Double price = 0.0;
* -- 1 Person attendee;
* -- 1 Seminar;
}
class Person
{
name;
}
class Seminar
{
Date when;
address;
}
Load the above code into UmpleOnline
// The following shows a 'quaternary' association,
// where the association class represents data in
// an association that links four classes.
class SportsPlayer {
name;
}
class Season {
year;
}
// e.g. goalie, forward etc.
class PlayingPosition {
description;
}
class Team {
name;
}
// This gathers the number of points a player
// gained on a particular team in a particular
// season while playing in a particular position
// To get the total points in any one category,
// you would have to add the points several
// instances
associationClass PlayerInPosition {
Integer points;
* SportsPlayer player;
* Season;
* Team;
* PlayingPosition position;
}
Load the above code into UmpleOnline
// The following example is a simple class that
// shows an association class using both a
// single role name for one associated class (a1)
// and two role names to make links to the
// other associated class.
class A{
f;
}
associationClass B{
* A a1;
* b2 C c1;
}
class C {
d;
}
Load the above code into UmpleOnline
// This shows a reflexive association class, where
// the associated classes are the same (Member).
// In this case we must use role names at both
// ends to ensure navigation to the correct sets
// (mentors, mentees)
class Member {
name;
}
associationClass Assignment {
Date dateEstablished;
* menteeAssignments Member mentor;
* mentorAssignments Member mentee;
}
Load the above code into UmpleOnline
It is possible to arrange for associations to maintain themselves in sorted order according to the value of an attribute. Create a derived attribute in order to define a complex sort order or to sort on the value of an attribute of an associated class (the first example below does this in one case).
To declare an association as sorted do the following: after specifying the multiplicity, and any role name, give the keyword 'sorted' followed by the name of an attribute (sort key) in curly brackets. Whenever an add method is called to add an item to the association, Umple ensures the association is maintained in sorted order. .
Note that Umple associations are always 'ordered' by default; i.e. the user controls the position of items. Declaring an association as sorted makes this automatic. The presence of 'sorted' adds a 'sort' function to the API to allow for resorting (if the attributes on which sorting is based are changed, for example) and removes the API for manually ordering the association using addXAt().
Errors are generated if the attribute specified as the sort key attribute does not exist in the class, or the sort key attribute is not of a recognized type.
Java serialization of sorted associations is possible without the need to modify the Java code generated by Umple. The two ends of a sorted association implement the Serializable interface by default. Association items can be serialized and deserialized. After deserialization, more items can be added to the association and the association is maintained in sorted order as demonstrated by the second example.
// This example demonstrates two cases of sorted
// associations. The main program adds items out
// of order. But when they are printed the output
// will be sorted
class Academy {
1 -- * Course;
1 -- * Student registrants sorted {id};
}
class Student {
Integer id;
name;
}
class Course {
code;
}
class Registration {
* -- 1 Student;
// In each course, sort registrations by name
* sorted {name} -- 1 Course;
// Derived delegated attribute used for sorting
// printing
name = {getStudent().getName()}
// Derived delegated attribute used for sorting
// printing
code = {getCourse().getCode()}
public String toString() {
return "Registration: " + getName()
+ ":" + getCode();
}
}
// Mixin with main program and toString method
class Academy {
public static void main(String [ ] args) {
Academy ac = new Academy();
Student j = ac.addRegistrant(12,"Jim");
Student a = ac.addRegistrant(4,"Ali");
Student m = ac.addRegistrant(8,"Mary");
Student f = ac.addRegistrant(3,"Francois");
Course c = ac.addCourse("CS191");
Course c2 = ac.addCourse("AN234");
j.addRegistration(c);
a.addRegistration(c);
m.addRegistration(c);
f.addRegistration(c);
m.addRegistration(c2);
f.addRegistration(c2);
System.out.println(ac);
}
public String toString() {
String result="Students:\n";
for (Student s: getRegistrants()) {
result +=s + "\n";
}
result +="Courses:\n";
for (Course c: getCourses()) {
result +=c + "\n";
}
return result;
}
}
class Student {
public String toString() {
String result="Student=" + id + "["
+ name + "\n";
for (Registration r: getRegistrations()) {
result +=" In: " + r + "\n";
}
return result;
}
}
class Course {
public String toString() {
String result ="Course=" + code + "\n";
for (Registration r: getRegistrations()) {
result +=" Has: " + r + "\n";
}
return result;
}
}
Load the above code into UmpleOnline
// This example demonstrates serialisation of
// sorted associations in Java. The main program
// adds items to an object out of order, serialize the
// object, deserialize it and then add more items
// to it. When they are printed after deserialisation,
// all items will appear in the right order.
class Academy {
1 -- * Student registrants sorted {id};
}
class Student {
Integer id;
name;
}
// Mixin with main program, toString method
// and serialization test
class Academy {
depend java.nio.file.*;
depend java.io.*;
public static void main(String [ ] args) {
String filename = "SortedSerializableAssociation.ser";
Academy ac = new Academy();
Student j = ac.addRegistrant(12,"Jim");
Student a = ac.addRegistrant(4,"Ali");
System.out.println("Before Serialization");
System.out.println(ac);
//serialization
try
{
FileOutputStream file = new FileOutputStream(filename);
ObjectOutputStream out = new ObjectOutputStream(file);
out.writeObject(ac);
out.close();
file.close();
}
catch(Exception ex)
{
System.out.println(ex.getMessage());
}
Academy ac2 = null;
// Deserialization
try
{
FileInputStream file = new FileInputStream(filename);
ObjectInputStream in = new ObjectInputStream(file);
ac2 = (Academy)in.readObject();
in.close();
file.close();
}
catch(Exception ex)
{
System.out.println(ex.getMessage());
}
// Adding new elements and comparing
try
{
Student m = ac2.addRegistrant(8,"Mary");
Student f = ac2.addRegistrant(3,"Francois");
}
catch(Exception ex)
{
System.out.println(ex.getMessage());
}
System.out.println("After Serialization");
System.out.println(ac2);
}
public String toString() {
String result="Students:\n";
for (Student s: getRegistrants()) {
result +=s + "\n";
}
return result;
}
}
class Student {
public String toString() {
String result="Student=" + id + "["
+ name +"]"+ "\n";
return result;
}
}
Load the above code into UmpleOnline
Umple supports basic OCL-type Boolean constraints that limit what umple-generated mutator methods (set, add, etc.) and constructors can do. If a constraint is violated set methods will return false, and constructors will throw an exception.
Constraints are specified within square brackets. Simple constraints can refer to attributes and literals (numbers, strings). These can be compared using standard comparison operators such as < and >. Expressions can be conjoined by the and operator && or the or operator ||. An exclamation mark is the not operator. Parentheses can be used to adjust the standard order of operations.
Additional capabilities are being developed in Umple to allow other types of constraints.
// The following demonstrates two simple
// constraints limiting the range of age
// The test code demonstrates that this works
// as expected.
class Client {
const Integer MinAge =18;
Integer age;
[age >= MinAge]
[age <= 120]
public static void main(String [ ] args) Java {
Client c = new Client(40);
for (int i: new int[]
{-1,10,17,18,19,50,119,120,122,1000})
{
System.out.println(
"Trying to initialize age to "+i);
System.out.println(c.setAge(i)
? " Success"
: " FAILURE");
}
}
public static void main(String [ ] args) Python {
import Client
c = Client.Client(40)
for i in [-1, 10, 17, 18, 19, 50, 119, 120, 122, 1000]:
print("Trying to initialize age to", i)
print(" Success" if c.setAge(i) else " FAILURE")
}
}
Load the above code into UmpleOnline
// Example with a few more operators
class X {
Integer i;
Integer j;
[i > j]
[i < 5 && j > 0]
[! (i == 10)]
}
Load the above code into UmpleOnline
You can specify basic preconditions in methods as shown below. Like other constraints, they are specified in square brackets. Precondition appears as the first lines of a method and must start with 'pre:'. A precondition can refer to one or more attributes or method arguments. If a precondition is not satisfied when the method is run an exception will be thrown; in Java a RuntimeException is used.
class PotentialVoter {
Integer age;
int vote(int candidate) {
[pre: age >= 18]
[pre: candidate > 0]
// rest of stuff that we do not interpret
return 0;
}
}
Load the above code into UmpleOnline
Constraints can be used to assert that certain properties of the model are as expected, as shown in the examples below. Associations, attributes and generalizations can be checked.
Why would model constraints be useful, given that a programmer can just inspect the code to see if there are statements declaring the facts in question? The answer is that Umple has sophisticated separation of concerns mechanisms including traits, mixins and mixsets, and the developer may not be completely sure that a given model constraint will always be true. An attribute, for example, might be only introduced into the class in a completely different file or mixset, and the developer may not be certain that the file or mixset is being included. Using a model constraint allows a developer who wants to use that attribute in a method to cause an Umple compilation error if it does not in fact exist, rather than waiting to see if Java code fails to compile.
Below is an example of a model constraint, but there are other examples in the manual pages that give help about the error messages raised by these constraints:
class X {
// Checks that this class has an association
// with class Z.
[model: -- Z]
}
class Y {
isA X;
// Verifies that this is a subclass of X
[model: isA X]
}
class Z {
a;
1 -- * X;
// Verifies that there is an association a
[model: has a]
}
Load the above code into UmpleOnline
Use the Singleton keyword to mark a class as a singleton class. The code ensures that only one object of the class is instantiated at runtime.
For more details on the Singleton pattern, see this Wikipedia page.
class Airline
{
singleton;
}
Load the above code into UmpleOnline
Mark a class as immutable to force all its contents to be immutable. The code ensures all attributes and associations can only be set in the constructor, and cannot be modified again subsequently.
The only associations allowed to be immutable are directed associations to other immutable classes.
A class can only be immutable if all its superclasses are also immutable. Declaring a superclass immutable forces its subclasses to be immutable; in other words, immutability is inherited. If the subclasses break immutability constraints (such as the type of attributes allowed), then errors will be raised.
Individual attributes and associations can be marked as immutable instead of the entire class. An attribute can be marked as lazy immutable if it needs to be initialized after the constructor has finished. An immutable class cannot have an association to a non-immutable class.
For more details on the Immutable pattern, see this Wikipedia page.
// A simple example of an immutable class
class Point2D
{
immutable;
Float x;
Float y;
}
Load the above code into UmpleOnline
// An example of one immutable class making reference to another
class Path
{
immutable;
1 -> * Point2D pathElements;
}
class Point2D
{
immutable;
Float x;
Float y;
}
strictness allow 36; // We are OK with this warning
Load the above code into UmpleOnline
// Example of the declaration of an association to be immutable
// Note that this can be set only the first time
class X {
Integer id;
immutable * -> 0..1 Y;
}
class Y {
immutable;
someInfo;
}
Load the above code into UmpleOnline
Delegation is one of the most fundamental patterns, that underpins many more sophisticated patterns found in the Gang of Four book. To simplify code, reduce coupling, and adhere to the 'Law of Demeter', it encourages you to create one-line methods that do nothing other than call methods in neighbouring classes. Other code in your class then calls the delegation methods, rather than also calling the methods in the neighbouring classes. That way, very few methods (just the delegation methods) actually need to traverse associations
In Umple there is no special syntax for delegation, however the notation for derived attributes has the effect of creating delegation methods in the manner shown in the example below.
Delegation methods can also be used to help build occurrences of other patterns such as
Note that delegation methods as shown here are 'read only'. They generate a get method with the name of the derived attribute, not a set method.
// This system has many delegation methods so that information in one class can
// be obtained in a neighbouring class easily. The delegation is created using
// derived attributes, which generate get methods for use by other code.
class Airline {
code;
name;
1 -- * RegularFlight;
}
// A regular flight flies every day and has a flight number and other fixed data.
class RegularFlight {
Integer number;
Time depTime;
* outgoing -- 1 Airport origin;
* incoming-- 1 Airport destination;
fullNumber = {getAirline().getCode()+getNumber()}
}
// A specific flight actually has passengers
class SpecificFlight {
* -- 1 RegularFlight;
Date depDate;
// Four delegation attributes to save multiple methods in this
// class from having to traverse the association
flightNumber = {getRegularFlight().getFullNumber()}
Airport origin = {getRegularFlight().getOrigin()}
Airport destination = {getRegularFlight().getDestination()}
Time plannedDepTime = {getRegularFlight().getDepTime()}
}
// A passenger on a flight
class Booking {
lazy seat;
* -- 1 SpecificFlight;
* -- 1 Passenger;
// Second-level delegation - data comes from RegularFlight
flightNumber = {getSpecificFlight().getFlightNumber()}
Airport destination = {getSpecificFlight().getDestination()}
// Simple delegation
passengerName = {getPassenger().getName()}
Time plannedDepTime = {getSpecificFlight().getPlannedDepTime()}
//Simple method using the data gathered by delegation
public String toString() {
return getFlightNumber()+" "+getPlannedDepTime()+" "+
getDestination().getName()+" "+getPassengerName()+" "+getSeat();
}
}
class Passenger {
lazy Integer freqFlyerNumber;
name;
}
class Airport {
code;
name;
}
// Mixin with main program to test the above
class Airline {
public static void main(String [ ] args) {
Airport ott = new Airport("YOW","Ottawa");
Airport tor = new Airport("YYZ","Toronto Pearson");
Airline a = new Airline("AO","Air Ottawa");
RegularFlight r = a.addRegularFlight(100,java.sql.Time.valueOf("13:12:00"),ott,tor);
SpecificFlight f = r.addSpecificFlight(java.sql.Date.valueOf("2017-03-15"));
Passenger p = new Passenger("John");
Booking b = new Booking(f,p);
System.out.println(b);
}
}
Load the above code into UmpleOnline
In any class you can specify a set of attributes and associations as keys. The associations must have a multiplicity of 1 at the other end. This allows Umple to generate code that defines what objects of the class are equal (they have the same values for the key).
Umple will also generate a hashCode method in any class that has a defined key. This helps when looking up an object in a set.
Place the comma-separated list of key elements in curly brackets, after the word key. If you have multiple key statements, a warning is generated.
class Sport {
name;
description;
code;
key { code }
}
class League {
name;
id;
geographicalArea;
* -- 1 Sport;
Date seasonStart;
Date seasonEnd;
key { id }
}
class Team {
name;
* -- 1 League;
}
class Player {
name;
Integer id;
key { id }
}
class PlayerOnTeam {
Integer year;
* -- 1 Player;
* -- 1 Team;
key { year, player, team }
}
Load the above code into UmpleOnline
When modeling, it is common to encounter situations where there will be objects (abstractions) that need to store information that will not vary among many other objects (occurrences). We want to avoid duplicating the data in each occurrence.
Examples include:
It is an antipattern (i.e. poor design) to use the same class for both abstraction and occurrence. It is also an antipattern to use generalization (i.e. erroneously making the occurence a subclass of the abstraction) because that would result in duplication of data in the attributes of the occurrences. This is often not well-understood by inexperienced modelers.
The solution is to create a one-to-many association between the abstraction class and the association class. Umple provides a built-in pattern to make abstraction-occurrence relationships explicit, although using an ordinary association would be a valid alternative.
To use this pattern, add a use statement to incorporate the built-in AbstractionOccurrence.ump file. Then use isA statements to declare which class is an Abstraction, and which is an occurrence (of which Abstraction). Follow what is show in the second block of code below.
This is one of several patterns in Umple Umple that are built into the language as of 1.32 via a use statement. See the code below.
// Generic pattern for abstractions and occurrences
// In any Umple program say 'use lib:AbstractionOccurrence.ump;' to include this pattern.
// Something that has many occurrences
// Examples include a TV show that has episodes, where the show has a name you don't want to repeat in each episode
// Or a route that has runs, or a published book in a library where there are many copies
trait Abstraction {}
// Something representing occurrences of an abstraction
// where both the abstraction and the occurrences need their own instances
// It is common for modellers to make mistakes and just have one class
// Or to consider the Occurrences as instances of the abstractions, but these are antipatterns
trait Occurrence <Abstraction> {
* -- 1 Abstraction;
}
Load the above code into UmpleOnline
/* Example of using builtin Umple
* Abstraction Occurrence pattern file
*/
use lib:AbstractionOccurrence.ump;
class Author {
name;
}
class Book {
isA Abstraction;
title;
* -- * Author;
}
class CopyOfBook {
isA Occurrence <Abstraction = Book>;
Integer barcode;
}
Load the above code into UmpleOnline
When modeling, it is common to encounter situations where one wants to make multiple subclasses, but can not or should not for various reasons. One reason not to create a subclass is because instances may need to change class as their roles in the system change. Another reason not to create a subclass is because an instance may need to play two or more roles smultaneously.
The solution is to create a Role class and to link it by a many-to-one association to the main class (which we will call the Player class).
To use this pattern, add a use statement to incorporate the built-in PlayerRole.ump file. Then use isA statements to declare which class is a Player, and which is an Role (of which Player). Follow what is show in the second block of code below.
This is one of several patterns in Umple Umple that are built into the language as of 1.32 via a use statement. See the code below.
// Generic pattern for players and roles
// In any Umple program say 'use lib:PlayerRole.ump;' to include this pattern.
// A player is an object that can have many roles
// A person can be an employee and a student
trait Player {}
// A captures some functionality that a player may have
// either temporarily or in conjunction with other roles
trait Role <Player> {
* -- 1 Player;
}
Load the above code into UmpleOnline
/* Example of using builtin Umple
* Player Role pattern
*/
use lib:PlayerRole.ump;
class Person {
isA Player;
name;
}
class TeamRole {
isA Role<Player=Person>;
}
class Athlete {
isA TeamRole;
}
class Coach {
isA TeamRole;
}
class ParentOfAthlete
{
isA TeamRole;
* -- * Athlete;
}
class SportsTeam {
nickname;
* -- * TeamRole;
}
Load the above code into UmpleOnline
Transportation systems for airlines, bus networks and train networks have many things in common. This is a high level pattern to capture one way of representing common features of those models.
The pattern consists of traits representing
This is only one possible design for a transportation system, but it illustrates some possibilities. The two examples show how the design has been applied to create an airline system and a bus system.
Experiment with the diagrams in UmpleOnline. You can use control-G and Control-E to switch layout; you can use control-R to toggle between viewing traits or collapsed classes.
// This is a library of traits that can be used
// to build the core of transportation systems
use lib:AbstractionOccurrence.ump;
// A route such as a flight or bus route
trait Route <Stop> {
routeID; // generic ID for all runs on this route, e.g. bus route number the public sees
* -- * Stop;
}
// A run pattern at a particular time of day that
// is repeated on multiple days
trait RegularlyScheduledRun <Route, ScheduledStop> {
isA Abstraction;
runId; // e.g. a flight number / Bus systems tend to hide this from public
String plannedDaysOfWeek; // e.g. "135" for Mon, Wed, Fri
* -- 1 Route;
Boolean forwardDirection; // only relevent if routeID is same in both directions
1 -- * ScheduledStop; // contains the times of the stops in order; not all runs may stop at all stops on route.
}
// A stop on a particular regular run
trait ScheduledStop <Stop> {
* -- 1 Stop;
Time expectedArrivalTime; // null for departure only
Time expectedDepartureTime; // May be same as arrival time for busses. Null for arrival only
}
trait Stop {
stopName; // e.g. Airport, bus station etc.
}
// People can book on this for flights. It can be late or cancelled
trait ActualRun <RegularlyScheduledRun, Vehicle> {
isA Occurrence <Abstraction = RegularlyScheduledRun>;
Date runDate;
Boolean isCancelled;
* -- 1 Vehicle vehicleUsed;
}
// Specific plane, bus, etc.
trait Vehicle {
vehicleID;
}
Load the above code into UmpleOnline
/* Example of using builtin Umple pattern files
*/
use lib:AbstractionOccurrence.ump;
use lib:TransportationPatternA.ump
// This shows how a general pattern for
// transportation can be adapted to
// describe an airline
class AirlineRoute {
isA Route <Stop = Airport>;
}
class RegularFlight {
isA RegularlyScheduledRun <
Route = AirlineRoute,
ScheduledStop = AirportStop
>;
}
class AirportStop {
isA ScheduledStop <Stop = Airport>;
}
class Airport {
isA Stop;
}
class SpecificFlight {
isA ActualRun <
RegularlyScheduledRun = RegularFlight,
Vehicle = Airplane
>;
}
class Airplane {
isA Vehicle;
}
Load the above code into UmpleOnline
/* Example of using builtin Umple pattern files
to create a bus system
*/
use lib:AbstractionOccurrence.ump;
use lib:TransportationPatternA.ump
// This shows how a general pattern for
// transportation can be adapted to
// describe a bus system
class BusRoute {
Integer routeNumber;
isA Route <Stop = BusStop>;
}
class RegularlyTimedBusRun {
isA RegularlyScheduledRun <
Route = BusRoute,
ScheduledStop = TimedStopAtBusStop
>;
}
class TimedStopAtBusStop {
isA ScheduledStop <Stop = BusStop>;
}
class BusStop {
isA Stop;
}
class BusRun {
isA ActualRun <
RegularlyScheduledRun = RegularlyTimedBusRun,
Vehicle = Bus
>;
}
class Bus {
isA Vehicle;
}
Load the above code into UmpleOnline
A state machine has a fixed set of of values (called states) The state machine transitions from state to state by the occurrence of events. State machines are very useful for quickly defining a program's behaviour.
In Umple, a state machine is modeled as a special type of attribute. In any class, simply specify the state machine name, and follow the name by a block starting with '{' and ending with '}'. This indicates to Umple that you are defining a state machine, and not an ordinary attribute.
Within the block, you list the names of the various states. Each state is followed by a block, again indicated using '{' to start and '} to end. This block defines the details of a state.
Details of each state can include:
Note that, in addition, you can specify code to be executed whenever an event is processed by using before or after directives.
The following diagram shows a garage door state machine as a UML diagram. The Umple code for this is in the second example shown, and is further explained in the video below.
// This example shows a simple state machine
// without any actions or guards
//
// In the following, status is a state machine,
// and acts like an attribute, whose value is set
// by various events.
//
// Open, Closing, Closed, Opening and HalfOpen are
// the possible values, or states, of status.
//
// buttonOrObstacle, reachBottom and reachTop are
// events. These become generated methods that can
// be called to cause a state change.
//
// To make the state diagram appear in
// UmpleOnline, select 'Options' then choose
// 'GraphViz State Diagram'
class GarageDoor
{
status {
Open { buttonOrObstacle -> Closing; }
Closing {
buttonOrObstacle -> Opening;
reachBottom -> Closed;
}
Closed { buttonOrObstacle -> Opening; }
Opening {
buttonOrObstacle -> HalfOpen;
reachTop -> Open;
}
HalfOpen { buttonOrObstacle -> Opening; }
}
}
Load the above code into UmpleOnline
// This is a more fully-featured state machine for
// a garage door corresponding to the diagram
// above
class Garage {
Boolean entranceClear=true;
GarageDoor {
Closed {
entry/{stopMotor();}
entry/{triggerEnergySaveMode();}
exit/ {triggerNormalEnergyMode();}
pressButton -> /{turnLightOn();} Opening;
}
Opening {
entry/{runMotorForward();}
openingCompleted -> Open;
}
Open {
entry/{stopMotor();}
// do {wait(60000); turnLightOff();}
pressButton [getEntranceClear()] -> Closing;
}
Closing {
entry/{runMotorInReverse();}
closingCompleted -> Closed;
pressButton -> /{flashLightOn();} Opening;
}
}
boolean runMotorInReverse() Java {
System.out.println(
"Running motor in reverse");
return true;
}
boolean runMotorInReverse() Python {
print("Running motor in reverse")
return True
}
boolean flashLightOn() Java {
System.out.println("Flashing light on");
return true;
}
boolean flashLightOn() Python {
print("Flashing light on")
return True;
}
boolean turnLightOn() Java {
System.out.println("Turning light on");
return true;
}
boolean turnLightOn() Python {
print("Turning light on")
return True
}
boolean turnLightOff() Java {
System.out.println(
"Turning light off");
return true;
}
boolean turnLightOff() Python {
print("Turning light off")
return True
}
boolean runMotorForward() Java {
System.out.println(
"Running motor forwards");
return true;
}
boolean runMotorForward() Python {
print("Running motor forwards")
return True
}
boolean triggerEnergySaveMode() Java {
System.out.println(
"Triggering Energy Saving Mode");
return true;
}
boolean triggerEnergySaveMode() Python {
print("Triggering Energy Saving Mode")
return True
}
boolean stopMotor() Java {
System.out.println("Stopping motor");
return true;
}
boolean stopMotor() Python {
print("Stopping motor")
return True
}
boolean triggerNormalEnergyMode() Java {
System.out.println(
"Triggering Normal Energy Mode");
return true;
}
boolean triggerNormalEnergyMode() Python {
print("Triggering Normal Energy Mode")
return True
}
boolean waitawhile() Java {
System.out.println("Waiting");
return true;
}
boolean waitawhile() Python {
print("Waiting")
return True
}
boolean test() Java {
System.out.println("Testing");
return true;
}
boolean test() Python {
print("Testing")
return True
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
Transition actions: When a transition is taken, an action can occur. This is indicated using a slash "/" followed by arbitrary code in braces. The arbitrary code may be placed after the event name or before the destination state name. In other words the arrow -> can be placed either directly after the event (before the action), or directly before the destination state (after the action)
Entry and exit actions: Similarly, when entering or exiting a state, an action can occur. This is indicated using the keywords entry or exit, followed by a slash, followed by code.
The actions described above should be programmed such that they take negligible time to execute; in other words they shouldn't contain significant loops..
Do activities: If a longer-running computation (activity) needs to be done while in a state, encode this using the keyword do, followed by a block of code in curly brackets. In languages such as Java that support it, a thread will be started to invoke the code. This allows the state machine to 'stay live' and be able to respond to other events, even while the do activity is running. A do activity thread can be interrupted and cancelled when a transition is taken out of the state. To enable this in Java, the code it needs to catch InterruptedException as shown in the first example.
namespace example;
class LightFixture
{
bulb
{
On {
entry / { doEntry(); }
exit / { doExit(); }
push -> /{ doTransition(); } Off;
do { doThisContinuouslyWhileOn(); }
}
Off {}
}
void doEntry() {System.out.println("Entry");}
void doExit() {System.out.println("Exit");}
void doTransition() {
System.out.println("Transition");}
void doThisContinuouslyWhileOn() {
while (true) {
System.out.println("Still on");
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {}
}
}
}
Load the above code into UmpleOnline
// This demonstrates that actions can be different
// in different target languages
class DemoSM
{
Integer id;
sm {
s1 {
e1 / Java {id=5;} Php {$id=5;} -> s2;
}
s2 {
}
}
}
Load the above code into UmpleOnline
A state machine can be nested inside another. This often allows for simpler Umple (or UML) notation, since events that need to cause effects in every substate of the outer state do not have to be repeated in each of the substates.
The first example below illustrates nesting abstractly. The next example shows nesting in a concrete example. The third example is the same as the second, but with no nesting, to illustrate the difference.
// Illustration of nested states. Event e1 will
// take the system into state s2, and its first
// substrate s2a. Event e2 directly goes to s2b.
// Event e3 toggles between s2b and s2a.
// Event e1 when in s2, goes to s1
class A {
sm {
s1 {
e1 -> s2;
e2 -> s2b;
}
s2 {
e1 -> s1;
s2a {
e3 -> s2b;
}
s2b {
e3 -> s2a;
}
}
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
// Example showing nested states.
class Course {
code;
description;
1 -- * CourseSection;
}
class CourseSection
{
// Example from Lethbridge and Laganiere: Object
// Oriented Software Engineering: Practical
// Software Development using UML and Java
// McGraw Hill, 2005
// https://www.site.uottawa.ca/school/research/lloseng/
sectionId;
Integer classSize = 0;
Integer minimumClassSize = 10;
Integer maximumClassSize = 100;
// State machine controlling status
status
{
Planned {
openRegistration -> NotEnoughStudents;
}
Open {
cancel -> Cancelled;
NotEnoughStudents {
closeRegistration -> Cancelled;
register
[getClassSize() > getMinimumClassSize()]
-> EnoughStudents;
}
EnoughStudents {
closeRegistration -> Closed;
register
[getClassSize() > getMaximumClassSize()]
-> Closed;
}
}
Cancelled {}
Closed {}
}
boolean requestToRegister(Student aStudent)
{
register();
return setClassSize(getClassSize()+1);
}
}
class Student {
//Remainder of this class defined elsewhere
}
Load the above code into UmpleOnline
// Example with an opportunity to nest states, to
// avoid repeating transitions
class Course {
code;
description;
1 -- * CourseSection;
}
class CourseSection
{
// Example from Lethbridge and Laganiere: Object
// Oriented Software Engineering: Practical
// Software Development using UML and Java
// McGraw Hill, 2005
// https://www.site.uottawa.ca/school/research/lloseng/
sectionId;
Integer classSize = 0;
Integer minimumClassSize = 10;
Integer maximumClassSize = 100;
// State machine controlling status
status
{
Planned {
openRegistration -> OpenNotEnoughStudents;
}
OpenNotEnoughStudents {
closeRegistration -> Cancelled;
cancel -> Cancelled;
register
[getClassSize() > getMinimumClassSize()]
-> OpenEnoughStudents;
}
OpenEnoughStudents {
closeRegistration -> Closed;
cancel -> Cancelled;
register
[getClassSize() > getMaximumClassSize()]
-> Closed;
}
Cancelled {}
Closed {}
}
boolean requestToRegister(Student aStudent)
{
register();
return setClassSize(getClassSize()+1);
}
}
class Student {
// Remainder of class defined elsewhere
}
Load the above code into UmpleOnline
It is possible for a system to be in two states at once. This can be accomplished by dividing any state (we will call it the parent state) into regions separated by || symbols. Each region is like a small state machine, and the system is in one state of each of the regions until it exits the parent state.
In the example below the TrackShuttler starts off initializing then transferringLoad. But after that it starts shuttling (going to the other end of some kind of track). During shuttling, it independently controls its moving in one region, and the lights in the other region. Here shuttling is the parent state. While shuttling the system can be in lightsOn+accelerating, lightsOn+coasting, lightsOff+coasting, lightsOff+braking or in any of the 2*3=6 total configurations of substates of the two regions. When an exit from shuttling occurs due to the reachEnd event, the state machine exits both controllingLights and moving.
In general there can be any number of regions, and regions can be nested in arbitrary ways.
class TrackShuttler {
sm {
initializing {
readyToGo -> transferringLoad;
}
transferringLoad {
loaded -> shuttling;
}
shuttling {
reachEnd -> transferringLoad;
moving {
nearEnd -> braking;
accelerating {
reachedMaxSpeed -> coasting;
}
coasting {
tooSlow -> accelerating;
}
braking {
tooSlow -> coasting;
}
}
||
controllingLights {
lightsOn {
daylightDetected -> lightsOff;
}
lightsOff {
darknessDetected -> lightsOn;
}
}
}
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
In Umple, there are two ways to define final states.
The first way is to use the "Final" keyword (with a capital F) as the destination of a transition. This automatically defines a final state for the top-level state machine. Once the state machine is in this state, it is considered to be complete, and it is terminated. The "Final" keyword can be used as shown in the example below. Note, if a user defines a state named "Final", error E074 User Defined State Cannot be Named Final will be thrown.
The second way is to use the "final" keyword (lower case) before a state name to tag a state as final. Using this keyword allows users to define multiple final states as shown in the second example below. In the case of concurrent regions (indicated using the || in the example), all state machines within the same concurrent region must be in their final states before the enclosing region is considered to be complete. In the case of non-concurrent state machines, as soon as a final state is entered, the state machine is considered to be complete.
// Using the keyword "Final" automatically defines the
// final state for the top-level state machine "sm"
class X {
sm {
s1 {
goToS2 -> s2;
}
s2 {
goToFinal -> Final;
}
}
}
Load the above code into UmpleOnline
// "s1" is an orthogonal region, and it is
// considered to be complete when all of the
// concurrent state machines are in their final
// states (i.e. s2 is in state "s4", s5 is in
// state "s7", and s8 is in state "s10")
class X {
sm {
s1 {
s2 {
s3 {
goToS4 -> s4;
}
final s4 { }
}
||
s5 {
s6 {
goToS7 -> s7;
}
final s7 { }
}
||
s8 {
s9 {
goToS10 -> s10;
}
final s10 { }
}
}
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
// "sm" will be considered as complete when
// it is in either state "s3" or "s5"
class X {
sm {
s1 {
s2 {
goToS3 -> s3;
goToS4 -> s4;
}
final s3 { }
}
s4 {
goToS5 -> s5;
final s5 { }
}
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
It is possible to arrange for a state machine to transition automatically from one state to the next immediately after completing entry actions or upon completion of a do activity. This is specified using a transition without any preceding event. Such transitions may have guards and transition actions.
// In this example, the system will transition to s2 automatically
// when the do activity ends
class X {
sm {
s1 {
entry / {
System.out.println("Starting first sleep");
}
do {
Thread.sleep(2000);
System.out.println("Ending first sleep");
}
-> s2;
}
s2 {
entry / {
System.out.println("Starting second sleep");
}
do {
Thread.sleep(2000);
System.out.println("Ending second sleep");
}
}
}
public static void main(String [ ] args) {
X x = new X();
}
}
Load the above code into UmpleOnline
In Umple, the keyword 'unspecified' can be used to handle events that have no handlers in the current state (and would normally be ignored) in a queued or regular state machine. If an 'unspecified' transition is present, no event in that state will be ignored. The keyword can be placed at any level of nesting of the state machine, and specifies a transition, using the same syntax as a regular event name (hence it can have a guard, and and action) as well as a destination state.
For example, in the first example below, if finishedClosing occurs while in the closed state, this event would be ignored if 'unspecified' were not present. But the 'unspecified' keyword causes a transition to be taken for any unexpected event while in closed, opening, open or closing states.
Note that tf the 'unspecified' keyword is used in a pooled state machine, it will simply be treated as a regular event since pooled state machines do not ignore events without handlers, but leave them at the head of the queue.
Unspecified transitions are particilarly useful to transition to error-handling states. In the examples below, the system transitions back to normal functioning after handing the error. The use of transitions to history can also be useful in this situation.
//A garage door can be modeled
//using unspecified events for
//error states
class GarageDoor {
status {
functionning {
unspecified -> error;
closed {
pressButton -> opening;
}
open {
pressButton -> closing;
}
closing {
finishedClosing -> closed;
}
opening {
finishedOpening -> open;
}
}
error {
entry / {
/* attempt to solve the issue */
}
ready -> functionning;
}
}
}
Load the above code into UmpleOnline
//The state machine sm makes use
//of the unspecified event to reach
//specific error states to complete
//auto-transitions
//If the machine is idle and receives
//a non-handled event, the destination
//state is error 1, while if the sm was
//in state active, the machines reaches
//error 2
class AutomatedTellerMachine{
queued sm{
idle {
cardInserted -> active;
maintain -> maintenance;
unspecified -> error1;
}
maintenance {
isMaintained -> idle;
}
active {
entry /{readCard();}
exit /{ejectCard();}
validating {
validated -> selecting;
unspecified -> error2;
}
selecting {
select -> processing;
}
processing {
selectAnotherTransiction -> selecting;
finish -> printing;
}
printing {
receiptPrinted -> idle;
}
cancel -> idle;
}
error1{
->idle;
}
error2{
->validating;
}
}
void readCard() {/*Code would be written here*/}
void ejectCard() {/*Code would be written here*/}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
A transition can be triggered after a specified delay (a floating point value, given in seconds). The transition will be taken after the delay provided the object is still in the state and any guard is true. This is accomplished using the 'after' keyword.
The 'afterEvery' keyword, tries to trigger a transition repeatedly at a specified interval while the object remains in the state.
// In this example, the system will transition to state b
// after a 1-second delay
class X {
sm {
a {
entry / {System.out.println("entering a");}
after(1) -> b;
}
b {
entry / {System.out.println("entering b");}
}
}
public static void main(String [ ] args) Java {
X x = new X();
}
public static void main(String [ ] args) Python {
x = X()
}
}
Load the above code into UmpleOnline
// In this example, the system will transition to state b
// when the value of the attribute count drops below 5
// An attempt to make this transition is taken every second
// The do activity slowly drops the value of count
class X
{
Integer count = 10;
sm
{
a
{
entry / { System.out.println("entering a"); }
do
{
while (count > 0)
{
System.out.println("Count = " + count);
Thread.sleep(1000);
count --;
}
}
afterEvery(1) [count<5] -> b;
}
b
{
entry / { System.out.println("entering b"); }
}
}
public static void main(String [] args)
{
X x = new X();
}
}
Load the above code into UmpleOnline
The history state of any state is its last-visited substate. This is recorded in order to be able to transition to that substate again when needed.
There are two types of history states: Deep history states and regular history states. Deep history stores the specific substate at the deepest level of nesting, while the regular history stores only the first-level substate.
A transition to a history states is indicated using dot notation, by referring to the state to go back to, followed by a dot and either the symbol H to transition to the regular (first-level) history state, or HStar to transition to deep history. When Umple draws a state machine diagram, the deep history appears as H*.
Transitions to history are most commonly used when the system has had to leave normal operation temporarily and needs to later return to exactly what it was doing. Deep history is often appropriate when returning to normal operation, but sometimes regular history is needed in order to allow some form of reinitialization of a substate. When transitioning to history, if there is more than one level of nesting (i.e. the history state has substates), the state machine will enter the start substate of the history state.
//The class Machine uses both deep history
//and regular history states.
//When the event emergency occurs, the
//state of normalOperation is stored.
//When the issue is resolved, depending
//on the intended behaviour, the state
//machine goes back to the specific
//substate it was previously in (HStar)
//or it restarts the phase it was in (H)
class Machine {
sm {
initializing {readyForOperation -> normalOperation;}
normalOperation {
phase1 { completePhase1 -> phase2;}
phase2 {
subphase2a { complete2a -> subphase2b;}
subphase2b {}
completePhase2 -> phase3;
}
phase3 {}
emergency -> handleEmergency;
}
handleEmergency {
resolveEmergency -> normalOperation.HStar;
resolveButCleanup2a -> normalOperation.H;
}
}
}
// @@@skipphpcompile Php does not generate proper
// history state code (see issue 1338)
// @@@skipcppcompile
Load the above code into UmpleOnline
//The class DrawingTool uses a history
//state to get back to the state it was
//previously in after a selection
class DrawingTool {
sm {
drawing {
idle {
penPress -> drawingStroke;
colorChange -> changingColor;
}
drawingStroke {
entry / {
/*deal with the stroke*/
}
endStroke -> idle;
}
changingColor {
colorSelected -> idle;
}
changeMode -> selecting;
}
selecting {
selectionCompleted -> drawing.H;
}
}
}
Load the above code into UmpleOnline
An event can have a parameter (of any valid type that the generated language can accept). The generated event method will have this parameter. The value of the parameter can be used in guards or transition actions.
It is absolutely necessary that all events with the same name have the same parameter type, or else an error will be raised.
// The do activity of the first state machine is a thread that
// communicates with the second state machine.
// It calls the event method e with different arguments.
// The second state machine only changes state when the
// guard detects that the argument is valid
// The argument is also used in the transition action code.
class X {
stateMachine1 {
s1a {
do {
// This do activity sends events to stateMachine2
e(5);
Thread.sleep(1000);
e(6);
Thread.sleep(1000);
e(7);
Thread.sleep(1000);
e(8);
}
-> s1b;
}
s1b {}
}
stateMachine2 {
s2a {
entry / {System.out.println("s2a");}
e(int a) [a > 6] / {System.out.println("e"+a);} -> s2b;
}
s2b {
entry / {System.out.println("s2b");}
e(int a) / {System.out.println("e"+a);} -> s2a;
}
}
public static void main(String [ ] args) {
X x = new X();
}
}
Load the above code into UmpleOnline
Standard state machines operate in a single thread. When an event method is called, the state machine code that runs continues the same thread of the caller. This can be satisfactory for simple applications, but it doesn't work in multi-threaded environments, and can also result in deadlocks.
To overcome the above problems, a state machine may be declared as 'queued' by just placing the keyword queued before the declaration of the state machine. In a queued state machine, the calls to the event methods simply add a record to the queue, and then return. The calling thread can then continue and do other activities. A separate thread exists in each state machine to take events off the queue and process them, in the order they are received. The thread will only process the event at the head of the queue when in a state that has a transition corresponding to that event; otherwise it will wait until the state machine enters such a state.
A queued state machine will process events in the same order as a regular state machine. See also pooled state machines for a variation on this semantics.
// Test of queued state machines.
// The word queued results in a thread being
// created to process events.
class TestSM {
queued sm{
s1 {
e1 /{System.out.println("e1");} ->s2;
}
s2 {
e2 /{System.out.println("e2");} ->s3;
}
s3 {
e3 /{System.out.println("e3");} ->s4;
}
s4 {
e4 /{System.out.println("e4");} ->s1;
}
}
public static void main(String [] ags){
TestSM test=new TestSM();
test.e1(); // processed s2
test.e2(); // processed s3
test.e3(); // processed s4
test.e4(); // processed s1
test.e1(); // processed s2
// queued: ignored
// pooled: left in queue, until we
test.e3(); // are next in s3
// pooled: left in queue, until
test.e4(); // next in s4
// pooled: processed goes to s3
// pooled: process e3 from queue
// goes to s4
// pooled: process s4 from queue
test.e2(); // goes to s1
test.e1();
test.e3();
test.e2();
test.e4();
test.e1();
test.e2();
test.e3();
test.e4();
test.e1();
test.e2();
test.e4();
test.e3();
test.e4();
test.e1();
test.e3();
test.e2();
test.e3();
test.e1();
test.e4();
test.e2();
test.e1();
test.e2();
}
}
Load the above code into UmpleOnline
Queued and regular state machines always process events in the order they arrive, and ignore events that cannot be handled in the current state. Sometimes, however, you want to 'save' events that arrive out of sequence, and process them as soon you enter a state that can handle them. This is accomplished by adding the word 'pooled' before a state machine definition.
In a pooled state machine there is a queue in a separate thread, just like in a queued state machine, however, if the next event to be processed has no handler in the current state, then it remains at the front of the queue, and the queue processor looks further back in the queue for the first event that can be handled.
A pooled state machine will therefore often process events in a different order from a regular or queued state machine.
// Test of pooled state machines.
// The word pooled results in a thread being
// created to process events, and 'pooled'
// semantics being employed. Events which cannot
// be handled are kept waiting until entry into a
// state where they can be handled.
class TestSM {
String ev="";
pooled sm{
s1 {
e1 /{ev="e1";} ->s2;
e5 /{ev="e5";} ->s2;
}
s2 {
e2 /{ev="e2";} ->s3;
}
s3 {
e3 /{ev="e3";} ->s4;
}
s4 {
e4 /{ev="e4";} ->s1;
}
}
after e* {
if(wasEventProcessed)
System.out.println(ev);
}
public static void main(String [] ags){
TestSM test=new TestSM();
test.e1(); // processed s2
// Will only be processed in the
test.e5(); // pooled case (eventually)
test.e2(); // processed s3
test.e3(); // processed s4
test.e4(); // processed s1
test.e1(); // processed s2
// queued: ignored
// pooled: left in queue, until we
test.e3(); // are next in s3
// pooled: left in queue, until
test.e4(); // next in s4
// pooled: processed goes to s3
// pooled: process e3 from queue
// goes to s4
// pooled: process s4 from queue
test.e2(); // goes to s1
test.e1();
test.e3();
test.e2();
test.e4();
test.e1();
test.e2();
test.e3();
test.e4();
test.e1();
test.e2();
test.e4();
test.e3();
test.e4();
test.e1();
test.e3();
test.e2();
test.e3();
test.e1();
test.e4();
test.e2();
test.e1();
test.e2();
}
}
Load the above code into UmpleOnline
State machines can be defined at the top level of a model. This feature allows the definition of reusable state machines, to simplify code, or to facilitate separation of concerns.
The example below shows that the statemachine keyword is used to specify a standalone state machine. Such a state machine, by itself, must be syntactically correct, and error messages will be generated, enabling debugging. However, the state machine is not displayed as a diagram and will not result in any code generation unless it is incorporated in one or more classes. The as keyword is used to do incorporate a standalone state machine in a class, as shown in the example.
An alternative, and equivalent, way to define state machines outside of classes is to use traits. A model equivalent to the example below is shown in Example 5 of the page on state machines in traits.
Standalone state machines can be used to make code appear simpler than it does when the state machine is directly incorporated in a class or trait, as there is less indentation, and the statemachine keyword makes it more explicit that what is being described is a state machine.
// Class Diagram illustrating use of top-level state machine with
// usage in separate classes.
// Note that this could also be accomplished by putting the
// state machine in a trait, and then having each class use the trait
class MotorController {
motorStatus as deviceStatus;
}
class BrakeController {
brakeStatus as deviceStatus;
}
// By itself, the following will not generate any code
// but it can be debugged by itself outside of any class
// and can be incorporated in multiple classes, as above
statemachine deviceStatus {
inactive {
activate -> booting;
}
booting {
completedStartupChecks -> active;
startupCriticalErrorDetected -> outOfOrder;
}
active {
runtimeCriticalErrorDetected -> outOfOrder;
deactivate -> shuttingDown;
}
shuttingDown {
shutdownComplete -> inactive;
}
outOfOrder {
repaired -> inactive;
}
}
Load the above code into UmpleOnline
// Class Diagram illustrating standalone state machine being
// modified when it is reused, to add additional events
// states and entry/exit actions
class MotorController {
Boolean warmup = false;
motorStatus as deviceStatus {
// Add a transition to the reused state machine
cancel booting-> inactive;
completedStartupWhilewarning booting -> warm ;
// Add transition with action
warmSoReady inactive -> / {warmup=true;} booting ;
// Add an entirely new state
warm {
go -> active;
}
// add an entry action to an existing state
inactive {
entry / {warmup=false;};
}
};
}
// Reusable standalone state machine
statemachine deviceStatus {
inactive {
activate -> booting;
}
booting {
completedStartupChecks -> active;
startupCriticalErrorDetected -> outOfOrder;
}
active {
runtimeCriticalErrorDetected -> outOfOrder;
deactivate -> shuttingDown;
}
shuttingDown {
shutdownComplete -> inactive;
}
outOfOrder {
repaired -> inactive;
}
}
// @@@skipphpcompile - contains java code
// @@@skippythoncompile - Contains Java Code
Load the above code into UmpleOnline
State machines can be built from parts. Elements of state machines can be added in several ways:
By repeating the state machine definition in the same class, adding more detail. In the example below, the state machine sm has part of its definition starting at line 2, and part of its definition starting at line 26.
By using standalone transitions. Line 20 shows that outside the context of any state, a transition can be defined. Just add the origin state before the arrow. This one indicates that when e3 occurs, if in state b, then go to state a. This notation can be used to help separate concerns, and place focus on a particular transition. Another example of this is at line 31, where event e5 can cause a transition from state bsub1 to state a. Note that line 34 shows another way of indicating a standalone transition, by adding more detail to state a (that had already beed defined starting at line 3).
By using mixins where a more detail to a class (and its contained state machine) is added. Starting at line 26, there is a new definition adding more detail to class X, which in turn adds more detail to state machine sm starting at line 29.
By using mixsets: Mixsets are like mixins but can be either excluded or included in the system. To include a mixset,add a use statement (as i line 49) or command line option. An example starts at line 39, where yet more detail is added to class X and its state machine sm. This is activated with the use statement at line 49.
class X {
sm {
a {
// Ordinary transition
e1-> bsub1;
}
b {
bsub1 {
// transition in substate
e2 -> bsub2;
}
bsub2 {}
}
// Standalone transition
// at to level
e3 b -> a;
// Standalone transition
// between substate
e4 bsub2 -> bsub1;
}
}
// Mixin for class that mixes in
// more details into the state machine
class X {
// Supplemental detail for same
// state machine
sm {
// Standalone transition
e5 bsub1 -> a;
// Another way of adding a transition
a {e6 -> bsub2;}
}
}
// Mixset to optionally add more detail
mixset extra class X {
sm {
// Adding a new state
c {}
// Adding a transition
e7 b -> c;
}
}
// Activating the above mixset
use extra;
Load the above code into UmpleOnline
The Umple language allows a developer to extend the functionality of a class with arbitrary methods written in the natively compiled language (e.g. Java, Php or Ruby).
Within these arbitrary methods, a developer may call generated methods that access the Umple attributes, associations and state machines. To determine what API methods are available to be called by methods, refer to the API reference or generate Javadoc from an Umple file using UmpleOnline.
A standard Umple method will specify the return type, then the name, then the argument list and finally the method body in curly brackets. The generated output for the method will use correct format for the generated language and will be public.
generate Java;
// A class with a method displayName() that has no arguments
class Person
{
name;
String displayName()
{
return("Hello, my name is " + getName());
}
}
Load the above code into UmpleOnline
generate Java;
// A class with a method that has arguments
class Person
{
name;
String displayName(String greeting, String property)
{
return(
greeting +
", my " +
property +
" is " +
getName());
}
}
Load the above code into UmpleOnline
generate Java;
// A class with a method that uses 'public'.
class Person
{
name;
public String displayName()
{
return("Hello, my name is " + getName());
}
}
Load the above code into UmpleOnline
An abstract method is a method declaration with no implementation. These methods are to be implemented in classes with the specific behaviour intended.
Abstract methods can be defined in classes using the keyword "abstract", followed by the method's signature. By declaring a method abstract, the class containing it is abstract as well, meaning no instances of it can be created (the new keyword cannot be used to create an object of the class). The abstract class must have one or more subclasses that have concrete implementations of the abstract method.
An interface can only contain abstract methods, and the keyword is not needed. The usage of the abstract keyword in a trait declares a required method.
//The class Person contains abstract
//methods, which are inherited and
//implemented by its subclass Student
//Person is abstract, but Student is a
//concrete class as it has no methods
//that are unimplemented.
class Person {
abstract void method1();
abstract void method2();
void method3() Java {
/* Implementation */
}
void method3() Python {
''' Implementation '''
}
}
class Student {
isA Person;
void method1() Java {
/* Implementation */
}
void method2() Java {
/* Implementation */
}
void method1() Python {
''' Implementation '''
}
void method2() Python {
''' Implementation '''
}
}
Load the above code into UmpleOnline
//The class Shape contains an abstract
//method, area, as well as a concrete
//method move, which has its implementation
//shared across all subclasses
//Shape is an abstract class, because it
//contains an abstract method
class Shape {
color;
Integer x;
Integer y;
abstract Double area();
void move() Java {
/* implementation */
}
}
//Both Square and Circle are concrete
//classes as they implement all inherited
//abstract methods
class Square {
isA Shape;
Double width;
Double height;
Double area() Java {
return getWidth()*getHeight();
}
Double area() Python {
return self.getWidth()*self.getHeight()
}
}
class Circle {
isA Shape;
Double radius;
const Double PI = 3.1416;
Double area() Java {
return PI*radius*radius;
}
Double area() Python {
return self.PI*self.radius*self.radius
}
}
class A {
Square s;
Circle c;
void Test() Java {
//The method implemented in Shape is
//used
s.move();
c.move();
//The methods implemented in their
//respective classes are used
s.area();
c.area();
}
void Test() Python {
# The method implemented in Shape is
# used
self._s.move()
self._c.move()
# The methods implemented in their
# respective classes are used
self._s.area()
self._c.area()
}
}
Load the above code into UmpleOnline
In Umple, the body of a method will by default be emitted unchanged. This ties the model to the particular programming language. However it is possible to provide alternative implementations for different programming languages by preceding the method body with the language name.
This multi-lingual capability also works for other places where native code is injected such as in state machine guards and actions, or in derived attributes.
// Generating Java and Php the following will
// result in the appropriate
// method body being selected.
class LanguageSpecific {
int m1() Java {
// Return 1 if the model is compiled into Java
return 1;
}
Php {
// Return 0 if the model is compiled into Php
return 0;
}
}
Load the above code into UmpleOnline
// A method body may work for several languages.
// If no language is specified it is taken as the
// default.
class LanguageSpecific {
int m1()
Java,Php {
// Return 0 if the model is compiled into
// Java or Php
return 0;
}
{
// Default implementation for other languages
return 1;
}
}
Load the above code into UmpleOnline
A state-dependent method is a partial method body declared within a state machine. Each of these partial definitions are subsequently aggregated into a single function within the Umple class as switch cases.
Note that while it is possible to define state-dependent methods across several state machines, the switched cases must be disjoint as the order within the cases is non-deterministic. Additionally, if a method of the same name and parameter set is provided in the same class then it is used as the default body for the function.
class Mario {
Modifiers {
Small {
Normal {
void onHit() {
Die();
}
}
Invulnerable {
void onHit() {
// took no damage
}
}
void render() {
// draw small mario
}
EatMushroom -> Large;
Star -> Small.Invulnerable;
Die -> Dead;
}
Large {
Normal {
void onHit() {
Shrink();
}
}
Invulnerable {
void onHit() {
// took no damage
}
}
void render() {
// draw large mario
}
Shrink -> Small;
Star -> Large.Invulnerable;
}
Dead {
void render() {
// draw dying animation
}
}
}
}
// @@@skipphpcompile - See #1351. State-dependent methods are exclusive to Java generation.
// @@@skipcppcompile
Load the above code into UmpleOnline
external Thread {};
class Philosopher {
isA Thread;
Fork leftFork;
Fork rightFork;
String fname;
boolean isLeftHanded;
ForksInHand {
NoForks {
LookingForForks {
void eat(){
if (isLeftHanded) {
if (leftFork.take()) {
System.out.println(fname + " picked up first fork (left)");
LeftForkAcquired();
}
}
else if (rightFork.take()) {
System.out.println(fname + " picked up first fork (right)");
RightForkAcquired();
}
}
AteFood -> Idling;
}
Idling {
BellyGrumble -> LookingForForks;
}
LeftForkAcquired -> ForkInLeft;
RightForkAcquired -> ForkInRight;
}
ForkInLeft {
void eat() {
if (rightFork.take()) {
System.out.println(fname + " picked up second fork (right)");
RightForkAcquired();
}
}
RightForkAcquired -> ForkInBoth;
}
ForkInRight {
void eat() {
if (leftFork.take()) {
System.out.println(fname + " picked up second fork (left)");
LeftForkAcquired();
}
}
LeftForkAcquired -> ForkInBoth;
}
ForkInBoth {
void eat() {
System.out.println(fname + " is eating.");
try {
sleep(1000);
} catch (InterruptedException ex) { }
AteFood();
leftFork.putDown();
rightFork.putDown();
}
AteFood -> NoForks;
}
}
Belly {
IsHungry {
boolean isHungry() {
return true;
}
AteFood -> IsFull;
}
IsFull {
void think() {
System.out.println(fname + " is full. Now thinking...");
try {
sleep(1000);
} catch (InterruptedException ex) { }
BellyGrumble();
}
BellyGrumble -> IsHungry;
}
}
public void run() {
while (true) {
if (isHungry()) {
eat();
} else {
think();
}
}
}
}
class Fork {
depend java.util.concurrent.*;
Semaphore fork = new Semaphore(1);
boolean take() {
try {
Thread.sleep(100);
} catch (InterruptedException ex) { }
return fork.tryAcquire();
}
void putDown() {
fork.release();
}
}
class Main {
public static void main(String[] args){
String[] names = {"Plato", "Aristotle", "Cicero", "Confucius", "Eratosthenes"};
int k = names.length;
Philosopher[] philosophers = new Philosopher[k];
Fork[] forks = new Fork[k];
for (int i = 0; i < k; ++i) {
forks[i] = new Fork();
}
for (int i = 0; i< k; ++ i) {
Fork leftFork = forks[i];
Fork rightFork = forks[(i + 1) % forks.length];
philosophers[i] = new Philosopher(leftFork, rightFork, names[i], i == k - 1);
philosophers[i].start();
}
}
}
// @@@skipphpcompile - See #1351. State-dependent methods are exclusive to Java generation.
// @@@skipcppcompile
Load the above code into UmpleOnline
A trait is a group of class content items that serves as building blocks for classes.
A trait implements its main functionality through methods, state machines, and other modeling elements used for modeling behavior.
Clients of traits: Clients of traits can be classes and other traits. In other words, a trait is a partial description of a class that can be reused in several different classes, and traits can form hierarchies. The client uses the isA clause to include the trait content.
Enabling multiple inheritance: Traits can be used in place of standard inheritance where there is already a superclass, since multiple inheritance is not allowed in Umple to be consistent with Java and several other languages.
Separation of concerns: Traits can be used to inject attributes, associations, state machines, constraints, methods and many other elements. They are one of several approaches in Umple to separation of concerns. The others are the mixin ability (ability to specify a class several times and have the elements added together), mixsets, and the aspect oriented capabilities. Note that traits themselves are subject to being mixed in. You can declare two parts of the same trait in two different places in an Umple system.
Defining traits: Umple traits are defined through the keyword 'trait' followed by a unique name and a pair of curly brackets. The name must be alphanumeric and start with an alpha character, or the symbol (underscore). We also recommend capitalizing the first letter of traits names, as is the case for classes and interfaces in Umple. All elements of traits are defined inside the curly brackets except template parameters defined between the name and the curly brackets. There are separate pages describing how to incorporate attributes, state machines, template parameters, required interfaces, and associations into traits.
Traits are not types: An Umple trait cannot be used as a type of a variable (whereas a class or interface can).
Required methods: Traits also can have missing functionality which is defined as a set of required (abstract) methods. These required methods must be provided by clients of traits, either directly or indirectly. Required methods are defined similarly to the way abstract methods are defined in classes. They have exactly the same syntax, but it is also possible in traits to define required methods without the keyword abstract. If a method is defined like a normal method without a body (or implementation), the Umple compiler will consider that as a required method.
Provided methods: These are defined in the same way as concrete methods are defined in classes. Indeed, they have exactly the same syntax and semantics. Provided methods also support multiple code blocks, for generation of systems in different languages.
Diagramming: Traits are not part of UML. A UML class diagram drawn from an Umple file containing traits will 'flatten' the traits. Umple can, however, be made to generate a special diagram that shows traits; this can be requested via the Options menu in UmpleOnline and in the generate clause of the compiler.
Use with mixsets: Creating a mixset that defines both a trait and isA statements incorporating the trait into clients allows the specification of optional functionality that can be mixed in to several classes. This is how mixins work in languages such as Ruby.
Elements copied into client classes: The trait elements will appear in all classes that include that trait. In the first example below, the name and address attribute will appear in the class diagram of both Person and Company
The example 2 below shows a trait called TEquality. It has a required methods named isEqual and a provided method named isNotEqual. The provided methods uses the required method to satisfy part of its functionality.
When exploring the following examples in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods.
/*
Example 1: use of a trait in Umple
The trait has regular attributes, derived
attribute and a method that are copied into
Organization and Company
To see different diagram views in UmpleOnline:
Use control-g for auto-layout
(if not already showing)
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
*/
trait Identifiable {
firstName;
lastName;
address;
phoneNumber;
fullName = {firstName + " " + lastName}
Boolean isLongName() { return lastName.length() > 1;}
}
class Person {
isA Identifiable;
}
class Organization {
Integer registrationNumber;
}
class Company {
isA Organization, Identifiable;
}
// @@@skipcppcompile
Load the above code into UmpleOnline
/*
Example 2: showing a trait designed for
comparison regarding if two objects are equal
or not.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout
(if not already showing)
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
*/
trait TEquality{
Boolean isEqual(Object object);
Boolean isNotEqual(Object object){
return isEqual(object) ? true : false;
}
}
// @@@skipcompile Java code not compilable no class
Load the above code into UmpleOnline
Traits are used by clients (classes and traits) by specifying the keyword 'isA' followed by their names and a semi-colon. Traits cannot use themselves (even through several uses in a cyclic manner). When clients specify names of traits for use, those traits must exist in the system. If a trait uses more than one trait, it can separate them by comma or use the keyword 'isA' for each one.
In the example 1 below, trait T2 is a client that uses trait T1 (at line 11) and class C2 is a client that uses trait T2 (at line 21). Clients can use other traits if they satisfy their required methods. Satisfaction of required methods is performed by having them implemented in clients. For example, trait T2 uses trait T1 and so it is required to have the required methods of trait T1 implemented in trait T2 (or in clients of trait T2). Trait T2 achieves this through implementing two methods named method1() and method2() defined in lines 13 and 14.
Trait T2 is not a final client, therefore, it could use trait T1 without implementing those required methods, in that case, the required methods of trait T2 would be method1(), method2(), and method 3(). Class C2, which is a final client, uses trait T2 and therefore needs to implement the remaining required method method3(). However, there is no direct implementation for it. Instead, class C2 obtains such an implementation indirectly from its superclass, which is C1. Therefore, it satisfies the required method of trait T2.
When clients use traits, they obtain all provided methods defined in the traits. This includes all other provided methods those traits might obtain from their own used traits. For example, trait T2 gets the provided method method4() from trait T1. This provided method can be called by all other provided methods defined in trait T2. Therefore trait T2 provides three provided methods named method1(), method2(), and method4(). Class C2 uses trait T2 and so it obtains all provided methods.
Note that it is allowed for abstract classes to use traits without satisfying their required methods. Such required methods are then considered as abstract methods of the abstract class. Then, all concrete subclasses of the abstract class are required to implement those abstract methods. This process ensures that required methods will finally be implemented. It is worth noting that interfaces cannot use traits because they cannot have concrete methods in their definitions.
When exploring the following example in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods.
/*
Example 1: showing how traits can be used by
their clients.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout
(if not already showing)
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
*/
trait T1{
abstract void method1();
abstract void method2();
void method4() Java {/*implementation*/ }
void method4() Python { ''' implementation ''' }
}
trait T2{
isA T1;
void method3();
void method1() Java {/*implementation*/ }
void method2() Java {/*implementation*/ }
void method1() Python { ''' implementation ''' }
void method2() Python { ''' implementation ''' }
}
class C1{
void method3() Java {/*implementation*/ }
void method3() Python { ''' implementation ''' }
}
class C2{
isA C1;
isA T2;
void method2() Java {/*implementation*/ }
void method2() Python { ''' implementation ''' }
}
Load the above code into UmpleOnline
Attributes in traits are defined in the same way they are defined for classes. Traits also support all modifiers that can be applied to attributes. The example 1 below shows the way attributes can be defined and used in traits.
As seen, there is a trait named Identifiable that has five attributes: first-Name, lastName, address, phoneNumber, and fullName. It also has a provided method named isLongName(). There are no required methods because the trait offers pure functionality to its clients. Class Person uses trait Identifiable and obtains the provided method and defined attributes from the trait. Class Company also uses the trait Identifiable and extends class Organization. It obtains both attributes coming from its superclass and used trait. All attributes are flattened similar to the way provided methods are flattened.
When clients use traits, a name conflict might happen because a client might have an attribute and obtains a new attribute with the same name from a trait. Modelers are responsible to resolve the conflict. The conflict is detected automatically. Unlike conflicts with other elements in traits, in the current implementation of our work, there is no operator to resolve an attribute name clash conflict. Our current recommendation is to change the name of attributes in the clients of traits and avoid changing names in traits because this could break other clients of those traits.
Another way to avoid conflicts is to use stateless traits. In that case, traits use required methods to have access to states (attributes). The example 2 below shows trait T1 uses two required methods getData() and setData(Integer) to have access and write to the attribute data of type Integer. It also has a provided method that uses the method getData() to obtain the value of the attribute data. Then, it performs some operation on it (in this case adding 2 to the value,) and finally uses the method setData(Integer) to save the new value into the attribute data. The class C1 uses trait T1 and has the attribute data. Since Umple automatically generates accessor and mutators for attributes, they satisfy the required methods defined in trait T1 and so there is no need to implement them manually in class C1.
When exploring the following examples in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods. (NOTE: on some browsers, these keyboard shortcuts may do other things that override umple. For instance, control-R reloads tabs in some browsers, which may take precedence over umple's built in keyboard commands)
/*
Example 1: use of a trait in Umple
The trait has regular attributes, derived
attribute and a method that are copied into
Organization and Company
To see different diagram views in UmpleOnline:
Use control-g for auto-layout
(if not already showing)
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
*/
trait Identifiable {
firstName;
lastName;
address;
phoneNumber;
fullName = {firstName + " " + lastName}
Boolean isLongName() { return lastName.length() > 1;}
}
class Person {
isA Identifiable;
}
class Organization {
Integer registrationNumber;
}
class Company {
isA Organization, Identifiable;
}
// @@@skipcppcompile
Load the above code into UmpleOnline
/*
Example 2: showing how states in traits can be
obtained by required methods.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout
(if not already showing)
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
*/
trait T1{
int getData();
int processData() {
int data = getData();
data=data+2;
setData(data);
return(data);
}
}
class C1{
Integer data;
isA T1;
}
// @@@skipjavacompile @@@skipphpcompile @@@skippythoncompile Java code not compile
Load the above code into UmpleOnline
Template parameters at the modeling level are combined with other modeling elements like associations. This combination increases modularity and reusability to an extent that is not achievable at the implementation level. Template parameters can be referred to in required and provided methods and attributes. Traits can have template parameters with generic or primitive data types. The difference in their use is that it is possible to put restrictions on bound types of generically-typed parameters. Such, restrictions might include a declaration that the interfaces or classes must be extended or implemented by other specific classes. These restrictions are only available for generic-type parameters because primitive types cannot implement or extend any other types and so there is no way of imposing such constraints on them.
Template parameters are defined after the name of a traits inside a pair of angle brackets. Each parameter has a name and they are separated by a comma. Restrictions on the templates applied in the same manner Umple allows extending and implementing interfaces and classes respectively. In other words, the keyword 'isA' is used after the name of a template parameter followed by the name of interfaces or a class. If there are more than one interface or one interface and one class they are separated by the symbol '&'.
When clients use traits, they must bind types to their parameters and also types must satisfy their restrictions. Values are bound through the symbol '=', in the manner values are generally assigned to attributes. The bindings are performed inside a pair of angle brackets, each one separated by a comma. Therefore, when a client uses a trait with template parameters, they need to extend the normal way of using traits by having angle brackets appearing after the name of traits.
The example 1 below shows how template parameters can be defined and used. It depicts a trait called T1 (line 4) with one template parameter named TP. The template parameter is restricted to implement the interface I1, defined in line 8. The restriction is applied to make sure a correct type will be bound to the template parameter. Trait T1 has a required method named method2() with a return and a parameter of type TP (which is a template parameter). Furthermore, it has a provided method named method3() with a parameter of type TP.
Class C1 defined in line 11 uses trait T1 and assigns class C1 as a binding type to TP. Since class C1 has already implemented interface I1 (line 12), the type is acceptable. Class C1 needs to implement the required method of trait T1, but it must be performed based on the type assigned to the template parameter TP. Therefore, class C1 implements method2() with the correct data type (which is C1) for the parameter and return types. Line 15 shows the exact signature of the implemented method. In the same manner, the provided method obtained is also adapted based on the binding value. The same process is adopted for class C2, but it binds C2 to the parameter TP and so the required method method2() needs to be implemented with type C2. The provided method obtained is based on type C2. There is a method called method1() for classes C1 and C2 that implement interface I1. They have the same signature but different implementations.
Since a trait can use other traits, a trait with template parameters can use other traits with template parameters. Therefore, traits can bind a template parameter to another template parameter to achieve better flexibility. This is performed in the same manner a type is bound to a template parameter. Furthermore, template parameters are modulated for each trait so it is possible for a trait with template parameters to use other traits with the same names for their template parameters.
The example 2 below shows how one template parameter is bound to another one. Trait T1 has the template parameter TP used to define the type of parameter for the provided method method2(). Trait T2 has the template parameter TP used to define the type of parameter for the provided method method3(). It also uses trait T1 and binds its own template parameter to traits T1’s template parameter (line 9). Note that trait T2 can also bind any other types to the template parameter TP, if it is required. Finally, class C1 uses trait T2 and binds String to the template parameter TP (line 13)
Umple introduces a special syntax to allow having template parameters that can be substituted in code blocks. For template parameters to operate on code in code blocks, they need to be encompassed within a pair of the symbol '#'. This ensures that the dedicated Umple scanner (i.e. not a full code parser) will be able to detect strings matching the template parameters correctly and replace them with binding values.
The example 3 shows how a template parameter is used in the body of a method. As seen, trait T1 has a template parameter named TP (line 4). The provided method method2() needs to return a string which is a combination of calling the required method method1() and a method named process() from the template parameter TP. In the body of the provided method method2(), an instance of the template parameter needs to be created so as to call the method process(). This is achieved by having the name of template parameter encompassed by '#' in places that require types (line 7). The rest needs to follow the syntax of the language used to implement the code blocks, in this case, Java. Class C2 uses trait T1 and binds class C1 to the template parameter TP (line 15). It also implements the required method method1() in order to able to use the trait.
When exploring the following examples in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods.
/*
Example 1: showing how template parameters in
traits are defined and used.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout
(if not already showing)
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
*/
trait T1< TP isA I1 > {
abstract TP method2(TP data);
String method3(TP data){ /*implementation*/ }
}
interface I1{
void method1();
}
class C1{
isA I1;
isA T1<TP = C1>;
void method1(){/*implementation*/}
C1 method2(C1 data){ /*implementation*/ }
}
class C2{
isA I1;
isA T1< TP = C2 >;
void method1(){/*implementation*/}
C2 method2(C2 data){ /*implementation*/ }
}
// @@@skipcompile issue needs raising missing return statement
Load the above code into UmpleOnline
/*
Example 2: showing how one template parameter
in a trait is bound to another one.
*/
trait T1<TP>{
void method1();
void method2(TP data) Java {/*implementation*/}
void method2(TP data) Python {''' implementation '''}
}
trait T2<TP>{
isA T1< TP = TP >;
void method3(TP Data) Java {/*implementation*/}
void method3(TP Data) Python {'''implementation'''}
}
class C1{
isA T2< TP = String >;
void method1() Java {/*implementation*/}
void method1() Python {'''implementation'''}
}
Load the above code into UmpleOnline
/*
Example 3: showing how template parameters in
traits are used in code blocks.
*/
trait T1 <TP>{
String method1();
String method2(){
#TP# instance = new #TP#();
return method1() +":"+instance.process();
}
}
class C1{
String process(){/*implementation*/}
}
class C2{
isA T1< TP = C1 >;
String method1(){/*implementation*/ }
}
// @@@skipcompile issue needs raising as Java
// compile fails missing return statement
Load the above code into UmpleOnline
An association is a useful mechanism to specify relationships among instances of classifiers. An association implies the presence of certain variables and provided methods in both associated classifiers.
Associations in traits are defined in the same way they are defined for classes. Traits can make associations with interfaces, classes, and template parameters. If one end of the association is a template parameter, the binding type must be checked to make sure it is compatible with the type of the association. For example, if a trait has a bidirectional association with a template parameter, the binding value cannot be an interface and it must be a class. This is an extra constraint applied to template parameters.
When an association is defined, APIs (set of methods) are generated in the class to allow such actions as adding, deleting and querying links of associations. Traits may use these APIs inside provided methods to achieve their needed implementation. The first example below depicts a simple version of the observer pattern implemented based on traits. As can be seen in line 7, the concept of the subject in the observer pattern has been implemented as trait Subject, which gets its observer as a template parameter. A direct association has been defined in trait Subject (Line 8), which has a multiplicity of zero or one on the Subject side and zero or many on the Observer side. This association lets each subject have many observers and it also applies the case in which observers do not need to know the subject. The trait has encapsulated the association between the subject and observers and then applies it to proper elements when it is used by a client.
As each subject must have a notification mechanism to let observers know about changes, there is a provided method notifyObservers() for this. This method obtains access to all observers through the association. Two classes Dashboard and Sensor play the roles of observer and subject. Class Dashboard has a method named update(Sensor) (line 2) used by the future subject to update it. Class Sensor obtains the feature of being a subject through using trait Subject and binding Dashboard to parameter Observer
The second example below is a concrete example of the use of traits to incorporate functionality (in this case dated addresses) that is needed in otherwise unrelated classes (Persons and Businesses). The third examples shows the use of traits that have associations along with other features of Umple.
When exploring the following examples in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods.
/*
Example 1: implementing observable pattern
with traits and associations.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout
(if not already showing)
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
*/
class Dashboard{
void update (Sensor sensor) Java { /* code */ }
void update (Sensor sensor) Python { ''' code ''' }
}
class Sensor{
isA Subject< Observer = Dashboard >;
}
trait Subject <Observer>{
0..1 -> * Observer;
void notifyObservers() Java { /* code */ }
void notifyObservers() Python { ''' code ''' }
}
Load the above code into UmpleOnline
class Address { street; city; postalCode; country; }
trait EntityWithValidityPeriod {
Date startDate; Date endDate;
}
trait PurposedEntity {
purpose; // e.g. home, work, mobile
}
class DatedAddress {
isA EntityWithValidityPeriod, PurposedEntity, Address;
}
class DatedPhoneNumber {
isA EntityWithValidityPeriod, PurposedEntity;
number;
}
trait LocatableEntity {
0..1 -> 1..* DatedAddress;
0..1 -> 1..* DatedPhoneNumber;
}
class Person { isA LocatableEntity;}
class Business { isA LocatableEntity;}
Load the above code into UmpleOnline
interface I1 {
void m1();
}
trait SuperT {
isA I1;
mixset f5 {e;}
void m1() {
System.out.println("impl of m1");
}
}
trait T1 {
isA SuperT;
Integer c;
Integer d;
mixset f6 {[c > d]}
after setC {
System.out.println("SetC has happened from T1");
}
mixset f1 {1 -- 1..* C4;}
}
trait T2 {
after setC {
System.out.println("setC has happened from T2");
}
}
trait T3 {
void m2() {
System.out.println("M2 is executing");
}
sm1 {
s1 {
e -> s2;
}
s2 {
}
}
}
trait T4 {
isA T3;
}
class C1 {
isA T1, I1;
mixset f1 {1 -- * C3;}
}
mixset f5 class C2 {
mixset f4 {1 -- 1..* C3;}
isA C1, T2;
void m1() {
System.out.println("Overriding impl of m1");
}
}
class C3 {
}
mixset f4 class C4 {
isA T4;
// Commented code bellow will cause an error when mixset f4 is used even when mixset f5 is not used.
// This because inline mixsets does not support apsect.
//mixset f5 after custom m2() {System.out.println("m2 occurred");}
mixset f5 { after custom m2() {System.out.println("m2 occurred");} }
after e1 {System.out.printlin("event e1 occurred");}
}
Load the above code into UmpleOnline
A required interface is an interface that a trait declares that it (or its clients) implement using the isA clause. A required interface groups together several required methods. The following two paragraphs explain this in more depth.
Required functionality of classic traits is defined in terms of required methods. However, there are shortcomings to just listing the required methods. The first shortcoming is that there is no way to reuse a list of required methods. For example, consider a case in which there are several traits that happen to have the same set of required methods but different provided methods. In this case, there is duplication due to repeated listing of the same methods. Furthermore, if there are several traits that must always have the same list of required methods, an inconsistency could be introduced in the design by changing just one of them and not all.
A required interface also allows putting a restriction on a trait's clients that specifies the interfaces they must implement. Such a restriction ensures that traits are not used in clients that just happen to have methods with the same signature.
So using required interfaces, traits can either put extra restrictions on clients (i.e. interfaces the clients must implement) or just manage their required methods in a more modular and reusable way. Traits may use already-existing interfaces or new interfaces may be written to accomplish the desired modularization. Furthermore, developers can create a hierarchy of interfaces to optimize the reusability.
Traits define their required interfaces through the keyword 'isA' followed by the name of interfaces and a semi-colon. When a class uses traits, it needs to implement the required interfaces of those traits. If a trait uses other traits with required interfaces, those required interfaces are added to the set of required interfaces of the trait, and final clients are required to implement all of those required interfaces.
The example 1 below shows how required interfaces are used and applied. There is a hierarchical design for required methods in terms of interfaces, making it reusable and consistent. Traits T1 and T2 have the same required interface (lines 14 and 18) and if there is a modification in the required interface it will be applied to both. Classes C1 and C2 have to implement interfaces I1 (Line 29) and I2 (line 32) to be able to use trait T1 and T2.
When exploring the following example in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods.
/*
Example 1: showing how required interfaces
in traits are defined and used.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout
(if not already showing)
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
*/
interface I1{
void method1();
double method2();
}
interface I2 {
isA I1;
Boolean method3();
}
trait T1{
isA I1;
Float method3(){/*implementation*/ }
}
trait T2{
isA I1;
Float method4(){/*implementation*/ }
}
trait T3{
isA T1,T2;
}
class C3{
void method1(){/*implementation*/ }
Double method2(){/*implementation*/ }
}
class C1{
isA C3, I1, T1;
}
class C2 {
isA C3, I2, T3;
Boolean method3(){/*implementation*/ }
}
// @@@skipcompile Java code not compilable
Load the above code into UmpleOnline
A trait can have zero or many state machines, each with a unique name. The definition of state machines in traits follows the same rules and constraints that exist for them in classes.
The first example shows a trait called T1 (lines 4-13) with two state machines sm1 (lines 5-8) and sm2 (lines 9-12). Use of trait T1 in class C1 results in class C1 having those two state machines as native state machines. In general, if a class already has state machines with completely distinct names to those being introduced via traits, the introduced state machines are just ‘flattened’ into the class, i.e. they are treated as though they were coded directly in the class.
Introduced machines that have names duplicating existing state machine names are composed (merged) with the existing machines, and the resulting composed machines are flattened into the class. The same concept is applied when traits are used by other traits. The second example below expresses the same model designed in example 1, in which class C1 has two state machines, but it uses trait T2 (line 18) to obtain the same state machine. Trait T2 provides state machine sm2 from its own definition (lines 12-15) and state machine sm1 from trait T1 (line 11). This use of traits by other traits allows building more complex traits (and hence more complex state machines) from simpler ones.
State machines in traits are considered as provided functionality. More concretely, any event in a state machine is considered as a provided method, and so can satisfy the required methods of used traits. State machines are supposed to encapsulate their own actions and guards so they can be reused as a piece of functionality. For example, a guard can be defined as a reference to an attribute in the trait or to a parameter of the event, so when the state machine is reused the attribute and parameter are reused as well. The same perspective is true for actions. In real world cases, state machines may need to obtain those conditions and actions from the context (e.g. clients) in which they are reused. State machines hence require those conditions and actions to behave correctly. This requirement is in alignment with the notion of required methods of traits. Therefore, required actions and guards of state machines can be expressed as required methods of traits. Indeed, if events of state machines are considered as provided methods and their guards and actions are considered as required methods, then state machines can define functional behavior and therefore the required behavior of them can again be satisfied by other state machines in the clients. It should be noted that if guards, actions, and activities of state machines are defined as methods (not inline code blocks directly in the state machine), they are not anymore required methods. They will be treated as provided methods, and traits’ rules related to provided methods will be applied to them
The third example below shows how required methods are satisfied by events of state machines. As seen, trait T1 has two required methods, m1(String) and m2(), called in actions of transitions e1(string) and e2 in states s1 and s2 of state machine sm1 respectively. Class C1 uses trait T1 and must satisfy those required methods. Class C1 does not have any concrete method to satisfy the required methods, but it has state machine sm2. State machine sm2 has two event m1(String) and m2 which satisfy the required methods of trait T1. If state machines are used to satisfy the required methods, there is a limitation in return types of required methods. All required methods must have Boolean as their return types, otherwise, events cannot satisfy them. The reason for this limitation is that all event automatically obtain Boolean as their return types by the Umple compiler.
Like the way template parameters defined in traits are used for required and provided methods, they can also be used in collaboration with state machines. Template parameters can be used to define the types of parameters for events. They can also be used in code blocks related to actions and activities. The example 4 illustrates how template parameters can be used with events of state machines. State machine sm in trait T1 has two events. Event e1 has a parameter of type TP (line 6) and event e2 has two parameters with types TP and String (line 7). Class C2 uses trait T1 (line 12) and binds class C1 to the template parameters TP.
The final example below shows how two classes can reuse the same state machine using a trait. This functionality is equivalent to that achieved using standalone state machines.
When exploring the following examples in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods; or control-S and control-G to alternate between state and class diagrams.
When exploring the following examples in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods.
/*
Example 1: showing how state machines are
defined and used in traits.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout as a class diagram
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
Use control-s to show the resulting state diagram
*/
trait T1 {
sm1{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
sm2{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
}
class C1 {
isA T1;
}
Load the above code into UmpleOnline
/*
Example 2: showing how state machines
are defined through different traits.
*/
trait T1 {
sm1{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
}
trait T2 {
isA T1;
sm2{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
}
class C1 {
isA T2;
}
Load the above code into UmpleOnline
/*
Example 3:showing how required methods
of traits are satisfied by events of
state machines.
*/
trait T1{
Boolean m1(String input);
Boolean m2();
sm1{
s1{ e1(String data) -> /{ m1(data); } s2; }
s2{ e2 -> /{ m2(); } s1; }
}
}
class C1{
isA T1;
sm2{
s1{ m1(String str) -> s2;}
s2{ m2 -> s1;}
}
}
Load the above code into UmpleOnline
/*
Example 4: showing how template parameters
in traits are used inside state machines.
*/
trait T1<TP>{
sm{
s1{ e1(TP p1)-> s2; }
s2{ e2(String p1, TP p2) -> s1; }
}
}
class C1{/*implementation*/}
class C2{
isA T1<TP=C1>;
}
Load the above code into UmpleOnline
// Class Diagram illustrating use of a trait
// to incorporate the same state machine in multiple
// classes. This is an alternative to using
// standalone state machines (see an equivalent model
// in the state machine section of the manual)
/*
To see different diagram views in UmpleOnline:
Use control-g for auto-layout as a class diagram
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-s to show the resulting state diagram
*/
class MotorController {
isA DeviceWithStatus;
}
class BrakeController {
isA DeviceWithStatus;
}
trait DeviceWithStatus {
deviceStatus {
inactive {
activate -> booting;
}
booting {
completedStartupChecks -> active;
startupCriticalErrorDetected -> outOfOrder;
}
active {
runtimeCriticalErrorDetected -> outOfOrder;
deactivate -> shuttingDown;
}
shuttingDown {
shutdownComplete -> inactive;
}
outOfOrder {
repaired -> inactive;
}
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
Operators are capabilities that allow resolving the conflicts and also managing the granularity of traits. Operators are applied to traits when traits are used by clients. Clients can apply more than one operator to a specific trait, but those operators need to be compatible with each other. There is no sequence in the way operators are applied. Operators are defined inside angle brackets after the name of traits and can be mixed with binding types to template parameters. The general structure by which a client uses operators is as follows:
TName specifies the name of a trait to which each Operatori,i=1..n is applied. There is no limitation on the number of operations that can be applied to a trait. Two operators with the same functionality can only be applied to different elements. Errors resulting from violations of this are detected and reported to the modeler. Note that all processes related to the flattening and composition algorithm are performed after applying the operators.
If traits have template parameters and those template parameters have been used as types in provided methods (or event of state machines), their types do not affect the signature of provided methods referred to by operators. In other words, types of template parameters are applied to traits after operators are applied. The identification factor for selecting a provided method is its signature. However, the return type of provided methods is not used for identification because the name and list of types of parameters can uniquely differentiate each provided method from others. When parameters of provided methods are specified, there is no need to define the name of parameters
Removing/keeping provided methodsThis operator allows removing or keeping provided methods of a trait. The syntax for this operator is as follows:
The symbol – indicates removing while the symbol + indicates keeping. The symbol must precede the signature of the provided method. When the symbol – is applied to a provided method of a trait, it removes the method from the set of provided methods. However, when the symbol + is applied to a provided method of a trait, the provided method is kept and the rest are removed. Please consider that multiple keeping operators can be used together to keep several methods and throw away the rest.
The example 1 below shows how class C1 removes the provided methods method2() and method3() (line 12) while class C2 keeps the provided method method5(), coming from trait T1 (line 16). As seen, class C1 obtains two provided methods method4() and method5() in addition to the method1() which satisfies the required methods of trait T1. Class C2 just has the provided method method5() in addition to method1().
Renaming (Aliasing)The renaming operator allows changing the name of provided methods and also their visibilities. This operator can also be mixed partially with the keeping operator to provide better flexibility. The operator does not allow changing the types of parameters or number of parameters. The reason is that the provided methods might be used by other provided methods and so any change regarding types and numbers can break traits. The current implementation of the operator does not support renaming recursive methods. The syntax for this operator is as follows:
The example 2 shows this operator in action. Class C1 uses trait T1 (line 12) and renames its provided method method1() to function2. There is no need to specify parentheses for the new name. Class C2 uses trait T1 (line 16) and while it renames provided method3() to function3, it also changes the visibility of the provided method to be private. Finally, class C3 uses trait T1 and renames the provided method method5(Integer) to function5. However, it also forces other provided methods of trait T1 to be removed. This feature can be really useful if there is a utility trait and we are just interested in a provided method with the name that suits our domain.
When exploring the following examples in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods.
/*
Example 1: showing how the operator
"Removing/keeping provided methods" works.
*/
trait T1{
abstract method1();
void method2() Java {/*implementation*/}
void method3() Java {/*implementation*/}
void method4() Java {/*implementation*/}
void method5() Java {/*implementation*/}
void method1() Python { '''implementation''' }
void method2() Python { '''implementation''' }
void method3() Python { '''implementation''' }
void method4() Python { '''implementation''' }
void method5() Python { '''implementation''' }
}
class C1{
isA T1<-method2() , -method3()>;
void method1() Java {/*implementation for C1*/}
void method1() Python {'''implementation for C1*'''}
}
class C2{
isA T1<+method5()>;
void method1() Java {/*implementation for C2*/}
void method1() Python {'''implementation for C2'''}
}
Load the above code into UmpleOnline
/*
Example 2: showing how the operator
"Renaming (Aliasing) provided methods" works.
*/
trait T1{
abstract method1();
void method2() Java {/*implementation*/}
void method3() Java {/*implementation*/}
void method4() Java {/*implementation*/}
void method5(Integer data) Java {/* implementation*/}
void method2() Python {'''implementation'''}
void method3() Python {'''implementation'''}
void method4() Python {'''implementation'''}
void method5(Integer data) Python {'''implementation'''}
}
class C1{
isA T1< method2() as function2 >;
void method1() Java {/*implementation related to C1*/}
void method1() Python {'''implementation related to C1'''}
}
class C2{
isA T1< method3() as private function3 >;
void method1() Java {/*implementation related to C2*/}
void method1() Python {'''implementation related to C2'''}
}
class C3{
isA T1< +method5(Integer) as function5 >;
void method1() Java {/*implementation related to C3*/}
void method1() Python {'''implementation related to C3'''}
}
Load the above code into UmpleOnline
As with operators on methods, certain operators can be applied to traits’ state machines when they are used in clients . These provide mechanisms to improve flexibility, assign state machines to specific states, and resolve conflicts caused by name collisions. These operators follow the same structure defined for operators on methods.
Changing the name of a state machineThis operator is used to change the name of a state machine when it is to be reused by a client. This operator can also be mixed partially with the keeping operator to provide better flexibility. The syntax for this operator is as follow:
When a state machine with a given name is specified by the renaming operator, it must be available in the trait being operated on, either directly in the trait or another trait used by the trait. The example 1 shows how names of state machines in trait T1 can be changed to mach1 and mach2. As seen, in example 1 both state machines that are available directly in trait T1 have been renamed. The example 2 shows how class C1 uses the operator to rename the state machine sm1 in trait T1 and also automatically remove other state machines, which are just state machine sm2 in this case.
There are two main scenarios for this operator. The first is merging: when a client already has a state machine and will obtain another state machine coming from the used trait. The two machines might have some of the same states but different functionality. The client wants to have all functionality merged in one state machine (described as we progress). In this case, the operator is used to change the name of the incoming state machine from the trait, to match the name of the existing state machine. The result is that the new functionality will be merged into the existing state machine. The second scenario is for avoiding conflicts. This occurs when a client has an existing state machine and wants to incorporate another one with different functionality, but that happens to have the same name. In this case, the client can change the name of the incoming state machine to be different from the existing state machine. This second scenario can be needed in various conflict-resolution scenarios
Changing the Name of a StateThis operator changes the name of a state inside a specific state machine. The operator covers both simple and composite states. The syntax used for this purpose is as follows:
The state to be renamed is specified based on a series of names separated by dots, starting with the name of the state machine. If the state is a simple or composite state at the top level of a hierarchical state machine, then it comes directly after the name of the state machine. However, if it is deeper in the hierarchy, the chain of parents must also be specified. The last name in the series is always the name of the state to be renamed. In example 3, trait T1 has a state machine with a composite state named s0 (line 6). Composite state s0 has two internal states s11 and s12. Class C1 uses trait T1 and changes the name of state s0 to state0 and the name of s11 to state11 (line 15). In order to specify the state s0, it is preceded by the name of a state machine, which is sm. For state s11, the name of the state machine, the composite state, and the region name precede it. In Umple, the name of the single region inside a composite state is set automatically to the name of the composite state. The operator applies also the same rule when it changes a composite state.
The first scenario for this operator is to change the vocabulary used for the names of states. This adds flexibility when a trait is specified in a generalized context and there is a need to adapt names so as to be more domain-specific. E.g. ‘tripEnded’ in a general transportation state machine becomes ‘landed’ in an adaptation to the airline domain, or ‘docked’ in an adaptation to the water transport domain. The second scenario is when two states need to be merged, but they have different names. By changing the name of one so it matches the other, then the algorithm knows to merge them. The third scenario occurs when there are two states in a state machine to be composed, but we want to keep those two states separate and prevent merging.
Changing the name of regionsThis operator allows renaming a specified region, an orthogonal part of a composite state or state machine. It is just like the operator used for changing the name of states. The difference is that the last name in the sequential series of names (separated by dots) is the name of a region to be changed. Since names of regions are set automatically by the Umple compiler and they are equal to the names of their initial states, renaming the name of a region must also be applied to its initial state. This is performed automatically by the operator. The applications for this operator are like those for changing the name of states. In particular, this operator is used when several regions are supposed to be merged or kept separate.
Change the name of eventsThis operator is used to change the name of events that will trigger transitions in state machines. The syntax used for this operator is as follows:
Through this operator, it is possible to rename an event related to a specific state machine or all state machines in a trait. For the first case, the modeler specifies the name of the state machine (stateMachineName). For the second case, an asterisk (*) is specified. The event name (eventName) must end with a pair of parentheses including any needed argument types. This operator does not allow changing the argument types because that would break the implementation of the event method. The operator is used mostly to change the event names based on a new domain’s requirements. It can also be used to keep an event from being overwritten by the client’s state machine and vice versa.
In example 4, trait T1 has two state machines sm1 and sm2. These state machines have common events named e1(Integer) and e0(). Class C1 want to use trait T1 with some changes in the name of events. It is required to rename all event names e0() to event0() and just change the event name e1(Integer) to event1() in state machine s1. Line 15 depicts how class C1 achieves it. Since the change on event e0() is going to happen in both the state machines, the symbol * has been used. However, the name of state machine sm1 was used for the event e1(Integer) because we do not want to have it changed in state machine sm2.
When exploring the following examples in UmpleOnline, you can use the Options menu to control what is visible, or you can use control-R to flip back and forth between showing the diagram with the original traits, vs. the diagram collapsed into the classes to be compiled; or you can use control-M to show/hide methods; or control-S and control-G to alternate between state and class diagrams.
/*
Example 1: showing how the operator
"Changing the name of a state machine" works.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout as a class diagram
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
Use control-s to show the resulting state diagram
*/
trait T1 {
sm1{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
sm2{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
}
class C1 {
isA T1<sm1 as mach1, sm2 as mach2>;
}
Load the above code into UmpleOnline
/*
Example 2: showing how the operator
"Changing the name of a state machine" works.
*/
trait T1 {
sm1{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
sm2{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
}
class C1 {
isA T1<+sm1 as mach1>;
}
Load the above code into UmpleOnline
/*
Example 3: showing how the operator
"Changing the name of a state" works.
*/
trait T1 {
sm{
s0{
e1-> s1;
s11{ e12-> s12; }
s12{ e11-> s11; }
}
s1{ e0-> s1; }
}
}
class C1 {
isA T1<sm.s0 as state0, sm.s0.s0.s11 as state11>;
}
// @@@skipcppcompile
Load the above code into UmpleOnline
/*
Example 4: showing how the operator
"Change the name of events" works.
*/
trait T1 {
sm1{
s0 {e1(Integer index)-> s1;}
s1 {e0-> s0;}
}
sm2{
t0 {e1(Integer index)-> t1;}
t1 {e0-> t0;}
}
}
class C1 {
isA T1<sm1.e1(Integer) as event1,
*.e0() as event0>;
}
Load the above code into UmpleOnline
As with operators on methods, certain operators can be applied to traits’ state machines when they are used in clients. These provide mechanisms to improve flexibility, assign state machines to specific states, and resolve conflicts caused by name collisions. These operators follow the same structure defined for operators on methods.
Removing/keeping a state machineThis operator is used to remove or keep a state machine when a client uses a trait. In the removing mode, specified by the minus symbol '-', the indicated state machine is ignored and is not included in the client. In the keeping mode, specified by '+', only the indicated state machine is kept and the others are ignored. This operator can be used to keep the client free of unneeded detail or conflict. The syntax used for this operator is as follows:
In example 5, trait T1 has three state machines sm1, sm2, and sm3. Classes C1 requires state machine sm2 and sm3 while class C2 requires just state machine sm2. Class C1 achieves this through removing state machine sm1 from trait T1 (line 16). Class C2 obtains its required state machine through keeping just state machine sm2 (line 19). Classes C2 could also achieve the same result through removing sm1 and sm2. Using the keeping operator is more convenient when there are several state machines and modelers need just one them.
Removing/keeping a stateThis operator is used to remove or keep a simple or composite state when using a state machine in a trait. The syntax for this operator is as follows:
This works much like removing/keeping a state machine, using a minus sign for removing and a plus for keeping. The symbols are followed by the name of the state. In the removing mode, this operation will delete all incoming and outgoing transitions of the state as well. In the keeping mode, the specified state will be kept and the remaining states will be removed. This also includes removing all transitions from other states to the specified state. This mode can be applied to the initial states, but if it is applied to other states, the initial state will not be removed. The operator is helpful for cases in which base state machines do not need the functionality of that specific state, or have the same state and do not want to merge it with the one coming from the reused trait. Another use is when clients use more than one trait and those traits have common state machines and states. These common states might have different functionality and clients might want to keep one version.
In example 6, trait T1 has state machine sm1 (line5). Class C1 uses trait T1 and removes state s2 from the state machine sm1 (line 25). As seen, in addition to the state s2, all outgoing transitions (named e2()) from states s0, s1, and s3 have been removed. The operator also removed incoming transition e3() from state s2 to state s3. Class C2 uses trait T1 and requires just state s1 of state machine sm1. As seen, all other states except s0 have been removed. The reason is that state s0 is the initial state of state machine sm1 and removing it results in non-reachable states. The Umple compiler does not allow this situation. Furthermore, all transitions coming from other states to s1 have been removed (in this case, there is none) except transitions coming from the initial state s0. The operator also removes the outgoing transitions e2() and e3() of state s1 to other states s2 and s3 except the ones going to the initial state (in this case, there is none).
Removing/keeping a regionThis operator is used to remove or keep a region of a state machine. The syntax used for this operator is exactly like the one defined for removing or keeping a state, except the last name in the dot-separated chain specifies the name of the region. This operator is utilized in cases similar to those explained for removing a state. It can also be used to make a composite state a simple state by reducing the number of regions to zero.
In example 7, two classes C1 and C2 uses trait T1 and manipulate its state machine’s regions. State machine sm has a composite state s1 with three regions r1, r2, and r3. Class C1 removes region r1 from the composite state s1 (line 23) while class C2 keeps region r2 (line 26). As seen in both cases, the region name appears after the name of state machine sm and the state s1. We can see since region r1 has been removed in class C1, the incoming transition e2() has also been removed automatically. In class C2, all outgoing transition from region r2 to other regions, including e2() and e4(), have been removed automatically in addition to region r1 and r3.
Removing/keeping a transitionThis operator is used to remove or keep a transition from a state machine. The syntax for this operator is as follows:
A minus symbol is followed by a transition that needs to be removed. A plus symbol is used to pick a transition to keep. A transition is defined by specifying the name of the state machine, states (including regions for nested states), event, and guard. The symbol '?' is not part of the operator and it is there to show which elements are optional. The name of the state machine and states are mandatory. The event name (along with its arguments) depends on the type of transition.
If the transition is 'auto' (immediately taken on entry to the state or upon completion of a do activity) there is no need to specify it, otherwise, it must be specified. If a transition has a guard, it must be specified using the same syntax used when specifying transitions (inside square brackets). However, if a transition is auto and unguarded, it must be defined with an empty guard "[]" and without any event name. Actions and destination states are not part of the definition for this operator because the above definition suffices to uniquely select any transition. The operator is utilized when base state machines do not need a specific transition coming from the used trait. Furthermore, base state machines might want to extend a transition of a state, but it might already have a transition matching the given specification.
In example 8, class C1 uses trait T1 (line 25) and keeps the transition with the event name e2(Integer) from the state machine sm and state s1. Other transitions related to the state s1, which are e3() and e4(), are removed. Since the transition does not have a guard, brackets are not required in the specification of the transition. Class C2 also uses trait T1 (line 28), but it removes the transition with the event name e4() and a guard on the variable cond from the state machine sm and state s1. This case shows how a transition with the event name and guard can be specified. Class C3 uses trait T2, but it removes an auto transition from state s2 with a guard on the variable cond. As seen, no name has been defined in the operator for the event and the guard is just defined inside brackets. Finally, class C4 use the trait T1 (line 34), but it removes an auto transition without a guard. As seen, an empty bracket after the name of the state is used to specify the transition.
/*
Example 5: showing how the operator
"Removing/keeping a state machine" works.
*/
trait T1 {
sm1{
s0 { e0-> s0;}
}
sm2{
t0 { e0-> t0;}
}
sm3{
w0 { e0-> w0;}
}
}
class C1 {
isA T1<-sm1>;
}
class C2 {
isA T1<+sm2>;
}
// @@@skipcppcompile
Load the above code into UmpleOnline
/*
Example 6: showing how the operator
"Removing/keeping a state" works.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout as a class diagram
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
Use control-s to show the resulting state diagram
*/
trait T1 {
sm1{
s0 {
e1-> s1;
e2-> s2;
}
s1 {
e2-> s2;
e3-> s3;
}
s2 {
e3-> s3;
e2-> s2;
}
s3 {
e0-> s0;
e2-> s2;
}
}
}
class C1 {
isA T1<-sm1.s2>;
}
class C2 {
isA T1<+sm1.s1>;
}
// @@@skipcppcompile
Load the above code into UmpleOnline
/*
Example 7: showing how the operator
"Removing/keeping a region" works.
*/
trait T1{
sm {
s1{
r1{ e1-> r11; }
r11{}
||
r2{
e2-> r11;
e3-> r21;
e4-> r31;
}
r21{}
||
r3{e5->r31; }
r31{}
}
}
}
class C1{
isA T1<-sm.s1.r1>;
}
class C2{
isA T1<+sm.s1.r2>;
}
// @@@skipcompile issue needs raising as Java compile fails
Load the above code into UmpleOnline
/*
Example 8: showing how the operator
"Removing/keeping a transition" works.
*/
trait T1{
internal Boolean cond;
sm {
s1{
e2(Integer i)-> s2;
e3[!cond]-> s3;
e4[cond]-> s4;
}
s2{
[cond] -> s3;
[!cond]-> s4;
}
s3{
-> s1;
}
s4{
-> s1;
}
}
}
class C1{
isA T1<+sm.s1.e2(Integer)>;
}
class C2{
isA T1<-sm.s1.e4()[cond]>;
}
class C3{
isA T1<-sm.s2.[cond]>;
}
class C4{
isA T1<-sm.s3.[]>;
}
// @@@skipcppcompile
Load the above code into UmpleOnline
This operator is used to assign a state machine to a specific state inside another state machine, hence turning that state into a composite state. The syntax used for this operator is as follows:
This operator involves two state machines. The srcStateMachineName is found in the trait, and the desStateMachineName is found in the client. The state in the client can be simle or composite. This operator provides a practical mechanism to incrementally compose a state machine from various parts. For example, simple 'on/off' pairs of states with events to toggle between are fairly common and can be injected easily into destination states using this operator. If a composited state is extended with this operator, it will trigger our composition algorithm which. Furthermore, the operator can be used to bring more than one state machine inside a state.
In example 9, class C1 has state machine sm with two states s1 and s2. Trait T1 has state machine sm1. Class C1 needs to have state machine sm1 activated when it is in state s2. Class C1 achieves this by specifying the source state machine and destination state when it uses trait T1 (line 15).
/*
Example 9: showing how the operator
"Extending a state by adding a state machine
to it" works.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout as a class diagram
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
Use control-s to show the resulting state diagram
*/
trait T1{
sm1{
m1{
t2-> m2;
}
m2{
t1-> m1;
}
}
}
class C1{
isA T1<sm1 as sm.s2>;
sm{
s1{
e2-> s2;
}
s2{
e1-> s1;
}
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
In the same way Umple supports mixins to compose classes, traits can also be composed in this way. This means that a trait can be defined in several places or files and when they are used by clients, all elements defined in those separate places will be applied to clients.
The example 1 depicts two definitions for trait T1 (lines 4 and 8). Class C1 uses trait T1 and implement the required method method1() and also obtains two provided methods method2() and method3().
/*
Example 1: showing how traits are combined with
Umple mixins.
To see different diagram views in UmpleOnline:
Use control-g for auto-layout as a class diagram
Use control-r to switch between trait view and
plain classes resulting from applying traits
Use control-m to show/hide methods
*/
trait T1{
void method1();
void method2() Java {/*impl… */ }
void method2() Python {'''impl… ''' }
}
trait T1{
void method3() Python {'''impl… ''' }
}
class C1{
isA T1;
void method1() Python {'''impl… ''' }
}
Load the above code into UmpleOnline
A system modeled with traits can be transformed to a compatible model without traits. This process is called flattening. Traits are flattened to clients when they are used by clients, so it would also be beneficial to be able to instantly switch between a view with traits and a flattened view. This could help modelers to understand how traits are represented in any object-oriented target languages, as well as the implications of the traits to the generated system. Furthermore, flattened model is useful when it is required to understand what provided methods are available in each final client.
In order to achieve this in UmpleOnline, first the menu OPTIONS must be selected. Then, sub menus Graphviz Class and Traits must be selected for DIAGRAM TYPE and SHOW VIEW respectively. In order to switch to the flattened model, modelers simply need to deselect Traits in SHOW VIEW. These two views can also be generated through the Umple command line interface and the Umple Eclipse Plugin.
In order to see the flattened model textually, first the menu TOOLS must be selected. Then, from the drop down named GENERATE select Internal Umple Representation. Finally, click on Generate code to see the result or to download it.
You can request that certain code be run before or after various Umple-defined actions on attributes, associations, and the components of state machines as well as on user-defined methods.
Using 'before' allows you to enforce preconditions, such that the attribute or association will not be set if the precondition is not true. To reject setting a value, add 'return false'.
Code in a setMethod can access the value to be set by prefacing it by 'a' as in the second example or 'an'.
You can add before and after clauses to add code to generated methods of the form getX, setX, addX, removeX, getXs (to get all elements of an association), numberOfXs, indexOfX, where X is the name of the attribute or association. You can also add code before and after the constructor.
See also this example of using aspect-orientation to help interface Umple with existing libraries.
class X
{
a;
whenWasASet;
after setA {
setWhenWasASet(getA() + System.currentTimeMillis());
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
class Person {
name;
before setName {
if (aName != null && aName.length() > 20) { return false; }
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
class Operation {
const Boolean DEBUG=true;
query;
before constructor {
if (aQuery == null)
{
throw new RuntimeException("Please provide a valid query");
}
}
after constructor {
if (DEBUG) { System.out.println("Created " + query); }
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
When creating before and after statements, you can arrange for the code to be injected into certain methods that match a pattern. You can use * as a wildcard, and ! as an exclusion operator. The following examples will both generate the same code.
Another example of pattern matching for code injection can be found on the page on pooled state machines, where the same code is injected into all the event methods matching a certain pattern
You can specify that code should be injected only into generated methods by specifying the word 'generated' after before or after. Similarly you can specify only custom methods using the keyword 'custom'. The keyword 'all' indicates to inject the code into all matching methods.
class Student
{
const Boolean DEBUG = true;
firstName;
lastName;
cityOfBirth;
before get*Name {
if ( DEBUG) { System.out.println("accessing the name"); }
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
class Student
{
const Boolean DEBUG = true;
firstName;
lastName;
cityOfBirth;
before get*,!getCityOfBirth {
if ( DEBUG) { System.out.println("accessing the name"); }
}
}
Load the above code into UmpleOnline
State machine event methods are generated automatically from a state machine. Sometimes a programmer wants to execute some code whenever a given event is processed by a state machine, no matter what state the state machine is in.
Code can be injected before or after any event, as shown in the example below. Note that in the case of queued or pooled state machines, the injected code will only be triggered when the event is actually processed by the state machine (i.e. when it is removed from the queue).
class Car {
queued radio {
on {
radioToggle -> off;
}
off {
radioToggle -> on;
}
}
after radioToggle {soundBeep();}
}
Load the above code into UmpleOnline
Much of the usefulness of code injection is for generated methods, but it is also possible to inject code into custom methods, using the custom keyword.
// This illustrates separate code injection
// for custom and generated methods
// The output will be as follows
// Sound of beep
// Warning
// ... this is injected after the warning
// Sound of beep
// Warning
// ... this is injected after the warning
// Sound of beep
// Warning
// ... this is injected after the warning
//
class Car {
queued radio {
on {
radioToggle -> off;
}
off {
radioToggle -> on;
}
}
after generated radioToggle* {soundBeep();}
void soundBeep() {
System.out.println("Sound of beep");
radioToggleWarning();
}
void radioToggleWarning() {
System.out.println("Warning");
}
after custom radioToggle* {
System.out.println(
" ... this is injected after the warning");
}
public static void main(String[] args) {
Car x = new Car();
x.radioToggle();
x.radioToggle();
x.radioToggle();
}
}
Load the above code into UmpleOnline
Aspects in Umple can also be specified at top level (i.e. outside any classes). In this case, a set of classes in which to inject the code must be specified, within curly brackets. Glob patterns can be used to match a set of classes, where an asterisk is the wildcard character.
after {*} set* { doSomething(); }
class Student1
{
name;
}
class Student2
{
name;
}
class Employer
{
age;
String testFunction() {
return "This is a test function";
}
}
class Student1 {isA X;}
class Student2 {isA X;}
class Employer {isA X;}
trait X {
doSomething() {
System.out.println("Doing something\n");
}
}
Load the above code into UmpleOnline
after {Student*} setName,testFunction { doSomething(); }
class Student1
{
name;
}
class Student2
{
name;
}
class Employer
{
age;
String testFunction() {
return "This is a test function";
}
}
class Student1 {isA X;}
class Student2 {isA X;}
trait X {
doSomething() {
System.out.println("Doing something\n");
}
}
Load the above code into UmpleOnline
An around statement can be used used to inject code around a code block. The original code appears in the middle, wherever the special around_proceed keyword is placed. The first example below surrounds the body of an entire method. The second example injects code between two labels
class AroundClass{
static void doSomeThing()
{
int x; int a;
boolean flag = false;
Label1: x = 0;
Label2: a = 0;
flag = true;
}
}
class AroundClass
{
around custom doSomeThing()
{
// code before around.
if (true)
{
around_proceed:
}
// code after around.
}
}
Load the above code into UmpleOnline
class AroundClass{
static void doSomeThing()
{
boolean flag = false;
Label1: int x = 0;
Label2:
flag = true;
}
}
around {AroundClass} custom Label1-Label2:doSomeThing()
{
// code before around.
if (true)
{
around_proceed:
}
// code after around.
}
Load the above code into UmpleOnline
Mixsets can be used to create different members of the same product line from a given Umple model, or to help divide the system into features for feature-oriented development. They can also be seen as providing conditional compilation capabilities such as those commonly found in C++ or C.
Mixsets are one of several separation-of-concerns capabilities available in Umple. The others being mixins, traits, aspect orientation and filters.
A mixset is a named set of fragments of Umple code that may or may not be included in the system. A mixset is included using a use statement or a command line argument, in the same manner that a .ump file is included. So, taken together the fragments can be seen as a virtual file.
When a use statement (or command line argument) matching the mixset's name is encountered, then the fragments comprising the mixset are mixed in to the Umple code using Umple's mixin mechanism, which allows multiple definitions of an entity such as a class to be combined.
A mixset fragment can be defined in the following ways:
// Initially there are two classes with no attributes
class X {}
class Z {}
// In another place, potentially a separate file.
// class X is given attribute a
// This is a simple mixin
class X {
a;
}
// In a third place we conditionally want to
// include attribute b, perhaps only in certain
// versions of the software.
mixset specialVersion {
class X {
b;
}
}
// To activate the specialVersion mixset we need
// to encounter the following
use specialVersion;
// We can also have another 'fragment' of
// the specialVersion mixset elsewhere
mixset specialVersion {
class X {
c;
}
}
// The following notations can also be used
class X {
mixset specialVersion {d;}
}
// Any features of a class can be incorporated
// using a mixset including the following
// Here we introduce a second mixset
mixset specialVersion2 {
class Z {p;}
}
class X {
mixset specialVersion2 {
isA Z;
0..1 -- * Z;
}
}
use specialVersion2;
// The following mixset will be ignored since
// there is no use statement for it
mixset specialVersion3 {
class W {}
}
Load the above code into UmpleOnline
Umple mixsets can be used to conditionally construct variant versions of methods that enable different members of a product line to behave differently. There are multiple ways this can be done. The simplest way is to add a mixset statement directly into a method, as seen on line 11 of the example below. In this example, the code on line 12 will only be part of the method if the World mixset is activated through a use statement or command line argument.
The second way to use mixsets with methods is to create mixsets that contain Umple aspects that inject code in methods. In the example below, the mixsets starting at lines 19, 27 and 35 all do this.
In Umple, code labels (identifiers followed by a colon) can be used to indicate variation points at multiple points among any method’s statements. These labels can be utilized by aspects to indicate where to inject code into the methods, and can even enable replacing the code between two labels. The injected code has direct access the local scope (i.e. local variables) at the locations where it is injected. When combined with mixsets, aspect injection at labels therefore provides fine grained variability at the statement level. It can be used as an alternative to the approach of using hook methods (empty methods that are called and do nothing by default but can be overridden in subclasses) to provide variability.
The main method in the example below contains three labels: Hello_Label, Beautiful_Label, and Wonderful_Label. They are utilized by the aspects of three mixsets (Hello, Beautiful, and Wonderful) to inject some print statements.
class Main
{
// The method below has three code labels
// plus an inline mixset (line 11).
// These labels act as points of extensions.
void main(String[] arg){
Hello_Label: ;
Beautiful_Label: ;
Wonderful_Label: ;
mixset World {
System.out.print(" world !");
}
}
}
// The following three mixsets inject code
// based on the label specified after "before".
mixset Hello {
class Main
{
before Hello_Label: main(String) {
System.out.print(" Hello ");
}
}
}
mixset Beautiful {
class Main
{
before Beautiful_Label: main(String) {
System.out.print(" beautiful ");
}
}
}
mixset Wonderful {
class Main
{
before Wonderful_Label: main(String) {
System.out.print(" wonderful ");
}
}
}
// use statements activate mixsets.
use Hello;
use Beautiful;
//use Wonderful;
use World;
Load the above code into UmpleOnline
Require statements in Umple are used to specify dependencies and relationships among mixsets.
In the simplest case a require statement simply declares that certain code requires the presence of a certain mixset and that it would be an error if there is no use statement for this mixset. If the require statement is itself in a mixset, then it is stating that mixset requires the presence of one or more others. In the first code example below, the mixset M1 (Line 2) requires mixset M2 (Line 6). Mote that the specification of the required mixset M2 is in square brackets: That is because the argument to the require statement is a Boolean condition involving mixsets with logical connectors
Require statements may include the subfeature keyword to specify mixsets that are features. A require statement containing subfeature forms a parent-child relationship between the source mixset and the target mixset and both will become features.
When a mixset acts as an optional feature; the keyword isFeature can be included in the mixset body instead of using the require statement. The keyword isFeature makes a mixset an optional feature to the container mixset (the one which the former is nested in). If the mixset containing isFeature is a top entity element in an Umple file, the mixset becomes an optional feature to the SPL base.
The second code example below contains multiple features that form a feature model. Line 5 indicates that GSM1800 is required but that GSM1900 is not. Line 9 states that one or both of two sound features is required. Line 18 states that up to one of three resolution features is required (i.e. only at most one). Line 21 contains a use statement that produces a software variant with five features.
// M1 and M2 are mixsets that are not part of the feature model.
mixset M1 {
require [M2];
}
mixset M2 { }
Load the above code into UmpleOnline
// These require statements form a feature model.
require subfeature [GSMProtocol opt Mp3Recording and Playback and AudioFormat opt Camera];
mixset GSMProtocol {
require subfeature [GSM1800 opt GSM1900];
}
mixset AudioFormat {
require subfeature [1..2 of {Mp3,Wav} ];
}
mixset Mp3Recording {
require [Mp3];
}
mixset Camera {
require subfeature [Resolution];
}
mixset Resolution{
require subfeature [0..1 of {Res21MP, Res31MP, Res50MP}];
}
use GSMProtocol, GSM1800, Playback, AudioFormat, Wav;
Load the above code into UmpleOnline
// Because Debug contains isFeature, it is an optional feature to the base SPL.
mixset Debug{
isFeature;
// Because ConsolePrint contains isFeature, it is an optional feature to Debug.
mixset ConsolePrint
{
isFeature;
}
}
Load the above code into UmpleOnline
Traits can include mixsets with their bodies. For example, the code below contains the 'Numerical' mixset, which ensures the implementaion of extra methods (isGreaterThan and isLessThan) when its activited by a use statement.
trait TEquality{
Boolean isEqual(Object object);
Boolean isNotEqual(Object object) Java {
return isEqual(object) ? false : true;
}
mixset Numerical {
Boolean isGreaterThan(Object object);
Boolean isLessThan(Object object);
}
}
class RealNumber
{
float value;
isA TEquality;
Boolean isEqual (Object object)Java
{
if(object instanceof RealNumber)
return this.value == ((RealNumber) object).value;
else
return false;
}
}
/*
The below use statement generates an error in Umple when its activited.
Because the trait TEquality has the Numerical mixset, and there is no
implementaion for its methods (isGreaterThan and isLessThan).
*/
//use Numerical;
Load the above code into UmpleOnline
State machine models can contain variant units by employing mixsets. These can be inline (directly specified within a state macine) or compositional (in a separate file). For example, the mixset “HalfOpenFeature” in the code below captures the state “HalfOpen” and with a transition from "Opening" to the “HalfOpen” state. The second code example shows an equivalent state machine model, but with a compositional mixset.
// This example shows how a state machine model can incorporate inline mixsets.
class GarageDoor
{
status {
Open { buttonOrObstacle -> Closing; }
Closing {
buttonOrObstacle -> Opening;
reachBottom -> Closed;
}
Closed { buttonOrObstacle -> Opening; }
Opening {
// HalfOpenFeature mixset below is an inline mixset.
// It contains an event (a part of the state machine).
mixset HalfOpenFeature {
buttonOrObstacle -> HalfOpen;
}
// end of HalfOpenFeature.
reachTop -> Open;
}
// HalfOpenFeature mixset here contains a state (with its content)
mixset HalfOpenFeature {
HalfOpen { buttonOrObstacle -> Opening; }
}
}
}
// A use statement to activate HalfOpenFeature mixset.
use HalfOpenFeature;
Load the above code into UmpleOnline
class GarageDoor
{
status {
Open { buttonOrObstacle -> Closing; }
Closing {
buttonOrObstacle -> Opening;
reachBottom -> Closed;
}
Closed { buttonOrObstacle -> Opening; }
Opening {
reachTop -> Open;
}
}
}
// The mixset below contains a compostional mixsets.
mixset HalfOpenFeature {
class GarageDoor
{
status {
Opening {
buttonOrObstacle -> HalfOpen;
}
HalfOpen { buttonOrObstacle -> Opening; }
}
}
}
// A use statement to activate HalfOpenFeature mixset.
use HalfOpenFeature;
Load the above code into UmpleOnline
UmpleOnline includes a feature-tree panel (opened from the Show and Hide toolbar) that renders every mixset in the current model as a node in a hierarchical tree. The tree also visualises feature-model constraints (and / or / xor / multiplicity) defined by isFeature and require statements, so parent-child relationships and mutually-exclusive alternatives are shown graphically.
Clicking a node toggles the corresponding use statement and instantly re-generates the diagram for the resulting configuration, giving a single-click way to switch between alternative designs. Nodes whose activation would violate a feature-model constraint are highlighted.
The panel is backed by the FeatureModelJson generator, which exposes the model's feature structure — including a top-level requirements array and per-mixset reqImplementations — as JSON consumed by the browser.
Combined with quality requirements and the quality comparison table, the selector supports design-decision workflows in which several mixsets represent alternative designs and can be switched, compared, and benchmarked without leaving UmpleOnline.
A filter directive in Umple can be used to select only a certain part of a model (i.e. a set of classes including their associations) and ignore the rest. It is particularly designed to allow creation of different diagrams from the same model. However it could also be as a way of building a particular version of the system that only has certain features. It is one of Umple's separation of concerns mechanisms.
There are two types of filter statements, named and unnamed. An unnamed filter statement is active by default, and tells the system to include only certain indicated classes (multiple such filters are shown in the example below). A named filter statement is ignored until activated with an includeFilter statement (the example below shows two named filters appearing after the Filter 7 comment).
Filters can be used to describe a particular diagram (or system version). There can be any number of named filters, but only one unnamed filter should be active at one time.
Within a filter directive, one can specify
Consider wrapping filter statements within mixsets. This will allow you to turn on and off various filters using command line arguments.
Load the example below into UmpleOnline and uncomment any of the filter statements, one at at a time, to see the effect of filtering. The comment just before each filter statement describes the effect. Note that the named filters described as Filter 7 have been left uncommented as they are ignored until the un-named filter following them is activated.
// Example to demonstrate filters. Uncomment one of
// the filters shown below to display a different
// diagram, or generate a different subset of the
// code
// This model describes abstract art consisting of
// various shapes connected in 3-D space, some
// of which can contain others.
// Filter 1. Show only Shape3D
// filter {include Shape3D;}
// Filter 2: Show classes connected to Model3D with
// one hop
// filter {include Model3D; hops {association 1;}}
// Filter 3: Show classes related to qualities
// filter {namespace qualities ;}
// Filter 4: Show Shape3D, its subclasses and all
// their connections
// filter {include Shape3D; hops {sub 1;}}
// Filter 5: Including also includes parents
// filter { include Cube;}
// Filter 6: Show two classes and their neighbours
// filter {include Surface, Model3D; hops {association 1;}}
// Filters 7: Named filters and use of the named filter
filter 7 {include Connector; hops {association 1;}}
filter 7a {include Cube;} // includes its parents
// filter {includeFilter 7,7a;}
// Filters 8: Including classes that are associated
// will always show the associations
// filter { include Colour, SurfaceQuality;}
// Filter 9: Use of patterns
//filter { include M????3D,*Polyhedron;}
// Filter 10: Excluding those that start with P (except superclasses)
// filter { include ~P*;}
class Point3D {
Double x;
Double y;
Double z;
}
class Model3D {
depend Qualities.*;
depend Shapes.*;
name;
1 -- * Shape3D;
1 -- * Connector;
}
namespace Qualities;
class Colour {
Integer red;
Integer green;
Integer blue;
}
class SurfaceQuality {
* -> 1 Colour;
Float reflectance;
Float transparency;
}
namespace Shapes;
// Shape3Ds are nodes, they can also contain other
// Models inside themselves.
class Shape3D {
// All surfaces, points, connections
// are relative to the centre which acts
// as the Shapes origin.
// The centre also positions the shape in 3-space.
* -> 1 Point3D centre;
// An Internal 3D model appears inside a Shape3D
// All points are relative to the shape's centre
0..1 containingShape -<@> 0..1 Model3D internalModel;
}
// A surface is used to describe the shape
// of one of the sides of a polyhedron
// points are relative to the centre of the
// polyhedron. The points must fall on some
// 3D plane.
class Surface {
* -> * Point3D;
* -> 1 SurfaceQuality;
}
// Connectors are sticks connecting 3D Shapes
class Connector {
* -> 2 Point3D ends;
* -- 2 Shape3D connectedShapes;
Double radius;
* -- 1 SurfaceQuality;
}
class Sphere {
isA Shape3D;
Double radius;
* -> 1 SurfaceQuality;
}
class Polyhedron {
depend Qualities.*;
isA Shape3D;
1 -- * Surface;
}
class RegularPolyhedron {
isA Polyhedron;
}
class Cube {
isA RegularPolyhedron;
}
strictness ignore 42; // hide namespace warnings
Load the above code into UmpleOnline
Generating string output is a very common task for programs. Common types of output include html, xml and executable code. Umple has a special capability for this, as do many other technogies (it is central to PhP, for example). The advantage of Umple's approach is that it adds generation templates in a uniform manner to C++, Java, PhP and other languages that Umple supports. The same templates can be reused.
The Umple generation templates are essentially a readable way to generate special methods that emit Strings (and also in Java's case StringBuilders).
Two basic elements are needed to use generation templates:
Templates The first essential element is the templates themselves. These are shown as a name followed by arbitrary text in <<! !>> brackets. The text in the brackets can contain anything you want. See the examples below to understand how these are used.
<<!output this!>>
will build the string 'output this' when specified in an emit method (below).
Emit method specifications: The second essential element is one or more 'emit' statements. These specify the methods to be generated. As with any method there can be a set of arbitrary parameters. Following this, in a second set of parameters is comma-separated list of templates to emit. For example, the following says to generate a method with signature String printRow(intTimes, intCount); that will emit a string containing the contents of the row and cr templates:
emit printRow(int times, int count)(row, cr);
Optional elements in templates are:
Expression blocks: Inside the template, programmers can specify arbitrary expressions in <<= >> brackets. These can refer to attributes of the class, parameters to the emit method, states and so on. The result of the expression will be substituted every time the template method is called. This appears in all examples below.
Code blocks: Also inside the template program logic can be embedded in <<# #>> brackets. This enables conditional emission of parts of a template, or looping within the template. This appears in the second example below.
Comment blocks: Comments in templates can be shown within <</* */>>
The first two examples below show how simple templates can be used to output strings, in this case a one-column multiplication table. The first example uses two template methods, the second being called in a loop. The second example generates the same output, but all the looping logic is enclosed in the template itself. The third example shows a more substantial template with a lot of 'boilerplate' text that is easy to read and edit in the Umple source. Manually writing the generated would be substantially more awkward.
Umple's mixin capability allows templates to be kept in separate files. This can faciliatate reuse.
// Simple example to demonstrate umple's template
// base string generation mechanism.
// In this approach there is an iterative call
// to the emit function
class MathExample {
// A simple template to inject a platform
// specific newline
cr <<!
!>>
// Two templates for different lines of output
header <<!Print out a <<=times>> times table!>>
row <<! <<=times>> times <<=count>> is <<=times*count>>!>>
// Specification for two methods to be generated
// to output parts of the text
// Method arguments are in the first parentheses
// Templates to output are in the second set
emit printHeader(int times)(header, cr);
emit printRow(int times, int count)(row, cr);
// Main program to run the above and generate
// the output
public static void main(String[] argv) {
int times = 10; // default
MathExample m = new MathExample();
if(argv.length > 0) {
times=Integer.parseInt(argv[0]);
}
// Print the header
System.out.print(m.printHeader(times));
// Print one row for each element
for (int i=0; i <= times; i++) {
System.out.print(m.printRow(times,i));
}
}
}
Load the above code into UmpleOnline
// Simple example to demonstrate umple's template
// base string generation mechanism.
// In this approach iteration is embedded in the
// rows template and there is a single emitter
// function generated called result
class MathExample {
// A simple template to inject a platform
// specific newline
cr <<!
!>>
// A template for the header lines
header <<!Print out a <<=times>> times table!>>
// A template that generates all the rows by
// iterating
rows <<!<<# for (int i=0; i <= times; i++) {#>>
<<=times>> times <<=i>> is <<=times*i>><<#}#>>!>>
// Specification of a single method to emit
// the result
emit result(int times)(header, rows, cr);
public static void main(String[] argv) {
int times = 10; // default
if(argv.length > 0) {
times=Integer.parseInt(argv[0]);
}
// Output the entire result
System.out.print(
new MathExample().result(times));
}
}
Load the above code into UmpleOnline
// Example of creating a lengthy output in Umple
// from a template. Note this is plain text.
// See the next page for html generation.
// The company is, of course, fictitious.
class RefLetterRequest {
// Attributes used to construct the instance
String fileno; String recipient; String applicant;
String sender; String senderTitle;
// Letter template
letterTemplate <<!
Subject: Reference request for <<=applicant>>, File #<<=fileno>>
Dear <<=recipient>>,
Our company, Umple Enterprises, is hiring talented software
engineers.
We have received an application from <<=applicant>> who named you
as an individual who could provide a letter of reference. Would you
please reply to this letter, answering the following questions:
* In what capacity do you know <<=applicant>>
* For how long have you known <<=applicant>>
* Describe the abilities of <<=applicant>> in software development
* What his or her strengths and weaknesses?
* Please provide your phone number and suitable times to call in
case we need to follow up
Yours sincerely,
<<=sender>>
<<=senderTitle>>
!>>
// Specification of the method to generate
emit letterTemplate()(letterTemplate);
// Main program to generate the letter
public static void main(String[] argv) {
if(argv.length < 5) {
System.err.println("You must specify arguments for fileno, recipient, applicant, sender, sendertitle");
}
// Output the entire result
else System.out.print(new RefLetterRequest(
argv[0], argv[1],argv[2], argv[3], argv[4]
).letterTemplate());
}
}
Load the above code into UmpleOnline
The first example below illustrates the generation template capability of Umple. It is an html generation library. The second example is a program that uses the first example.
// Umple library for generating html
// Currently it supports h1, h2 ... as well as p, and table tags.
// This will be extended to support more of html later
// It serves as an illustration of Umple's generation templates
strictness allow 75; // We are going to allow custom constructors
// Class representing either a top level html node or a collection of subnodes
class HtmlNode {
String getContent() {return "";}; // should be abstract
}
// Simple text to be output between tags - these are leaves
class HtmlTextNode {
isA HtmlNode;
String content;
}
// Non-leaf nodes in the html tree
class HtmlRegularNode {
isA HtmlNode;
const String Xmltagstart = "<";
const String Xmltagend = ">";
// Arguments for the constructor
String tag; // e.g. p, h1, a
String arguments; // e.g. href
0..1 -> * HtmlNode subnodes; // whatever to emit between tags
// The following template will render any html node
rendering <<!<<=Xmltagstart>><<=getTag()>> <<=getArguments()>><<=Xmltagend>>
<<#
for(HtmlNode n : getSubnodes()) {#>><<=n.getContent()>>
<<#}#>><<=Xmltagstart>>/<<=getTag()>><<=Xmltagend>>!>>
emit getContent()(rendering);
HtmlTable table() {
HtmlTable t = new HtmlTable();
addSubnode(t);
return t;
}
HtmlTextNode text(String s) {
HtmlTextNode t = new HtmlTextNode(s);
addSubnode(t);
return(t);
}
HtmlRegularNode taggedText(String tag, String arguments, String s) {
HtmlRegularNode r = new HtmlRegularNode(tag, arguments);
HtmlTextNode t = new HtmlTextNode(s);
r.addSubnode(t);
addSubnode(r);
return(r);
}
}
class HtmlTable {
isA HtmlRegularNode;
HtmlTable() {
super("table","");
}
HtmlRow tr() {
HtmlRow r = new HtmlRow();
addSubnode(r);
return r;
}
}
class HtmlRow {
isA HtmlRegularNode;
HtmlRow() {
super("tr","");
}
// Add a cell that contains text
HtmlCell td(String s) {
HtmlCell c = td();
c.text(s);
return(c);
}
// Add a cell that can contain anything
HtmlCell td() {
HtmlCell c = new HtmlCell();
addSubnode(c);
return c;
}
}
class HtmlCell {
isA HtmlRegularNode;
HtmlCell() {
super("td","");
}
}
class HtmlGen {
lazy HtmlNode firstNode;
// Subtrees for the header and body
0..1 -> * HtmlNode headerNodes;
0..1 -> * HtmlNode bodyNodes;
after constructor {
firstNode = new HtmlTextNode(filehead());
}
filehead <<!<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">!>>
emit filehead()(filehead);
xmlns <<!xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"!>>
emit xmlns()(xmlns);
wholefile <<!<<=getFirstNode().getContent()>>
<html <<=xmlns()>> >
<head>
<<#for(HtmlNode h: getHeaderNodes()) {#>>
<<=h.getContent()>>
<<#}#>>
</head>
<body>
<<#for(HtmlNode h: getBodyNodes()) {#>>
<<=h.getContent()>>
<<#}#>>
</body>
</html>
!>>
emit wholefile()(wholefile);
// Creates a new simple node; but does not add it anywhere
HtmlRegularNode simpleNode(String tag, String content) {
HtmlTextNode t = new HtmlTextNode(content);
HtmlRegularNode r = new HtmlRegularNode(tag,"");
r.addSubnode(t);
return r;
}
// Add a top level node of any type that contains a string
HtmlNode addNode(HtmlNode n) {
addBodyNode(n);
return n;
}
// Add a node of any type that contains a string
HtmlRegularNode addSimpleNode(String tag, String text) {
HtmlRegularNode t = simpleNode(tag,text);
addBodyNode(t);
return t;
}
// Adds a top level header at a certain level with plain text
// Subsequent calls can be made to add additional elements
// to the result
HtmlRegularNode h(int level, String text) {
return addSimpleNode("h"+level,text);
}
// Adds a top level p with plain text
// Subsequent calls can add additional elements to the p
// beyond just the text
HtmlRegularNode p(String text) {
return addSimpleNode("p",text);
}
// Adds a top level table
HtmlTable table() {
HtmlTable t = new HtmlTable();
addBodyNode(t);
return t;
}
}
Load the above code into UmpleOnline
// Umple program demonstrating generation
// of the html generation library for Umple
use ../HtmlGeneration.ump;
class TimesTable {
public static void main(String[] argv) {
int times = 10; // default
HtmlGen h = new HtmlGen();
HtmlRegularNode p;
if(argv.length > 0) {
times=Integer.parseInt(argv[0]);
}
// Specify the table main header
h.h(1, "Multiplication Table: "+times);
// Generate an explanatory paragraph
p = h.p("The following is a ");
p.taggedText("i","","simple");
p.text(" multiplication table");
// Generate another paragraph with some subnodes
// showing a slightly different use of the API
p = new HtmlRegularNode("p","");
h.addNode(p);
p.text("Nodes in ");
p.taggedText("font", "color=\"red\"", "red");
p.text(" are powers of 3");
h.h(2, "The table");
// Create a table at the top level
HtmlTable t=h.table();
// Add the top row of the table
HtmlRow r;
r=t.tr();
r.td("*");
for(int i=1; i<= times; i++) {
r.td().taggedText("b","",""+i);;
}
// Add the interior rows of the table
for(int i=1; i<= times; i++) {
r=t.tr();
r.td().taggedText("b","",""+i);
for(int j=1; j<= times; j++) {
String output=""+i*j;
if((i*j)%3==0) {
HtmlCell c = r.td();
c.taggedText("font", "color=\"red\"",output);
}
else {
r.td(output);
}
}
}
System.out.println(h.wholefile());
}
}
Load the above code into UmpleOnline
An active object is an object that, when constructed, runs its own thread. This is indicated in Umple by the 'active' keyword followed by a block of code. A collection of active objects, working together, constitute a concurrent system.
Additional Umple features are under development to allow for sending signals to and from concurrent objects.
class A {
name;
active {
System.out.println("Object "+getName()+"is now active");
for (int i = 1; i < 10; i++) {
System.out.println(" "+name+" was here");
Thread.sleep(1000);
}
}
public static void main(String[] argv) {
new A("1");
new A("2");
}
}
Load the above code into UmpleOnline
Multiple concurrent blocks that become active when in a particular state can be accomplished in Umple using a state machine with two substates separated by the || symbol, each with a do activity. Both do activities will run concurrently.
class X {
activesm {
topstate {
thread1 {
do {
System.out.println(
"Doing the activity - Normally "+
"this would last a long time");
Thread.sleep(1000);
System.out.println("Done thread 1");
}
}
||
thread2 {
do {
System.out.println(
"Doing the other activity - Again "+
"this would last a long time");
Thread.sleep(3000);
System.out.println("Done thread 2");
}
}
}
}
public static void main(String[] argv) {
new X();
}
}
Load the above code into UmpleOnline
// This is a more sophisticated example
class X {
sm {
s1 {
do {
System.out.println("In S1");
Thread.sleep(1000);
System.out.println(
"Still in S1 after sleep");
Thread.sleep(2000);
System.out.println(
"About to leave S1");
}
-> s2;
}
s2 {
do {
System.out.println("In S2");
Thread.sleep(1000);
System.out.println(
"Still in S2 after sleep");
Thread.sleep(2000);
System.out.println(
"About to leave S2");
}
nesteds2a {
do {
System.out.println("In S2a");
Thread.sleep(1000);
System.out.println(
"Still in S2a after sleep");
Thread.sleep(2000);
System.out.println(
"About to leave S2a");
}
}
||
nesteds2b {
do {
System.out.println("In S2b");
Thread.sleep(1000);
System.out.println(
"Still in S2b after sleep");
Thread.sleep(2000);
System.out.println(
"About to leave S2b");
}
}
}
}
public static void main(String[] argv) {
System.out.println("In Main");
X theX = new X();
System.out.println("End of Main");
}
}
Load the above code into UmpleOnline
By default, compiling an Umple system will result in set of classes that execute as a single application operating on objects that exist in a single Java virtual machine (VM) on a single computer (node). In this default mode of operation all method calls are made locally to methods in the same running VM.
However, by using the 'distributable' keyword, modelers can instruct the Umple compiler to allow objects to be distributed to multiple running VMs most likely running on different computers (although they can be on the same computer if desired). In this mode, some method calls result in remote invocation of methods in a different VM using either Remote Method Invocation, or Web Services.
To make an Umple model into a distributable one that runs on multiple VMs, the developer needs to perform the following. Each of these steps is described in more detail later.
The developer must first identify which classes are allowed to have objects on multiple machines using the 'distributable' keyword. They must also set a namespace. For example:
namespace example;
class Customer{
distributable;
}
The above need not require modifying the original code as it could be introduced using a mixin. Indeed it is possible in Umple to turn a non-distributed system into a distributed system with a minimum of code change.
The distributable feature is inherited by subclasses. One can also put distributable in an interface (It makes the classes that use this interface distributable). Human and Customer are both distributable in the example below.
class Human{
distributable;
}
class Customer{
isA Human;
}
Objects can be grouped to run on the same machine. These groups are called runtime components. By default, all instances of the same class are grouped together in a runtime component named after the class name. For example all of the objects of the Customer class above would be in the Customer runtime component.
The runtime components are managed by a special class that Umple creates called UmpleRuntime. An instance of UmpleRuntime will exist on each running VM. It is mostly invisible to the program; it is only called by the program in a few special circumstances.
To put a specific instance of a class in a different group, one can name the runtime component of the object as the last parameter of the constructor when creating the instance of the distributable class.
In the example below, "customer1" goes into the runtime component "Customer" by default.
Customer customer1= new Customer ("customer 1");
In the example below, we put "v" in the runtime component "Customer".
Vendor v= new Vendor ("Vendor 1", UmpleRuntime.getComponent("Customer"));
The names of the runtime components can be any alphanumeric word and there is no need to declare them at compile time or in the configuration file. In the example below, we put "v" in the runtime component "Component1" which is not named after any class.
Vendor v= new Vendor ("Vendor 1", UmpleRuntime.getComponent("Component1"));
An Umple program using distributed objects can call methods on an object that happens to exist in another VM. Arguments can also be passed containing objects that are on another VM. Behind the scenes proxy objects are used to make this happen, and method calls use Remote Method Invocation (RMI) by default, or else web services if specified as discussed below.
As mentioned above, the UmpleRuntime class is generated for every distributed system. The instance of UmpleRuntime on each VM is responsible for distributing the objects. It reads a file (by default configuration.txt) to know which VM is where, and which VM and runs which runtime components.
In the configuration file, one declares a machine using curly brackets ({}) and can define specifications of the machine in the brackets (id, ip, url,..) as shown in the example below. One also names the runtime components that the machine runs.
The first example shows a configuration file with four nodes and five runtime components.
{id=0 ip=192.168.2.1 port=10541 {rc1}}
{id=1 ip=192.168.2.2 {rc2, rc3}}
{{Vendor} ip=192.168.2.3 id=2 }
{id=3 ip=192.168.2.4 {Warehouse}}
The next example is a configuration file with two nodes on the same physical machine with different ports to distinguish them.
{id=0 ip=192.168.2.1 port=10541 {rc1}}
{id=1 ip=192.168.2.1 port=10540 {rc2, rc3}}
Finally, the following shows configuration file with all runtime components on the same node
{id=0 url=http://localhost port=10541 {rc1, Vendor, rc2, rc3}}
Once you have generated the code in umpleonline you can download the zip file.
Once you have unzipped the file navigate into the Java directory and create your configuration.txt file.
To compile the code run the following command in the Java directory (in this example the inner folder is named ecommerce):
javac ecommerce/*.java
To run the system, the operator starts Java VMs for as many copies of the system as he or she desired by invoking a main class (a class with a main method). At least one of the started machines must be started using such a main class; other machines can be started by running UmpleRuntime on those machines.
The id of the machine must be communicated to the UmpleRuntime as an argument. The example below shows two different machines being started where the Java code generated by umple is in the ecommerce directory. One VM is started by running a class called Main; this starts the whole system. The other one runs Umpleruntime on machine 1.
On machine 0:
java ecommerce.Main
On machine 1:
java ecommerce.UmpleRuntime 1
Note that the command will display connection refused errors until you have started every node.
It is also possible to change the configuration file's default address:
java ecommerce.UmpleRuntime 1 c:\configFile.txt
The system will not do anything until all of the VMs in the system have started and connected.
The user can change the defaults by calling certain UmpleRuntime static methods from the main method.
UmpleRuntime.setThisNodeId(1);
UmpleRuntime.setFileAddress("otherconfigFile.txt");
UmpleRuntime.getInstance();
If a class is declared distributable then all children classes of that parent class are also distributable.
/*
In this example all 3 classes are distributable because Supplier and Vendor both inherent the disributable trait from the Person class.
*/
namespace example;
class Person {
distributable;
}
class Supplier {
String supplierID;
isA Person;
}
class Vendor {
String vendorId;
isA Person;
}
Load the above code into UmpleOnline
In a distributed system, a singleton class could mean two different semantics. One is that the class
has only one instance on each node. The other semantic is to assume that there is only one instance
of the object in the whole system. The developer can choose which semantic to be used for the
singleton class. If a singleton class is also distributable, it means there should be only one instance of
the class in the whole system and remotely accessible by other nodes. Otherwise, there can be one
instance on every node.
The target runtime
component of the singleton object is the name of the class by default. All of the getInstance() calls in
the entire system will be redirected to a single object.
SingletonClass.getInstance().getName();
Alternatively, a specific runtime
component can be given as a parameter of the getInstance() method. In this case, there will
be a single object on each node.
SingletonClass.getInstance(UmpleRuntime.getComponent(“component1”)).getName();
All classes can be set to be distributable by using the following directive:
distributable forced;
Alternatively, all classes can be forbidden to be distributable by using the following directive:
distributable off;
One can use Web services instead of RMI by adding ws after distributable keyword in the class:
distributable WS;
Note: Web services is not currently working due to an issue with outdated dependencies.
distributable forced;
namespace example;
class Person {
String name;
}
class School {
String schoolName;
}
Load the above code into UmpleOnline
Below is a more in depth model using the distributed feature that you can load into umple online to visualize and better understand distributed systems.
The following will be put in the configuration.txt file to run the components on 3 separate nodes:
{id=0; port=8081; http://localhost; {component1,Manager}}
{id=1; port=8082; http://localhost; {component2,component4}}
{id=2; port=8083; http://localhost; {component3,SystemTracer}}
/*
The following is an example of how distributed can be used to run a system on multiple nodes with a main class.
Example Taken from
https://ruor.uottawa.ca/bitstream/10393/37143/5/Zakariapour_Amid_2018_thesis.pdf
*/
namespace ecommerceRMI1;
distributable 1 on;
class Warehouse
{
distributable;
}
class Agent
{
distributable;
* -- * Warehouse;
}
class Customer
{
distributable;
public Order orderProduct(String productType,String vendorName)
{
for(Vendor v: getVendors())
{
if(v.getName().equals(vendorName))
return v.makeOrder(self,v.findProduct(new ProductType(productType)));
}
return null;
}
}
class Vendor
{
public Order makeOrder(Customer aCustomer, Product aProduct)
{ if(aProduct==null)
return null;
Order aOrder= new Order(aProduct);
aOrder.setCustomer(aCustomer);
aOrder.setVendor(self);
return aOrder;
}
}
class Main
{
public static void main (String[] args){
Supplier supplier1= new Supplier("supplier1",UmpleRuntime.getComponent("component1"));
Supplier supplier2= new Supplier("supplier2",UmpleRuntime.getComponent("component2"));
Warehouse warehouse1=new Warehouse("warehouse1",UmpleRuntime.getComponent("component2"));
Warehouse warehouse2=new Warehouse("warehouse2",UmpleRuntime.getComponent("component3"));
Vendor vendor1= new Vendor("vendor1",UmpleRuntime.getComponent("component3"));
Vendor vendor2= new Vendor("vendor2",UmpleRuntime.getComponent("component4"));
Customer customer1= new Customer("Customer",UmpleRuntime.getComponent("component5"));
Customer customer2= new Customer("Customer",UmpleRuntime.getComponent("component6"));
customer1.addVendor(vendor1);
customer1.addVendor(vendor2);
customer2.addVendor(vendor2);
vendor1.addWarehous(warehouse1);
vendor2.addWarehous(warehouse1);
vendor2.addWarehous(warehouse2);
supplier1.addWarehous(warehouse1);
supplier2.addWarehous(warehouse2);
supplier1.createBulk("freezer",1000,"0013M2X");
supplier2.createBulk("freezer",1000,"0023M2X");
supplier1.createBulk("microwave",1000,"23M2X");
supplier2.createBulk("microwave",1000,"13M2X");
supplier1.createBulk("stove",1000,"M2X");
supplier2.createBulk("stove",1000,"M3X");
supplier1.createBulk("laptop",1000,"LL3L");
supplier2.createBulk("laptop",1000,"LL4L");
customer1.orderProduct("freezer","vendor1");
customer2.orderProduct("freezer","vendor2");
customer1.orderProduct("stove","vendor1");
customer2.orderProduct("laptop","vendor2");
customer2.orderProduct("laptop","vendor2");
customer1.orderProduct("laptop","vendor2");
UmpleRuntime.stopAll();
}
}
class Warehouse
{
name;
public Product findProduct(ProductType productType)
{
for(ProductTypeInWarehouse ptiw:getProductTypeInWarehouses())
{
if(ptiw.getProductType().equals(productType))
{
for(Product p : ptiw.getProducts())
return p;
}
}
return null;
}
public void addProduct(Product p)
{
for(ProductTypeInWarehouse ptiw : getProductTypeInWarehouses())
{
if(ptiw.getProductType().equals(p.getProductType()))
{
ptiw.addProduct(p);
return;
}
}
ProductTypeInWarehouse ptiw = new ProductTypeInWarehouse(p.getProductType());
ptiw.addProduct(p);
addProductTypeInWarehous(ptiw);
}
}
class Agent
{
name;
}
class Order
{
* -- 0..1 Customer;
* -- 0..1 Vendor;
* -> 1 Product;
}
class Supplier
{
isA Agent;
0..1 -> * Product;
public void createBulk(productType,Integer number,serialNumber)
{
for(int i=0; i<number; i+=1)
{
String postfix=String.valueOf(i);
putInWarehouse(createProduct(serialNumber+postfix,productType),getWarehous(0));
}
}
public Warehouse createWarehouse(name)
{
Warehouse warehouse=new Warehouse(name);
addWarehous(warehouse);
return warehouse;
}
public Product createProduct(serialNumber, String productType)
{
Product aProduct=new Product(serialNumber,new ProductType(productType));
addProduct(aProduct);
return aProduct;
}
public void putInWarehouse(Product aProduct,Warehouse warehouse)
{
warehouse.addProduct(aProduct);
removeProduct(aProduct);
}
}
class Vendor
{ isA Agent;
public Product findProduct(ProductType productType)
{
for(Warehouse w:getWarehouses())
{
Product p= w.findProduct(productType);
if(p!=null)
return p;
}
return null;
}
}
class Product
{
immutable;
serialNumber;
* -> 1 ProductType;
}
class ProductType
{
immutable;
name;
key {name};
}
class ProductTypeInWarehouse
{
* -> 1 ProductType;
* <- 0..1 Warehouse;
0..1 -> * Product;
}
class Customer
{
name;
* -- * Vendor;
}
Load the above code into UmpleOnline
A composite structure diagram is used to show how various instances of classes, called parts, are connected at run time in order to communicate with each other.
To specify composite structure, the following are the elements that need to be present in an Umple system:
The example below first defines two classes with ports; a third class contains instances of the first two.
Under development: Composite structure diagrams, ports and active methods are currently under development. Code generation only works in C++
See also the Wikipedia page on Composite Structure Diagrams.
// Example system representing constraint-based ping-pong example
// Demonstrates the composite Structure Diagram in Umple
class Component1 {
// Relay-Port
public in Integer pIn1;
public out Integer pOut1;
pIn1 -> pOut1;
[pIn1]
active increment {
pOut1(pIn1 + 1);
}
[pOut1]
active logOutPort1 {
cout << "CMP 1 : Out data = " << pOut1 << endl;
}
}
class Component2 {
public in Integer pIn2;
public out Integer pOut2;
pIn2 -> pOut2;
[pIn2, pIn2 < 10]
active stop {
pOut2(pIn2 + 1);
}
[pOut2]
active logOutPort2 {
cout << "CMP 2 : Out data = " << pOut2 << endl;
}
}
class Atomic {
Component1 cmp1;
Component2 cmp2;
Integer startValue;
after constructor {
cmp1->pIn1(startValue);
}
cmp1.pOut1 -> cmp2.pIn2;
cmp2.pOut2 -> cmp1.pIn1;
}
Load the above code into UmpleOnline
Model Oriented Tracing Language (MOTL) allows developers to specify tracing at the model level.
Historically, developers have traced software using various techniques:
However, in software generated from UML, these techniques can only be used effectively on generated code. They require understanding the structure of that generated code; furthermore trace directives need replacing when the code is replaced. Tracing thus occurs at a level of abstraction below the level at which the system is implemented.
MOTL is designed to allow tracing with direct reference to UML model elements (state machines and their states and events, associations and attributes). MOTL specifies how to inject trace code into generated code for UML constructs.
MOTL syntax is designed to be be usable independently of Umple. For example, trace statements could be used to inject tracing into code generated from a UML model specified in Papyrus. The current implementation of MOTL focuses on tracing Umple-generated code. In order to trace a UML model created by an arbitrary UML tool, it is currently necessary to have the model from that tool converted to Umple first.
MOTL can be used to generate tracing directives for different types of tracers. At its simplest level, if the phrase 'tracer Console;' is used (or no tracer statement is included), then trace output is directed to standard error. Generation of tracing for DTrace and LTTNG is under development.
MOTL can be used in two modes:
The following pages describe how to use MOTL. Many aspects of MOTL are under development. Some future pages for tracing features under development cam be found in Umple wiki pages.
Simple tracing is specified using trace directives, which all start with the word 'trace'. This is normally followed by the UML entity to trace (attribute, association, state, etc.).
Beyond, this, other clauses can be added to limit tracing to certain conditions, to switch on or off tracing in certain situations, and to specify data that will be output.
Each 'trace' statement emits exactly one trace record when something occurs to a matching UML entity; by default it is only changes in value that trigger emission of a trace record, but later pages describe how accesses to the value can also be traced. The format of the trace record will depend on the tracer being used but by default will contain the name of the entity and the new value of that entity.
The following are extremely simple example of tracing using MOTL on a UML Integer attribute. The default console tracer is used, so output will be sent to standard error.
@SuppressWarnings("deprecation")
class Student
{
Integer id;
// Whenever the id attribute is changed,
// emit a trace record
// The record will have the format id=value
trace id;
// The following Java main program can be used
// to demonstrate this in operation
// This will output a record when id is set to 9.
public static void main(String [ ] args) {
Student s = new Student(6);
s.setId(9);
}
}
Load the above code into UmpleOnline
@SuppressWarnings("deprecation")
class Student
{
lazy Integer id;
lazy name;
// It is possible to specify multiple
// UML entities to trace as follows
// It is also possible to indicate interesting
// information to record in addition to the
// value of the element being traced
trace id, name record "interesting behavior";
trace id record "Even more interesting";
// Traces will be triggered for each call to a 'set' method
// and twice for id, since there are two trace statements for id
public static void main(String [ ] args) {
Student s = new Student();
s.setId(9);
s.setName("Tim");
}
}
Load the above code into UmpleOnline
MOTL allows the tracing of attributes at the model level. Attribute tracing can occur whenever an attribute value is changed (i.e. setter is called) or/and when the value is accessed (i.e. the getter method is called). Thus, attribute tracing can be made to occur any of the following modes:
// This traces setId() and setName()
@SuppressWarnings("deprecation")
class Student
{
Integer id;
String name;
trace id;
trace set name;
}
Load the above code into UmpleOnline
// This traces getId() method
@SuppressWarnings("deprecation")
class Student
{
Integer id;
trace get id;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
// This example traces getId() and setId()
@SuppressWarnings("deprecation")
class Student
{
Integer id;
trace set,get id;
}
Load the above code into UmpleOnline
State machines are representations of system behaviour. States can have entry or exit actions and do activities; they can also be composite (i.e. nested) or concurrent. MOTL provides modellers with the capability of specifying tracing for all these modelling elements.
@SuppressWarnings("deprecation")
class LightBulb
{
Integer v = 0;
status
{
On {
entry / { setV(1); }
flip -> Off;
}
Off {
entry / { setV(2); }
flip -> On;
}
}
// trace whenever we enter/exit state On
trace On;
// trace whenever we exit state Off and
// report value of attribute v
trace exit Off record v;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
@SuppressWarnings("deprecation")
class LightBulb
{
status
{
On {
flip -> Off;
}
Off {
flip -> On;
}
}
// trace any triggering of event flip
trace flip;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
// this example will trace all states of
// State machine GarageDoor
@SuppressWarnings("deprecation")
class GarageDoor
{
// UML state machine digram for a Garage door,
// written in Umple
status {
Open { buttonOrObstacle -> Closing; }
Closing {
buttonOrObstacle -> Opening;
reachBottom -> Closed;
}
Closed { buttonOrObstacle -> Opening; }
Opening {
buttonOrObstacle -> HalfOpen;
reachTop -> Open;
}
HalfOpen { buttonOrObstacle -> Opening; }
}
// trace whole state machine
trace status;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
Associations describe the relationships between class instances; role names are used to clarify the relation at both ends of an association. MOTL allows the tracing of associations by referring to the role names. Tracing can occur whenever an association link is added or deleted at run time:
// This example will record any addition/removal
// to supervisor assoc link
class Student {
Integer id;
}
@SuppressWarnings("deprecation")
class Professor {
1 -- * Student supervisor;
trace supervisor;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
// This example will record any addition to
// assoc link 'supervisor'
class Student {
Integer id;
}
@SuppressWarnings("deprecation")
class Professor {
1 -- * Student supervisor;
trace add supervisor;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
// This example will record any removal of any
// supervisor assoc link
class Student {
Integer id;
}
@SuppressWarnings("deprecation")
class Professor {
1 -- * Student supervisor;
trace remove supervisor;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
Constraints can be imposed upon the traced UML entity to limit the scope of tracing to when a certain condition is true. MOTL provides a set of constraints that can be classified into a prefix and postfix constraints.
@SuppressWarnings("deprecation")
class Student
{
name;
Integer id;
// trace code is injected in attribute setter
// with specified precondition
trace name where [name == "john"];
// trace code is injected in attribute setter
// with specified postcondition
trace id giving [id > 9000];
// this example traces attribute name whenever
// its value is changed for 5 times
trace name for 5;
}
@SuppressWarnings("deprecation")
class Professor {
name;
1 -- * Student supervisor;
// trace code is injected in attribute setter
// with role name cardinality condition
trace name where [ supervisor cardinality > 10];
}
Load the above code into UmpleOnline
@SuppressWarnings("deprecation")
class Student
{
name;
Integer id;
// trace attribute id and record provided string
// message as part of the trace output
trace id record "i am tracing attribute id";
status {
s1 { e1 -> s2; }
s2 {}
}
// trace whenever we enter/exit state "s1" and
// record attribute name
trace s1 record name;
}
Load the above code into UmpleOnline
@SuppressWarnings("deprecation")
class Student
{
name;
Integer id;
// tracing of attribute name starts and doesn't
// stop until condition becomes true
trace name until [name == "john"];
// tracing of attribute id until condition
// becomes true and then always continue tracing
trace id after [id == 234];
}
Load the above code into UmpleOnline
Tracing non api methods is possible using MOTL. Entry and/or exit of methods can be traced.
// this example shows how to trace
// non-generated method entry
@SuppressWarnings("deprecation")
class JavaMethod
{
trace method();
int method( int x ) {
x += 5;
return x;
}
}
Load the above code into UmpleOnline
// this example shows how to trace generated
// method exit. In case of methods with a return
// statement, trace code is injected before
// the return
@SuppressWarnings("deprecation")
class JavaMethod
{
trace exit method();
int method( int x ) {
x += 5;
return x;
}
}
Load the above code into UmpleOnline
MOTL sets the Console to be its default tracer. However, it provides a set of potential tracers that will have an impact on how tracing is injected and how its collected. Modellers can control the model tracer using a tracer directive.
MOTL tracers can be classified into two main categories: Built in tracers and third party tracers. The main difference between these two categories is that the first category of tracers doesn’t require any additional jars imported into your model generated code, while the later requires jars specific to each tracer.
// this example generates traces using the
// File tracer
tracer File;
@SuppressWarnings("deprecation")
class Student
{
Integer id;
trace id;
}
// The suppressWarnings annotation allows this example
// to keep working as of Java 19 as per Umple issue £2018
Load the above code into UmpleOnline
// this example generates traces using the Java
// native logging API
tracer JavaAPI;
@SuppressWarnings("deprecation")
class Student
{
Integer id;
name;
// trace id with default logging level info
trace id;
// trace name to logging level severe
trace name logLevel severe;
}
Load the above code into UmpleOnline
// this example generates tracespoints using
// the Lttng tracer
tracer Lttng;
class Student
{
Integer id;
trace id;
}
Load the above code into UmpleOnline
// this example generates traces using the
// log4j tracer
// Default log4j xml configuration file is
// generated (log4j2.xml)
tracer log4j;
class Student
{
Integer id;
name;
// trace attribute id with log4j level set to (info)
trace id logLevel info;
// trace attribute id with log4j level set to (error)
trace name logLevel error;
}
Load the above code into UmpleOnline
// this example generates traces using the
// log4j tracer
//
// Customized log4j xml configuration file
// is generated (log4j2.xml)
//
// Root logger level will be debug
//
// Info logging level will be written into
// console output
//
// Error logging level will be written into file
tracer log4j root=debug info = console error = file;
class Student
{
Integer id;
name;
// trace attribute id with log4j level set to (info)
trace id logLevel info;
// trace attribute id with log4j level set to (error)
trace name logLevel error;
}
Load the above code into UmpleOnline
Specifying trace directives at the model level will inject trace points in source code generated from the model. MOTL was designed to collect a wide range of information when tracing is triggered at the execution time.
Collected information includes current system time, thread ID, Object hash code, etc. MOTL tracers will output an initial header to indicate each traced field name.
The following describes how to use the UmpleOnline tool accessible online at try.umple.org
For information about writing Umple models or code in UmpleOnline, look at the Getting Started section of this user manual, or any other topic in the left column of this page, including information about defining classes, attributes, associations and state machines.
Basic use of UmpleOnline
Loading and saving
Left Pane: Umple textual code
Right Pane: UML diagram
This can be an editable class diagram, and The 'E' button at the top-left returns the display to this state as will ctrl-E. The instructions below refer to this format. This can also be a class diagram laid out using Graphviz (G button or ctrl-G), which is the default for many examples, or a state diagram (S button or ctrl-S). To change the Graphviz diagrams, you have to edit Umple textually, or use the gv_manual option in the show and hide menu to drag the diagram to your liking.
Adjusting the panes
Bottom Pane: Errors, Warnings and Generated Results
Shortcuts
Common shortcuts for all computers:
Mac Specific Shortcuts:
Windows/Linux Specific Shortcuts:
See here for the statement regarding privacy and other risks when using UmpleOnline.
UmpleOnline allows you to append various options to its URLi, enabling startup in a certain state. These are preceded by an ampersand, except the first in a list which would be preceded by a question mark.
Using &nochrome¬ext&nomenu&readOnly allows you to embed a pure diagram in a web page. Using &nochrome&nodiagram&nomenu&readOnly allows textual listings in any other web page. Using &nochrome¬ext allows a UML diagram editor to be embedded.
For example, Click here to see a document with an embedded iFrame containing an editor opening on the RoutesAndLocations example. The chrome and text is hidden.
For a read-only version, with ability to generate code, use https://try.umple.org/?example=RoutesAndLocations¬ext&nochrome&readOnly
Umple has a special directive that allows you to highlight certain elements (currently only classes) in UmpleOnline and GraphViz output. Simply write 'displayColor xxx;' in a class where xxx is any html colour such as "red" or "#BBCCFF". UK spelling displayColour also works.
The valid set of colors can be found online at the W3C official site.
The following describes how to set up tasks in UmpleOnline. A task can be an assignment in a course that some students are asked to submit, or an experiment in modeling conducted by a researcher.
This is currently a beta feature. Please raise issues to help us improve it. Some aspects may not work perfectly yet, although it works and can be used in courses. We expect to take this out of beta in late September 2020.
People involved: We refer to the person creating a task (professor, teacher, researcher) as the requestor. We refer to the people doing the tasks (students, research subjects) as responders
Task names: Each task in UmpleOnline has a unique name that can contain alphanumeric characters, underscores and dots. Names are case insensitive and cannot contain spaces or special characters. Requestors should select a meaningful name. For example an assignment in a course at the University of Ottawa could have task name UOtt_2020_SEG2105F.A1 Responders would use this name to find the task or else they can be given a URL to be able to respond to the task (described below).
When setting up a task, the requestor provides the following information:
The requestor's name. This might be their personal name, the name of the course, the name of the institution, or a combination. Responders will see this at the top of their task instructions.
Instructions. These are written in Markdown format. So for example, to make a heading appear in the instructions, start a line with =, or more equals signs for lower-level headings. To make bullet lists start the line with *. To emphasize text in a line use * before and after. Use ``` before and after blocks of code. URLs will generate links to open a page in another browser tab.
It is best to keep instructions relatively short as they take up space on the screen that will be unavailable for modeling, unless the responder asks for them to be hidden. For lengthy instructions, we suggest providing a link to another page. Instructions should include, if appropriate, a request for the responder to include their name and/or ID in the model. UmpleOnline is (at the current time) a login-free system, so responses will be anonymous by default.
An Umple model (optional). The requestor can populate Umpleonline in the normal way (i.e. text and diagram) with a model of any level of sophistication, including one with many tabs (Umple files). Initiating the request with a pre-prepared model can be useful when the instructions are to make improvements, or fix bugs, or add new features. Both requestors and responders have the power to use all the features of UmpleOnline when creating or responding to a request.
If no Umple model is entered, then responders will have to start modeling from scratch, and will be presented with an empty text pane and diagram.
A completion URL (optional) After the responder completes and submits the task, they will be taken to this URL, and the taskname and the URL of the reponse will also be passed to the URL as additional arguments. This could be a URL in a custom tool, or in a survey tool like SurveyMonkey. More detailed explanation for how to do this is in a separate manual page. The completion URL can be used to ask questions in an experiment after the task is done, simply to record the response in a database, or to ask test questions of students.
If no completion URL is given, the responder is returned to their model after submission, but it becomes read-only.
Is the task is an experiment requiring detailed logging? (this feature is still currently under development) The requestor can select a checkbox requesting that detailed logs of every stage of the modeling process be recorded, as performed by each responder. This is most useful for those conducting experiments. Researchers ought to have received ethics approval to run experiments that track data at this level of detail.
Anyone can set up a task. Select the SAVE & LOAD menu in UmpleOnline From there click on Create a Task which appears below the TASK heading.
The task creation pane will appear, allowing the requestor to enter the information described above (requestor name, instructions, model etc.). It is very important at this point to bookmark the URL that appears, or to copy and paste it somewhere safe. For security reasons it will not be possible for the requestor to edit their task or retrieve responses unless they know the randomly-generated URL.
When task preparation is complete, or if the requestor wants to save their work, they select Submit Task
The requestor can continue to edit the task, selecting Save Changes to this Task at any point. Any information can be edited except the task name.
To test the task and see how it will appear to responders, the requestor can select Launch Participant URL in a new tab. Any work done will be recorded as an actual response, unless deleted. Another alternative for testing is to click Copy Participant URL and to paste this into the URL bar of the browser.
There are two ways:
Give the responders the task name and ask them to go to the SAVE & LOAD menu, to select Load a Task and enter the task name.
Give them the URL obtained from selecting Copy Participant URL; clicking on this URL will create a new individual response (a new secret URL) for the person clicking. Note you can't give them the URL that appears from selecting Launch Participant URL in a new tab because that is an individual response from you and you would be giving all participants access to the same response!
Note: If the requestor edits the model of a task after a responder creates a response, the responder will not have access to the revised model. However, responders will have access to revised instructions.
Requestors can distribute the task name or the participant URL via email, a learning management system, or any other means.
This information is in a separate manual page intended for responders. The tool is designed, however, such that responders should not need to access any help. They just read the instructions provided by the requestor, do the task, and submit.
There are a few points responders should be aware of in certain circumstances.
Submissions can be obtained in the following ways. The first two of these will work even before submission.
Additionally, a responder could in some cases want to copy and paste their Umple model (text or diagram) into a separate file, and requestors might ask them to do this in the instructions
If a responder loses the URL of their submission, they might be able to obtain their model by clicking on the 'Restore Saved State' link that appears for a short period when UmpleOnline is relaunched. This does not, however, restore their submission: they would have to create a new submission and copy and paste the retrieved model into it.
It is intended that submissions will persist for a year after they are last edited, but it is recommended that requestors and responders not rely on this, and back up their Umple code somewhere else.
See here for the statement regarding privacy and other risks when using UmpleOnline.
A completion URL is one of the data items that an task requestor can provide when setting up a task in UmpleOnline.
So for example, if the completion URL is https://www.surveymonkey.ca/r/UmpleOnlineDefaultTaskTest, the task name is abc and the responder's submission URL is https://cruise.eecs.uottawa.ca/umpleonline/umple.php?model=task-abc-2008262stdov293 then upon completion the URL https://www.surveymonkey.ca/r/UmpleOnlineDefaultTaskTest?task=abc&url=https://cruise.eecs.uottawa.ca/umpleonline/umple.php?model=task-abc-2008262stdov293 would be submitted.
The above example uses SurveyMonkey as a tool to gather data following submission. Within SurveyMonkey you can create a survey and give it 'custom variables' called 'task' and 'url'. When you save your survey data as individual responses in an Excel file, the task and URL information will appear as columns in the Excel file.
SurveyMonkey is not the only tool that can be used for this purpose. Any tool that can be set up to accept task and url arguments would work. Even a tool that just accepted a URL argument would work.
If you are asked to complete a task in Umple as part of an experiment or a course assignment, the following are some tips you might want to consider.
If you are given a URL to load a task, then just click on it (or copy and paste it). Make sure the URL start with https://cruise.eecs.uottawa.ca/umpleonline, or else is a URL in your own university or company that you trust.
If you are instead given a taskname, you can load the task as follows: Go to UmpleOnline; open up the menu in the center that says SAVE & LOAD; and click on Load a Task. This will display a field where you can type the task name, and then hit Load Task.
After you have loaded the task you will see a set of instructions at the top. These have been set by a task requestor; simply do what the instructions say. Normally this involves writing Umple models. See the rest of this user manual for information about how to do that, including the page about UmpleOnline itself.
If the instructions take up too much space use the relevant buttons to open them in a new window, and hide them from the main UmpleOnline window.
Responses to a task are anonymous unless you explicitly put your name and/or ID in your Umple model. Add your name as a comment in the model if this is a course assignment or if the instructions tell you to.
If this is a class assignment or other work that you might need to do in several steps over several hours, you should save the URL of your individual response. Either bookmark it using your browser, or copy and paste it into another tool like a text editor. This protects against accidentally closing your browser, or your computer crashing. Each person's response to a task has a separate secret URL, and if you lose track of it, it will not be easy to recover it (the requestor might be able to get your work back by looking at all the responses, but it would be a multi-step process for them and they would have to search for a submission that has your name in it)
To submit your work, make sure you are completely finished, and then select Submit Your Work. At this point your work will become read only (you will not be able to make more changes) so don't submit too soon. An alternative way to submit would be to send the URL of your individual response to the requestor; do this if they ask. Note that the requestor is able to see your response even before you submit or if you forget to do so.
If you want to throw away your work before submitting, select Cancel this task response.
A VS Code extension for the Umple modeling language. Provides IDE features for .ump files.
Umple enables textual description of data models (class diagrams) and state models (finite state machines) with embedded code in Java, Python, C++ and other languages, along with generation of high quality code in those languages. Umple enables extensive analysis of models, as well as generation of diagrams, example data and many other outputs. Special features of Umple include specification of product lines (using mixsets), code injection (aspects), code snippet management (traits) and so on. Umple can scale to systems of any size, but its codebase will always be much smaller than software written directly in target languages due to Umple eliminating much boilerplate code. Umple can complement LLM-generation of code: You can arrange for your AI to generate Umple.
This plugin is listed in the VSCode Marketplace
umple-lspuse statement resolution and cross-file diagnosticsuse statement lineumplesync.jar on activation and offers a one-click recovery download if it is missing laterGenerate target language code from Umple source.
Umple: Compile (also accessible from the Umple menu button)Umple: Java) — click to switch. Only visible when editing .ump files.View diagrams (UML and others) generated from your Umple model.
Umple: Show Diagram or Cmd+Shift+U (Ctrl+Shift+U on Windows/Linux)req declarations and useCase blocks; degenerate placeholder for class-only models)umple.diagramLayout setting or the in-panel dropdown)use imports to include referenced filesCode snippets for common Umple patterns. Type the prefix and press Tab:
| Prefix | Description |
|---|---|
class |
Class with attributes |
sm |
State machine skeleton |
assoc |
Inline association |
isa |
Inheritance (isA) |
interface |
Interface block |
trait |
Trait block |
enum |
Enum attribute |
use |
Use (import) statement |
An Umple logo button appears in the editor title bar when editing .ump files. Click it to access:
Install from the VS Code Marketplace, or build from source:
# Side-by-side checkout: this repo currently pins umple-lsp-server to a local # tarball produced by `npm pack` in the umple-lsp monorepo. So you also need # umple-lsp cloned as a sibling. git clone https://github.com/umple/umple-lsp.git git clone https://github.com/umple/umple.vscode.git # Build the server first and pack it cd umple-lsp npm install npm run compile cd packages/server npm pack # produces umple-lsp-server-X.Y.Z.tgz # Then build the extension. package.json's `umple-lsp-server` dep points at # the .tgz path; if you packed a new version, edit package.json to match. cd ../../../umple.vscode npm install npm run compile
To package as .vsix:
npx @vscode/vsce package
Alternative: change the umple-lsp-server dep in package.json from the file: tarball path to a registry version like ^0.4.3, then npm install pulls from npm. Cleaner long-term; requires the matching server version already published.
| Setting | Type | Default | Description |
|---|---|---|---|
umple.autoUpdate |
boolean | true |
Automatically update umplesync.jar on startup |
umple.generateLanguage |
string | "Java" |
Target language for code generation (Java, Php, Ruby, Python, Cpp, RTCpp, Sql) |
umple.diagramLayout |
string | "dot" |
Layout engine for diagram rendering (dot, circo, neato, fdp, osage) |
| Shortcut | Command |
|---|---|
Cmd+Shift+U / Ctrl+Shift+U |
Show Diagram |
To test local changes to the LSP server:
workspace/ ├── umple-lsp/ # LSP server monorepo └── umple.vscode/ # This extension
cd umple-lsp npm install npm run compile
cd umple.vscode npm install npm link ../umple-lsp/packages/server npm run compile
Press F5 in VS Code to launch the Extension Development Host.
After making changes to the server, recompile and reload:
cd umple-lsp npm run compile
Then in the dev host: Cmd+Shift+P (or Ctrl+Shift+P) → Developer: Reload Window
This extension is mostly VS Code glue. Features such as diagnostics, completion, hover, inlay hints, go-to-definition, references, rename, formatting, workspace symbols, code actions, and LSP semantic tokens live in umple-lsp/packages/server.
Inlay hints are handled by VS Code’s standard LSP client. No extension code is needed when the server advertises textDocument/inlayHint; users only need VS Code’s editor.inlayHints.enabled setting to be on.
Formatting is provided by the LSP server. It is conservative: it formats parse-clean Umple structure, parser-visible structural commas, and already split multi-line list indentation. It does not format embedded target-language method or action bodies. Formatter behavior should be changed in umple-lsp/packages/server, not in this VS Code wrapper.
For highlighting:
umple-lsp/packages/tree-sitter-umple/queries/highlights.scm and mapped in umple-lsp/packages/server/src/semanticTokens.ts.highlights.scm and/or semanticTokens.ts in umple-lsp, then rebuild the server and reload the Extension Development Host.Useful checks:
cd umple-lsp npm run compile npm test -w packages/server cd ../umple.vscode npm run compile
In VS Code, run Developer: Inspect Editor Tokens and Scopes to distinguish TextMate scopes from LSP semantic token classifications.
This extension is a thin client that launches the Umple LSP server. The server handles all language intelligence (diagnostics, completion, go-to-definition, references, rename, hover, inlay hints, formatting, workspace symbols, code actions, and semantic tokens). The extension adds VS Code-specific features: compile command, diagram panel, snippets, and UI chrome.
VS Code Extension (this repo)
|
+-- (stdio) --> umple-lsp-server --> umplesync.jar (diagnostics)
| |
| +-- tree-sitter (go-to-def, completion, references,
| rename, hover, formatting, symbols,
| semantic tokens, inlay hints)
|
+-- Compile command --> umplesync.jar -generate <lang>
|
+-- Diagram panel --> umplesync.jar -generate GvClassDiagram/...
| |
| +-- @viz-js/viz (DOT → SVG rendering)
|
+-- Click-to-select --> umple/resolveStateLocation (custom LSP request)
umple/resolveTransitionLocation
Original markdown source for this page: https://github.com/umple/umple.vscode/blob/master/README.md
Umple language support for the Zed editor, providing syntax highlighting, diagnostics, code completion, inlay hints, and go-to-definition for .ump files.
The extension is available on the Zed marketplace. Install it from Zed:
Cmd+Shift+P) and run zed: extensionsThe extension automatically downloads the LSP server and Umple compiler — no manual setup required.
To work on the extension itself, install it as a dev extension:
Clone this repo:
git clone https://github.com/umple/umple.zed.git
In Zed, open the command palette (Cmd+Shift+P) and run zed: install dev extension
Select the umple.zed directory
use statementsuse statement resolution and cross-file diagnosticsFormatting is provided by the LSP server. It formats parse-clean Umple structure, parser-visible structural commas, and already split multi-line list indentation, but intentionally does not format embedded target-language method or action bodies. Formatter behavior belongs in umple-lsp/packages/server; this extension should only handle Zed launch/packaging behavior.
The extension automatically installs umple-lsp-server from npm and downloads umplesync.jar for compiler diagnostics. The server is launched via Node.js in --stdio mode.
You can adjust certain settings using Settings … / Open Settings (cmd ,) or by editing the settings.json file.
By default lines of Umple code that have errors or warnings are underlined; you can see the error or warning at the bottom of the screen if you click on the underlined text.
However, if you would like such messages from the Umple compiler to appear inline (on the line where each problem occurs), then you can change the Languages & Tools / Diagnostics / Enabled setting to be true. You can also do this by adding the following to the settings.json file.
{
"diagnostics": {
"inline": {
"enabled": true
}
}
}
For development, you can override the auto-downloaded server with a local build. Add to your Zed settings.json (Cmd+,):
{
"lsp": {
"umple-lsp": {
"settings": {
"serverPath": "/path/to/umple-lsp"
}
}
}
}
This points to a locally cloned and built umple-lsp repository.
Marketplace install: Zed updates installed extensions automatically. New versions reach you via the Zed Extensions marketplace.
Dev install (from source): pull the latest changes and Zed will pick them up:
cd umple.zed git pull
Then restart Zed or reload the extension.
The LSP server itself is downloaded from npm at every extension load (via npm_package_latest_version("umple-lsp-server")), so server-only changes reach you on the next Zed startup without any extension update needed.
The tree-sitter grammar and query files are derived from umple-lsp. The following files are auto-synced and should not be edited manually:
extension.toml [grammars.umple].rev — pinned commit for parser.clanguages/umple/highlights.scm — copied from umple-lsp/packages/tree-sitter-umple/queries/A GitHub Action in umple/umple-lsp auto-opens (or updates) a PR on this repo whenever grammar or query files change upstream. The PR force-pushes onto a stable branch sync/umple-lsp-master, bumps extension.toml patch version, and includes a body that classifies the change as grammar | highlights | both plus a “safe to merge?” hint. You just merge it.
If the auto-PR workflow is broken or you want to sync ahead of an upstream push:
./scripts/sync-grammar.sh --source /path/to/umple-lsp
./scripts/sync-grammar.sh --source /path/to/umple-lsp --check
This exits with code 1 if any synced file is out of date. The .github/workflows/check-sync.yml workflow in this repo runs this on every push/PR to master to catch drift.
This extension is mainly the Zed wrapper. Core language behavior belongs in umple-lsp:
umple-lsp/packages/serverumple-lsp/packages/tree-sitter-umpleZed’s visible syntax highlighting comes from the synced tree-sitter highlight query at languages/umple/highlights.scm. The LSP server also advertises semantic tokens for clients that use them; those are generated from the upstream highlights.scm and mapped in umple-lsp/packages/server/src/semanticTokens.ts.
When highlighting changes upstream, prefer the sync workflow or run:
./scripts/sync-grammar.sh --source /path/to/umple-lsp --check ./scripts/sync-grammar.sh --source /path/to/umple-lsp
Change this repo directly only when the Zed wrapper behavior changes or when accepting the generated grammar/highlight sync.
Zed compiles extensions to WebAssembly (wasm32-wasip2), which requires the Rust toolchain from rustup. Homebrew’s rust package only includes the native target and can’t cross-compile to WASM.
# Remove Homebrew rust if installed brew uninstall rust brew install rustup # Or install rustup directly via [rustup](https://rustup.rs/)
Check View > Toggle Language Server Logs in Zed for errors. Common issues:
Diagnostics require Java 11+. Check the LSP logs (View > Toggle Language Server Logs) for errors related to umplesync.
MIT
Original markdown source for this page: https://github.com/umple/umple.zed/blob/master/README.md
Umple language support for BBEdit 14+, providing syntax highlighting, diagnostics, code completion, go-to-definition, find references, rename, formatting, and document symbols for .ump files.
BBEdit has built-in Language Server Protocol support — no plugins required.
Two systems work together:
| Responsibility | Provided By |
|---|---|
| Syntax coloring (keywords, comments, strings) | Codeless Language Module (plist) |
| Comment/uncomment commands | Codeless Language Module (plist) |
| Diagnostics, completion, go-to-def, references, rename, formatting, symbols | LSP server (umple-lsp-server) |
BBEdit explicitly does NOT use LSP for syntax highlighting — you need both the plist and the server.
npm install -g umple-lsp-server
Download umplesync.jar (needed for diagnostics):
curl -fSL -o "$(npm root -g)/umple-lsp-server/umplesync.jar" \ https://try.umple.org/scripts/umplesync.jar
The Umple.plist file in this directory is a complete Codeless Language Module that provides both syntax coloring and LSP server auto-discovery. Copy it to BBEdit’s Language Modules folder:
mkdir -p ~/Library/Application\ Support/BBEdit/Language\ Modules cp Umple.plist ~/Library/Application\ Support/BBEdit/Language\ Modules/
Or if you cloned this repo:
mkdir -p ~/Library/Application\ Support/BBEdit/Language\ Modules cp editors/bbedit/Umple.plist ~/Library/Application\ Support/BBEdit/Language\ Modules/
You may need to set the initialization options as specified in Section 5.
Quit BBEdit completely and relaunch. Language modules are only loaded at startup.
.ump filestatemachine sm {} and save the file. Verify that the keyword statemachine is coloured. If not see TroubleshootingThe server automatically finds umplesync.jar next to itself (since v0.2.6). As long as you downloaded the jar into the npm package directory in step 1, diagnostics work with no extra configuration.
If diagnostics still don’t work, you can explicitly point BBEdit to the jar. Find the jar path:
echo "$(npm root -g)/umple-lsp-server/umplesync.jar"
Create a configuration file:
mkdir -p ~/Library/Application\ Support/BBEdit/Language\ Servers/Configuration
Save the following as ~/Library/Application Support/BBEdit/Language Servers/Configuration/Umple.json (adjust the path if your jar is in a different location):
{
"initializationOptions": {
"umpleSyncJarPath": "/usr/local/lib/node_modules/umple-lsp-server/umplesync.jar"
}
}
Then tell BBEdit to use it: Settings > Languages > Custom Settings > double-click Umple > Server tab > set Configuration to Umple.
BBEdit supports C-style comments (//, /* */) in these JSON config files.
//, /* */), and strings ("...") are coloredCmd+/ toggles line comments; Cmd+Shift+/ toggles block comments{ / } blocks can be folded| Feature | How to Use |
|---|---|
| Diagnostics | Errors/warnings appear as colored dots in the line number gutter. Click to see details. When showing details, select Show All to open a window enabling you to navigate all diagnostics |
| Code completion | Type and BBEdit shows completion suggestions from the server |
| Go to Definition | Cmd-double-click a symbol, or right-click > Go to Definition |
| Go to Declaration | Right-click > Go to Declaration |
| Find References | Search > Find References to Selected Symbol |
| Rename | Right-click > Rename Selected Symbol, or Edit > Rename Selected Symbol |
| Document Formatting | Edit > Reformat Document (or Reformat Selection for range formatting) |
| Document Symbols | Go > Go to Named Symbol for quick navigation |
| Workspace Symbols | Go > Find Symbol in Workspace for project-wide search |
| Code Actions | Right-click for context-menu code actions |
| Signature Help | Edit > Show Parameter Help |
textDocument/hoverThe Umple.plist file does two things:
1. Language definition — Maps .ump files to the “Umple” language, defines comment/string delimiters, and provides a keyword list for syntax coloring.
2. LSP auto-discovery — The BBLMLanguageServerInfo dictionary tells BBEdit to automatically launch umple-lsp-server --stdio when .ump files are opened:
<key>BBLMLanguageServerInfo</key>
<dict>
<key>ServerCommand</key>
<string>umple-lsp-server</string>
<key>ServerArguments</key>
<array>
<string>--stdio</string>
</array>
<key>ServerLanguageID</key>
<string>umple</string>
</dict>
This means no manual configuration in Settings > Languages > Server is needed — it’s all automatic from the plist.
The red dot in Settings > Languages > Umple > Server means BBEdit found the configuration but can’t locate the executable.
Common cause: BBEdit reads $PATH from ~/.zshenv, NOT ~/.zshrc. If you installed Node.js via nvm, fnm, or Homebrew and only added it to PATH in .zshrc, BBEdit won’t find it.
Fix options:
Add the PATH export to ~/.zshenv:
# ~/.zshenv export PATH="/opt/homebrew/bin:$PATH" # or for nvm: export NVM_DIR="$HOME/.nvm" [ -s "$NVM_DIR/nvm.sh" ] && . "$NVM_DIR/nvm.sh"
Or use the full absolute path: open Settings > Languages > Umple > Server and set Command to the full path:
which umple-lsp-server # e.g., /opt/homebrew/bin/umple-lsp-server
Or symlink into BBEdit’s Language Servers directory:
mkdir -p ~/Library/Application\ Support/BBEdit/Language\ Servers ln -s "$(which umple-lsp-server)" ~/Library/Application\ Support/BBEdit/Language\ Servers/
Gray means the server is not configured. Make sure Umple.plist is in ~/Library/Application Support/BBEdit/Language Modules/ and you’ve restarted BBEdit.
Ensure umplesync.jar exists:
ls "$(npm root -g)/umple-lsp-server/umplesync.jar"
java -versionIf the jar is in a non-standard location, create Umple.json (see step 5 above)
Check the debug log:
~/Library/Logs/BBEdit/LanguageServerProtocol-Umple.txt
This log shows all JSON-RPC messages between BBEdit and the server.
If BBEdit hangs when closing, the server may not be responding to the exit notification. Fix:
defaults write com.barebones.bbedit ForceQuitLSPServerAfterExit_umple-lsp-server -int 2
This tells BBEdit to force-kill the server after 2 seconds if it doesn’t exit cleanly.
For project-specific settings, place a .BBEditLSPWorkspaceConfig.json file in the project root:
{
// Project-specific LSP settings
}
BBEdit passes this to the server as workspace configuration.
npm update -g umple-lsp-server
Then restart BBEdit. The plist does not need updating unless new keywords are added to the Umple language.
The keyword list in Umple.plist controls which identifiers get syntax coloring. To add or remove keywords, edit the BBLMKeywordList array in the plist and restart BBEdit. The full list of keywords is organized by category:
class, interface, trait, enum, association, associationClass, namespace, statemachineisA, singleton, immutable, abstract, lazy, const, autounique, defaulted, depend, use, keypublic, private, protected, internalInteger, String, Boolean, Double, Float, Date, Time, voidqueued, pooled, entry, exit, do, final, unspecified, as, afterEverybefore, after, aroundgenerate, mixset, require, trace, tracecaseOriginal markdown source for this page: https://github.com/umple/umple-lsp/blob/master/editors/bbedit/README.md
Neovim plugin for the Umple modeling language. Provides diagnostics, code completion, go-to-definition, find references, rename, hover, formatting, and syntax highlighting for .ump files.
cc or gcc) for compiling the tree-sitter parsermacOS (via Homebrew):
brew install neovim node brew install openjdk # optional, for diagnostics
Ubuntu/Debian:
sudo apt install neovim nodejs npm build-essential sudo apt install default-jdk # optional, for diagnostics
If you don’t have a plugin manager yet, follow the lazy.nvim installation guide.
Add this to your lazy.nvim plugin list:
{
'umple/umple.nvim',
build = './scripts/build.sh',
dependencies = {
'neovim/nvim-lspconfig',
'nvim-treesitter/nvim-treesitter',
},
config = function()
require("umple-lsp").setup()
end,
}
The build script downloads the LSP server from npm and fetches the tree-sitter grammar. The tree-sitter parser is compiled automatically on first load — no manual steps needed.
For auto-popup completion, install a completion plugin such as nvim-cmp with cmp-nvim-lsp. Without one, the LSP server still provides completions but you won’t see them automatically.
require("umple-lsp").setup({
on_attach = function(client, bufnr)
-- your custom keybindings
end,
})
Earlier versions of this plugin documented a
port = 5556option (passed to the server asumpleSyncPort). The current LSP server doesn’t read it — diagnostics now spawnumplesync.jaras a subprocess per request, no socket. The option is harmlessly ignored if you set it.
No keybindings are set by default — use on_attach to configure your own. Example:
require("umple-lsp").setup({
on_attach = function(client, bufnr)
local opts = { buffer = bufnr }
vim.keymap.set("n", "gd", vim.lsp.buf.definition, opts)
vim.keymap.set("n", "gr", vim.lsp.buf.references, opts)
vim.keymap.set("n", "K", vim.lsp.buf.hover, opts)
vim.keymap.set("n", "<leader>rn", vim.lsp.buf.rename, opts)
vim.keymap.set("n", "<leader>f", vim.lsp.buf.format, opts)
vim.keymap.set("n", "<leader>e", vim.diagnostic.open_float, opts)
vim.keymap.set("n", "[d", vim.diagnostic.goto_prev, opts)
vim.keymap.set("n", "]d", vim.diagnostic.goto_next, opts)
end,
})
use statements:Telescope lsp_document_symbols or similar)use statement resolution and cross-file diagnostics:Lazy update umple.nvim
This pulls the latest plugin code and re-runs the build script (which updates the LSP server and tree-sitter grammar).
Neovim uses two separate Umple checks:
:InspectTree, and local parse shape. The cached native parser is ~/.local/share/nvim/site/parser/umple.so; query files are linked at ~/.local/share/nvim/site/queries/umple.umplesync.jar. These are the pink/red diagnostics such as E1502.A file can highlight and parse correctly in tree-sitter while still showing an umplesync.jar compiler diagnostic. In that case the LSP is working; the compiler is rejecting the Umple program.
The plugin compiles the tree-sitter parser on first load. If it fails:
cc --version or gcc --versionCheck that the query symlink points to this plugin:
readlink ~/.local/share/nvim/site/queries/umple
Delete the cached parser and restart Neovim to recompile:
rm -f ~/.local/share/nvim/site/parser/umple.so rm -rf ~/.local/share/nvim/site/queries/umple
Diagnostics require Java 11+. Verify: java -version
node --version:LspLog in Neovim to see server errors:Lazy build umple.nvimTo test local changes to the LSP server:
workspace/ ├── umple-lsp/ # LSP server monorepo └── umple.nvim/ # This plugin
cd umple-lsp npm install npm run compile npm run download-jar
{
dir = '/path/to/umple.nvim',
dependencies = {
'neovim/nvim-lspconfig',
'nvim-treesitter/nvim-treesitter',
},
config = function()
require("umple-lsp").setup({
plugin_dir = '/path/to/umple.nvim',
})
end,
}
Then symlink the local server into the plugin’s expected locations:
cd umple.nvim # Symlink tree-sitter grammar ln -sf ../umple-lsp/packages/tree-sitter-umple tree-sitter-umple # Symlink local server into node_modules (jar is already inside packages/server/) mkdir -p node_modules ln -sf ../../umple-lsp/packages/server node_modules/umple-lsp-server
After making changes to the server, recompile and restart:
cd umple-lsp npm run compile # Server-only changes npm run build-grammar # After grammar.js changes (regenerates parser + WASM + compiles)
Then in Neovim: :LspRestart
After grammar changes, also delete the cached native parser so Neovim recompiles it. The plugin repairs stale query symlinks on startup, but deleting the query path is still a useful reset when debugging local setup:
rm -f ~/.local/share/nvim/site/parser/umple.so rm -rf ~/.local/share/nvim/site/queries/umple
The build script installs the pre-compiled umple-lsp-server from npm, downloads umplesync.jar for diagnostics, and extracts the tree-sitter grammar (src/parser.c + queries/) from the umple-lsp repo. The plugin compiles the tree-sitter parser automatically on first load (into ~/.local/share/nvim/site/parser/umple.so), links query files into ~/.local/share/nvim/site/queries/umple, and points Neovim’s LSP client at the npm-installed server.
Original markdown source for this page: https://github.com/umple/umple.nvim/blob/master/README.md
This guide explains how to set up the Umple Language Server with Sublime Text.
From the umple-lsp directory:
npm install npm run compile npm run download-jar
Open Sublime Text and install the LSP package via Package Control: 1. Cmd+Shift+P (or Ctrl+Shift+P on Linux/Windows) 2. Type “Package Control: Install Package” 3. Search for “LSP” and install it
Copy the syntax file to your Sublime Packages/User directory:
cp editors/sublime/Umple.sublime-syntax \ ~/Library/Application\ Support/Sublime\ Text/Packages/User/
Or create Packages/User/Umple.sublime-syntax manually with:
%YAML 1.2
---
name: Umple
file_extensions: [ump]
scope: source.umple
contexts:
main:
- match: '\b(class|interface|trait|enum|association|namespace|use)\b'
scope: keyword.control.umple
- match: '\b(isA|singleton|immutable|abstract|lazy|const)\b'
scope: keyword.other.umple
- match: '\b(Integer|String|Boolean|Double|Float|Date|Time)\b'
scope: storage.type.umple
- match: '//.*$'
scope: comment.line.umple
- match: '/\*'
push: block_comment
- match: '"[^"]*"'
scope: string.quoted.double.umple
block_comment:
- meta_scope: comment.block.umple
- match: '\*/'
pop: true
Open LSP settings: Preferences > Package Settings > LSP > Settings
Add the Umple client configuration:
{
"clients": {
"umple": {
"enabled": true,
"command": ["node", "/path/to/umple-lsp/packages/server/out/server.js", "--stdio"],
"selector": "source.umple",
"initializationOptions": {
"umpleSyncJarPath": "/path/to/umple-lsp/packages/server/umplesync.jar",
"umpleSyncPort": 5558
}
}
}
}
Important: Update /path/to/umple-lsp to your actual installation path.
Close and reopen Sublime Text for all changes to take effect.
If you use Vintage mode, add this to your keybindings (Preferences > Key Bindings) for gd go-to-definition:
[
{
"keys": ["g", "d"],
"command": "lsp_symbol_definition",
"context": [
{ "key": "setting.command_mode", "operand": true }
]
}
]
java -versionTest the server manually:
node "/path/to/umple-lsp/packages/server/out/server.js" --stdio
View > Show Console) for errorsCheck the LSP log panel: Cmd+Shift+P > “LSP: Toggle Log Panel”
.sublime-syntax file is in the Packages/User directory.ump file is openAfter pulling updates:
cd /path/to/umple-lsp npm run compile
Then restart Sublime Text.
Original markdown source for this page: https://github.com/umple/umple-lsp/blob/master/editors/sublime/README.md
This page describes the AI capabilities built in to UmpleOnline. As of early 2026 this is a beta feature.
The AI capability can use various large language models (LLMs) to generate class diagrams and state machines from requirements specified in Umple. Before using this feature you will need to create a set of requirements, or load an example set of requirements, such as one of the examples in this manual.
AI settings dialog. In UmpleOnline, open the AI settings from the AI menu which appears at the bottom of the central menu. When you open this for the first time, click where it says 'Not Configured'
Select a provider. Currently, the supported providers are OpenAI, Google Gemini, and OpenRouter.
Enter API key.
Verify API key. Click the Verify button. The system checks the key's validity with the provider. If verification succeeds, a list of available models is displayed.
Select a model. Choose a model from the dropdown list. Free models are listed at the top, followed by paid models grouped by provider. The cost per million tokens (input and output) is displayed below the selection dropdown.
cached_tokens usage metric), see OpenAI Prompt Caching.req ID { ... }. Learn more about requirements. Open the AI Requirements dialog. If multiple requirements exist, choose to use all or select specific ones. Select a generation type (state machine or class diagram) and click Generate. The result is streamed into the dialog, where you can stop generation, review the output, and insert it into the editor. When enabled, the system runs a compiler-based self-correction loop to repair issues in the generated block before insertion.If AI actions are disabled, ensure you have selected a provider, entered an API key, verified it successfully, and selected a model.
If you see messages such as Rate limited or Provider error, or if you are unsure about keys and OpenRouter integrations, see Help with AI keys.
If no requirements are found, confirm your model contains req ... { ... } blocks.
If a generated block fails to compile, review the error list and re-run generation with fewer or clearer requirements.
This page describes AI agent skills for working with Umple and the Umple CLI (Command line interface). This is in beta and will be enhanced.
A 'skill' is a technology released by Vercel that is gaining acceptance in 2026. The npm skills package is here.
Repository overview
The umple-skills repository (https://github.com/umple/umple-skills or initially here ) provides reusable AI agent skills, scripts, and guidance for working with Umple models and diagrams. This page gives a high-level overview and links to separate sections for each skill.
npx skills add umple/umple-skills to add the skills to your agent environment.scripts/main.ts) invoked by the skill.Skills follow a lazy-loading strategy: only the selected skill folder is loaded at runtime. Semantic routing uses the name and description fields to pick the best skill for a user request.
umple-diagram-generator
references/ folder and relies on the Umple CLI, Graphviz, and Bun.scripts/main.ts.
<output-dir>/
└── <diagram-name>_<timestamp>/
├── model.ump
├── model.gv
└── model.svg.svg path, the script writes only the SVG file to that exact location.
<output-dir>/
└── <diagram>.svgThis page helps you understand how AI keys work in UmpleOnline, and what to do when you see errors such as Provider error or Rate limited.
Important: UmpleOnline uses a BYOK (bring-your-own-key) approach. Your AI key is stored in your browser's local storage and is never sent to Umple servers. Your browser sends requests directly to the AI provider you selected.
1. What does "Verify key" do?
2. Common errors and what they mean
Authentication failed. Please check your API key.
The provider rejected your key. Common causes:
Rate limited (...). Please retry shortly.
This means the provider (or an upstream provider behind OpenRouter) temporarily rejected requests because too many requests are happening in a short time. What to do:
3. Tips for reliable use
The Java generator is the most full-featured of all the Umple code generators.
Java code can be embedded in Umple, and Umple can generate Java from all its modeling features.
Java code can be executed in UmpleOnline if one or more of the classes has a main method. UmpleOnline guards against compile-time and run-time Java errors when executing code. It provides feedback about the relevant line of code where any error occurs.
The Umple compiler itself is written in Umple with embedded Java, and the Java generator is then used to generate the compiler. All Umple features are supported by this generator
The PHP generator supports all class diagramming features of Umple, and generates code that is fully tested.
PHP code can be embedded in Umple, and Umple can generate PHP features such as classes, attributes and associations. This can save a lot of boilerplate programming for systems with complex class structures. The generated PHP code can then be combined with other PHP code written separately.
State machines are not yet fully supported in PHP
The Python generator in Umple allows you to embed Python methods in Umple. Almost everything that can be generated by the Umple Java generator can also be generated by the Umple Python generator. So, for example, your Umple code can be used to create associations and state machines in generated Python.
Embedding Python methods:To insert Python methods in Umple, you specify the method signature followed by the keyword Python followed by an open curly bracket, then any number of lines of Python code, and finally a closing curly bracket.
To create a main Pyhon function in a class use the same method signature as for Java, except tag the code as Python. So a main function first line would look like the following public static void main(String [ ] args) Python { . This would be followed by Python code, and ends with a closing curly bracket }.
Take a look the the last two Hello World examples for some tips. UmpleOnline examples marked with an asterisk already have Python main programs, as well as Java main programs.
Python in UmpleOnline: Python code can be executed in UmpleOnline as of April 2024. To get methods to execute as Python methods, you need to tag them with the keyword Python before the opening curly bracket, as described above. You need at least one main method. When your code is ready, select Python Code from the Generate menu, and then click Execute It. If you make syntax errors or have runtime errors in your embedded Python, UmpleOnline will point you to the line you need to fix.
Command line use: TXL transformation technology is used to convert generated Java to Python.
The Python generator also works on the command line. So you can use Umple to create large and complex systems. However if you are generating Python on the command line you need to install version 10.8b of FreeTXL first. This can also be downloaded from our own server for Linux, Mac or Windows.
After downloading and uncompressing, run the install script.Currently Partially supported features:
Currently unsupported features:
If any of the features that are supported appear to function incorrectly, please submit a new issue here.
The C++ generator is in beta because it has a few bugs in certain aspects. When generating C++ on the command line use the Cpp as the generator name.
C++ code can be embedded in Umple, and Umple is designed to generate C++ from its modeling features.
General Information
It is essential to ensure that your development tools are up-to-date and compatible with the latest standards. For CMake the recommended version is 3.12.xx or later. Please consult the CMake Release Notes for the most current version.
sudo apt install cmake -y in your terminal.brew install cmake.cmake --version in your terminal for Windows Or cmake -version for Linux.-g RTCpp X.ump option to generate C++ code. The file X.ump refer to your umple filemkdir buildcd buildcmake ..make on Linux and MacOS or cmake --build . on Windows. The dot ‘.’ refers to the current directory which is the build directory../executable.\executable.exeThe Ruby generator supports all class diagramming features of Umple, and generates code that is fully tested.
Ruby code can be embedded in Umple, and Umple can generate Ruby features such as classes, attributes and associations. This can save a lot of boilerplate programming for systems with complex class structures. The generated Ruby code can then be combined with other Ruby code written separately.
The Umple developers do not intended to extend the Ruby generator to support state machines, since there are already Gems in Ruby that provide this capability.
Alloy is a formal method notation that can be used check properties of models using logic.
The Umple Alloy generator generates statements that can be used to analyse properties of class models involving associations. Both classes (with their attributes) and associations (with their multiplicity) are turned into sig statements in Alloy.
More information about Alloy can be found at the Alloy project home page, or on the Wikipedia Alloy page.
This generator is discussed in detail in Opeyemi Adesina's PhD thesis: Integrating Formal Methods with Model-Driven Engineering.
NuSMV is a formal method notation that can be used check properties of behaviour models using logic.
The Umple NuSMV generator generates statements that can be used to analyse properties of state machine models.
More information about NuSMV can be found at the Alloy project home page, or on the Wikipedia NuSMV page.
This generator is discussed in detail in Opeyemi Adesina's PhD thesis: Integrating Formal Methods with Model-Driven Engineering.
A composite state table is a state table which, instead of displaying single states and their transitions, displays a combination of multiple concurrent states. They are generated as part of the state table generation.
They can be generated in UmpleOnline through "TOOLS > GENERATE > State Tables" and clicking "Generate It".
They can also be generated through the command-line with "java -jar umple.jar -g StateTables *.ump".
class Student {
status {
ParentState1{
changeParent -> ParentState2;
NonConcurrentSubState1 {
changeNonCon -> NonConcurrentSubState2;
}
NonConcurrentSubState2 {
changeNonCon -> NonConcurrentSubState1;
}
}
ParentState2{
changeParent -> ParentState1;
ConcurrentSubState1 {
change1 -> ConcurrentSubState2;
}
ConcurrentSubState2 {
change1 -> ConcurrentSubState1;
}
||
Css1 {
change2 -> Css2;
}
Css2 {
change2 -> Css1;
}
}
}
}
// @@@skipcppcompile
Load the above code into UmpleOnline
Given a class diagram described in umple the instance diagram generator will create a valid random instance diagram from the class diagram.
Instance names and ids
If the first attribute of a class is a String name then the name of the instance will match the randomly generated attribute value.
If the first attribute of a class is id or ends in Id (case sensitive such as productId and not cupid) the instance name will be className + id.
Suboptions
Possible Errors
Generates a JSON representation of the feature model defined by require statements and mixset features in an Umple file.
Can be invoked using the command line option -g FeatureModelJson or the directive generate FeatureModelJson; in an Umple file.
If the Umple file does not define any feature model, the output will contain {"featureModel":null}.
When the model has an attached UmpleModel with requirements, the output also carries a top-level requirements[] array (sibling of nodes[] and links[]) listing every Requirement. Each entry carries the user-story fields (identifier, language, statement, who, when, what, why) plus nested useCaseSteps[] (with id, stepType, and content) and qualityClasses[] (with name and content). The array is sorted deterministically by identifier so toJSON / fromJSON round-trips remain byte-identical. The requirements key is omitted entirely when no UmpleModel is attached.
Each FeatureLeaf whose mixsetOrFileNode is a Mixset also carries a reqImplementations[] sub-array describing every implementsReq binding owned by that mixset. Each entry records requirementIdentifier, qualityClassName (nullable), implementingFeature (nullable), plus two recomputed-on-serialization booleans requirementResolved and qualityClassResolved that surface whether the parser post-pass successfully bound the entry to its Requirement and QualityClass. The key is emitted only on Mixset leaves — never on UmpleFile leaves nor on FragmentFeatureLeaf nodes.
JSON as a data-interchange format widely used to save and load data in many contexts and languages. It can be used in transmitting over networks. and saving the state of the system persistently.
Umple provides a capability to generate a Json representation of instances of any Umple class, including the complete network of all associated (linked) objects, as well as to reload objects that have been saved. This currently only works with the Java generator for Umple.
To generate functions for serializing and deserializing Json in Umple Java code, specify the suboption "genJson" using the command line or UmpleOnline. A suitable command line would be: umple [FILENAME].ump -g Java -s genJson -c- ... this will generated the needed functions and also compile the code.
When specifying the suboption genJson, all generated Java classes will have the following functions as part of their API:
External tools such as GSON can also be used to serialize and deserialize object data, but these tools do not support circular references. An attempt to save data with circular references in GSON will result in the code crashing with an infinite recursion error. A circular reference occurs when one object points to a second object, and the second object points back (possibly indirectly) to the first. Circular references are inherent in the code generated by Umple bidirectional associations and allow very useful and efficient APIs to be present in generated Umple code. Umple's builtin Json generation handles these circular references in persisted Json data by attaching an umpleObjectID to each saved object. When the date is re-loaded into Umple, these umpleObjectID codes are used to ensure that the circular references are regenerated correctly.
Examples: These demonstrate how use toJson() and fromJson() to serialize and de-serialize Json.
suboption "genJson";
class Bank {
String bankName;
int numAccount;
public static void main(String[] args) Java{
Bank boc=new Bank("BankCanada",100000);
System.out.println(boc.toJson());
}
}
// @@@skipcompile Temporary to bootstrap
Load the above code into UmpleOnline
suboption "genJson";
class University {
singleton;
lazy name;
lazy Float tuition;
1 -- * Course;
}
class Person {
Integer id;
name;
}
class Student {
isA Person;
Float tuitionPaid;
}
class PartTimeStudent {
isA Student;
Boolean isExemptFromFees;
}
class Employee {
isA Person;
Double salary;
lazy job;
* -- * CourseSection teaches;
}
association {
* Student -- 1 University;
}
class Course {
title;
}
class CourseSection {
code;
* -- 1 Course;
}
associationClass Registration {
* Student;
* CourseSection;
lazy grade;
}
class University {
public static void main (String[] args) Java{
University u = new University();
u.setName("UOttawa");
u.setTuition(1000.00f);
Student s1 = new Student(101, "Tim", 800.0f, u);
Student s2 = new Student(102, "Jane", 2000.0f, u);
Student s3 = new Student(103, "Ali", 750.0f, u);
PartTimeStudent s4= new PartTimeStudent(104, "Marie", 600.56f, u, false);
Employee e1 = new Employee(202, "Julia", 6585.45);
Employee e2 = new Employee(203, "Robin", 8785.11);
e2.setJob("Advisor");
Course ca= new Course("Architecture",u);
Course cb= new Course("Biology",u);
CourseSection csa1= new CourseSection("A1",ca);
e1.addTeache(csa1);
CourseSection csa2= new CourseSection("A2",ca);
e1.addTeache(csa1);
CourseSection csb1= new CourseSection("B1",cb);
e2.addTeache(csa1);
e1.addTeache(csa1); // two teachers for this
new Registration(s1,csa1);
new Registration(s1,csb1);
new Registration(s2,csa2);
new Registration(s2,csb1);
new Registration(s2,csa1);
new Registration(s3,csb1);
new Registration(s4,csa2);
String jsonString = u.toJson();
University u2 = University.fromJson(jsonString);
System.out.println("----- fromJson object -------\n"+u2);
System.out.println("----- fromJson ---> toJson ------");
System.out.println(u2.toJson());
}
}
// @@@skipcompile Temporary to bootstrap
Load the above code into UmpleOnline
Umplification involves transforming step by step a base language program to an Umple program; each step is a refactoring. The starting point and the ending point of each transformation will be a system rendered in a textual form combining model elements in the Umple syntax and base language code.
Umplification involves increasing the proportion of modeling elements.
The key insight is that a pure Java program can be seen as a special case of an Umple program. A pure model can also be seen as such a special case. So Umplification involves repeatedly modifying the Umple to add abstractions, while maintaining the semantics of the program, and also maintaining to the greatest extent possible such elements as layout, algorithmic methods and comments.
Two main features differentiate Umple from existing reverse engineering techniques.
To start, source files with language L (e.g. Java, C++) code are initially renamed as Umple files, with extension .ump.
Then, iteratively, small transformations are performed that gradually add UML abstractions. Each iteration should involve testing to check that the program’s semantics are preserved.
Umplification can be performed automatically by a reverse engineering technology that can parse a program in any native programming language and extract the Umple model from it.
The Umplificator is a reverse engineering tool for the incremental automatic detection of opportunities for refactorings and model transformations in source code consisting of Umple or an Umple base language such as Java.
To transform a program written in Java into Umple you can use one of the following tools:
This example shows some of the techniques that can be used when writing Umple code that will be connected to code written separately, such as code in a GUI library. Use of the:
/*
This example demonstrates an example of using the
internal, depends, external, before and after
keywords to interface umple code to code in
another system.
The internal keyword is suitable for situations
where the developer doesn't want setter/getters
to be generated. GUI windows are an example of
such a case. A GUI window/unit contains several
components but the rest of the program may only
need the value stored within those components. So
it's a good practice to hide UI components from
classes other than the containing one.
*/
// required to make HelloInternals class a JFrame
external JFrame{}
class HelloInternals {
// HelloInternals extends JFrame
isA JFrame;
// importing required classes
depend javax.swing.JFrame;
depend javax.swing.JLabel;
/* messageLabel is a component of the frame;
often we don't want sub-components of a GUI unit
to be settable/gettable. By making them internal
Umple will avoid generating setter/getter for
messageLabel. Using lazy Umple will avoid adding
a constructor parameter for this component */
lazy internal JLabel messageLabel;
// the contents of messageLabel
String message;
/* before getting the message, this code updates
the message attribute using the text from
messageLabel */
before getMessage {
message=messageLabel.getText();
}
/* after setting the messae, this code updates
messageLabel to contain the newly updated
message */
after setMessage {
messageLabel.setText(message);
}
// using after constructor is a good way of
// initiating a GUI unit
after constructor {
getContentPane().setLayout(null);
messageLabel=new JLabel(message);
messageLabel.setBounds(10, 10, 200, 20);
add(messageLabel);
pack();
setSize(250, 200);
}
}
Load the above code into UmpleOnline
// 2D Shapes class hierarchy - sample UML class
// diagram in Umple
// From Book by Lethbridge and Laganiere, McGraw Hill 2004
// Object-Oriented Software Engineering:
// Practical Software Engineering using UML and Java
// See https://www.site.uottawa.ca/school/research/lloseng/
//Namespace for core of the system.
namespace Shapes.core;
class Shape2D {
center;
}
//Abstract
class EllipticalShape {
isA Shape2D;
semiMajorAxis;
}
//Abstract
class Polygon {
isA Shape2D;
}
class Circle {
isA EllipticalShape;
}
class Ellipse{
isA EllipticalShape;
}
class SimplePolygon {
orientation;
isA Polygon;
}
class ArbitraryPolygon {
points;
isA Polygon;
}
class Rectangle {
isA SimplePolygon;
height;
width;
}
class RegularPolygon {
numPoints;
radius;
isA SimplePolygon;
}
class Shape2D {
public static void main(String [] argc) Java {
Shape2D s = new
RegularPolygon("0,0","0","3","100");
System.out.println(s);
}
public static void main(String [] argc) Python{
import RegularPolygon
s = RegularPolygon.RegularPolygon("0,0","0","3","100")
print(str(s))
}
}
Load the above code into UmpleOnline
A simple airline system that manages flight and passenger information

// Airline system - sample UML class diagram in Umple
// From Book by Lethbridge and Laganiere, McGraw Hill 2004
// Object-Oriented Software Engineering: Practical Software Engineering using UML and Java
// See https://www.site.uottawa.ca/school/research/lloseng/
namespace Airline;
class Airline{
1 -- * RegularFlight;
1 -- * Person;
}
class RegularFlight{
Time time;
unique Integer flightNumber;
1 -- * SpecificFlight;
}
class SpecificFlight{
unique Date date;
}
class PassengerRole
{
isA PersonRole;
immutable String name ;
1 -- * Booking;
}
class EmployeeRole
{
String jobFunction ;
isA PersonRole;
* -- 0..1 EmployeeRole supervisor;
* -- * SpecificFlight;
}
class Person
{
settable String name;
Integer idNumber;
1 -- 0..2 PersonRole;
}
class PersonRole{}
class Booking{
String seatNumber;
* -- 1 SpecificFlight;
}
class Airline {
// Sample output to illustrate manipulating the model
depend java.sql.*;
public static void main(String [] argc) {
Airline a = new Airline();
RegularFlight f100 = new RegularFlight(
Time.valueOf("10:15:00"),100,a);
SpecificFlight f100jan4 = new SpecificFlight(
java.sql.Date.valueOf("2025-01-04"),f100);
System.out.println(f100);
System.out.println(f100jan4);
}
}
Load the above code into UmpleOnline

// Sample UML class diagram for a banking system, written in Umple
//Namespace for core of the system.
namespace BankingSystem.core.humanResources;
class PersonRole{}
class Person{
name;
address;
phoneNumber;
1 -- * PersonRole;
}
class Employee{
isA PersonRole;
}
class Client
{
isA PersonRole;
name;
address;
phoneNumber;
1..2 -- 1..* Account;
}
class Manager {
isA Employee;
0..1 -- * Employee;
}
//Accounts, priviledges, etc.
namespace BankingSystem.core.intangableResources;
class Account{
Integer accountNumber;
Float balance;
Float creditLimit;
* -> 1 AccountType;
}
class AccountType
{
Float monthlyFee;
Float interestRate;
* -- * Privilege;
}
class Privilege
{
description;
}
class CreditCardAccount{
isA Account;
Date expiryDate;
1 -- 1..* Card;
}
class MortgageAccount {
isA Account;
collateral;
}
//Anything physically tangable
namespace BankingSystem.core.tangableResources;
class Card
{
holderName;
}
class Branch {
isA Division;
address;
branchNumber;
1 -- * Account;
}
class Division{
name;
1 -- * Employee;
0..1 -- 0..* Division subDivision;
}
Load the above code into UmpleOnline

/*
Banking System - sample UML class diagram written in Umple
Last updated: February 21, 2011
*/
//Namespace for core of the system.
namespace BankingSystem.core;
class FinancialInstitution {
name;
1 -- * ReusableFinancialInstrument;
}
class CreditCardCompany{
isA FinancialInstitution;
}
class Bank{
isA FinancialInstitution;
1 -- * Branch;
}
class FinancialInstrument{
}
class ReusableFinancialInstrument{
isA FinancialInstrument;
number;
pin;
* -> 1 Currency;
}
class CreditCard {
isA ReusableFinancialInstrument;
creditLimit;
name;
}
class DebitCard {
isA ReusableFinancialInstrument;
}
class Cheque {
isA FinancialInstrument;
amount;
Date date;
sequenceNumber;
}
class BankAccount{
isA FinancialInstrument;
accountNumber;
balance;
Float overdraftOrCreditLimit;
1..* -- * DebitCard;
1 -- * Cheque;
}
class Currency
{
code;
exchangeRate;
}
class Branch
{
name;
address;
1 -- * BankAccount;
}
class Loan{
isA BankAccount;
}
Load the above code into UmpleOnline

// UML class diagram for a system for managing elections, written in Umple
namespace electorial;
// association should be ->
class PollingStation {
Integer number;
address;
1 -- * PollInElection;
}
class ElectedBody{
description;
1 -- * Position;
}
//Different elections may have different sets of polls
class Election{
Date date;
1 -- * PollInElection;
1 -- * ElectionForPosition;
}
class ElectionForPosition{
1 -- * Candidature;
}
//Eg. Mayor, Councilor. AKA seats
//A position can have different elections for it at different times, eg. once every four years.
class Position {
description;
1 -- * ElectionForPosition;
}
//We need candidature class since a candidate can run for different
//positions and for the smae positions at subsequent elections
class Candidature {
internal Boolean isIncumbent = false;
public void markAsIncumbent()
{
isIncumbent = true;
}
public String toString()
{
return isIncumbent ? "Incumbent" : "Candidature";
}
}
class Candidate {
name;
Integer phoneNumber;
address;
1 -- * Candidature;
}
class PollInElection {
Integer number;
1 -- * Voter;
}
associationClass VotesInPoll{
* Candidature;
* PollInElection;
Integer numVotes;
}
class Voter{
name;
address;
* -- * Candidature;
}
class ElectoralDistrict{
1 -- * Voter;
0..1 -- * Position;
0..1 -- * ElectoralDistrict subDistrict;
}
Load the above code into UmpleOnline

// UML class diagram of a system for managing a warehouse
namespace warehouse;
class MovementLocation{}
class SlotSet{
isA MovementLocation;
0..1 -- 0..1 BoxOrPallet;
1 -- * Slot;
}
class Slot{
Integer number;
Double width;
}
class Level{
Integer height;
Integer number;
1 -- * Slot;
}
class LoadingGate{
Integer number;
isA MovementLocation;
}
class Truck{
Integer registerNum;
Boolean isWaiting;
1 -- * DeliverOrShipmentBom;
}
class Rwbm{
Integer id;
}
class Item{
Double value;
Integer hazardID;
Integer breakability;
}
class Row{
Integer depth;
Integer number;
1 -- * Level;
}
//Note that here we have the choice to use
// Time or Double, if the customer requires Double due to
// some interoperability issues with a legacy syste, we can easily
// accomodate them and use Double instead of Time.
class RwbmMovement{
Double startTime;
Double endTime;
* toMovement -- 1 MovementLocation to;
* fromMovement -- 1 MovementLocation from;
* -- 1 BoxOrPallet movedBox;
1 -- * Rwbm;
}
// Both associations should be ->
class DeliverOrShipmentBom {
Double startTimeLoadOrUnload;
Double endTimeExpected;
* delivery -- 0..1 LoadingGate sentThrough;
* arrival -- 0..1 LoadingGate arriveAt;
}
class BoxOrPallet{
Integer rfidTagNumber;
Double lengthINmm;
Double widthINmm;
Double heightINmm;
Double weightINkg;
String contentType;
* -- * DeliverOrShipmentBom;
1 -- * Item;
}
Load the above code into UmpleOnline
Canal system class diagram.
See also the state diagram for the canal lock.
The following are the requirements from which this was derived:
The Canal Monitoring and Control System is used to automate canal locks in response to water craft that want to pass through a canal system. The system can be installed in any network of canals. Each canal is divided up into segments. Each segment has two ends which can either be a bend, a lock gate, a low bridge, or a system entry/exit point (where boats can move to or from other waterways such as rivers and lakes). A special kind of canal segment is a lock. The water level in a lock can be raised or lowered so its height matches the height of an adjacent segment. Several locks can exist side by side (as in the Rideau Canal next to Parliament Hill in Ottawa). A low bridge is a location where the bridge needs raising for a boat to pass. A bend is simply a place where the canal changes direction - keeping track of these helps simplify mapping of the system.
The system keeps track of the GPS co-ordinates of each segment end, the height of the water above sea level in each segment (which can change in locks), and optionally a name given to a series of locks or segments.
Each water craft using the system must have a transponder. The transponder includes a GPS unit and transceiver. When the captain of a craft wants to travel through the system, he enters his plannned destination in the transponder. The size of the boat is also tracked. The transponder regularly transmits the location of the craft to the control system so the control system can monitor traffic.
When a craft reaches a gate, the system knows it is there and needs to pass through since it has received the data about the desired destination. The control system takes care of opening the gate, raising or lowering of the water level, and then opening the next gate, etc. When a boat reaches a low bridge, a similar procedure takes place, except that raising or lowering the water doesn't happen.
When there are a lot of boats, the system makes several of them queue up so they can pass through a lock or low bridge at the same time. The system has, however, to ensure that only the right number and size of boats are put into a lock at once, so the lock doesn't become overly full (the system knows the size of each lock). Complicating matters is the fact that there will be boats travelling in both directions.
// UML class diagram that models a canal as a
// network of segments, with Locks. See the
// State Machine section for a state machine for
// each lock
class CanalNetwork {
name;
0..1 -- * CanalNetwork subNetwork;
0..1 -- * Craft activeVessels;
* -- * SegEnd;
}
class SegEnd {
name;
GPSCoord location;
}
class Segment {
Float waterLevel; // m above sea level
1..* -- 2 SegEnd;
}
class Lock {
isA Segment;
Float maxLevel;
Float minLevel;
}
class Bend {
isA SegEnd;
}
class EntryAndExitPoint {
isA SegEnd;
}
class MooringPoint {
isA SegEnd;
}
class Obstacle {
isA SegEnd;
0..1 downstreamObstacle -- * Craft upStreamQueue;
0..1 upstreamObstacle -- * Craft downStreamQueue;
}
class LowBridge {
isA Obstacle;
}
class LockGate {
isA Obstacle;
}
class Craft {
lazy GPSCoord location;
}
class Trip {
0..1 -> 1..* SegEnd;
0..1 -- 1 Craft;
}
class Transponder {
id;
0..1 -- 0..1 Craft;
}
class GPSCoord {
Float lattitide;
Float longitude;
}
Load the above code into UmpleOnline
Canal Lock State Machine
See also the class diagram and requirements for the canal system.
// UML state machine diagram for a canal lock,
// represented in UML
class Lock
{
Boolean boatGoingDown = false;
Boolean boatGoingUp = false;
Boolean boatBlockingGate = false;
lockState {
BothDoorsClosedLockFull {
// Waiting for boat
boatRequestsToEnterAndGoDown
-> OpeningUpperGate;
boatRequestsToEnterAndGoUp
-> LoweringWater;
}
OpeningUpperGate {
upperGateFullyOpen -> UpperGateOpen;
}
UpperGateOpen {
entry / {setBoatGoingUp(false);}
boatInLockRequestingToGoDown
-> / {setBoatGoingDown(true);}
ClosingUpperGate;
after(180000) [!boatBlockingGate]
-> ClosingUpperGate;
}
ClosingUpperGate {
upperGateFullyClosed [boatGoingDown]
-> LoweringWater;
upperGateFullyClosed [!boatGoingDown]
-> BothDoorsClosedLockFull;
}
LoweringWater {
waterLevelMatchesDownStream
-> OpeningLowerGate;
}
BothDoorsClosedLockEmpty {
// Waiting for boat
boatRequestsToEnterAndGoUp
-> OpeningLowerGate;
boatRequestsToEnterAndGoDown
-> RaisingWater;
}
OpeningLowerGate {
lowerGateFullyOpen -> LowerGateOpen;
}
LowerGateOpen {
entry / {setBoatGoingDown(false);}
boatInLockRequestingToGoUp
-> / {setBoatGoingUp(true);}
ClosingLowerGate;
after(180000) [!boatBlockingGate]
-> ClosingLowerGate;
}
ClosingLowerGate {
lowerGateFullyClosed [boatGoingUp]
-> RaisingWater;
lowerGateFullyClosed [!boatGoingUp]
-> BothDoorsClosedLockEmpty;
}
RaisingWater {
waterLevelMatchesUpStream
-> OpeningUpperGate;
}
}
}
Load the above code into UmpleOnline
This system will allow players to play card games such as Whist and Oh Hell online.
The system should manage the cards in a deck of cards, the players (including who is dealer), the hands of cards each player has, the tricks, the pile of cards on the table. It should also manage the matches between players. Use some background research to improve these simple requirements.
// Umple class diagram representing card games
// in the Oh Hell and Whist family
class Card {
suit; // "hearts", "clubs", "diamonds", "spades"
rank; // A23456789JQK
Boolean isJoker; // suit and rank are null for a Joker
}
class CardSet {
// Could be a complete deck or a trick
1 -- * Card;
}
class NotDealtCardSet {
// This would be initialized with a complete 52-card set
// at the start of each game
// During dealing, the cards would be distributed to players
isA CardSet;
}
class Trick {
// A group of cards with one contributed by each player, and
// eventually won by a player
// One is built after each player has played a card
isA CardSet;
}
class Player {
// These are the people playing.
name;
// A hand is dealt at the start of a game
// The cards a player has in his or her hand
0..1 -- * Card hand;
// The tricks won by a player this game
1 -- * Trick;
// All hands and tricks are cleared at the end of each game
// ready for dealing again
// The following is used only in Oh Hell
Integer currentTricksBid;
}
class ScoringTeam {
// for Oh Hell, it is each player for himself, so there is one player
// for Whist there are partners, so there are two players
1 -- 1..2 Player;
// The score that each team has accumulated so far
// based on tricks taken or difference between tricks and bid
Integer score;
}
class CardsMatch {
// A cards match is played in a number of games
Boolean isWhist; // True if whist; false if Oh Hell
// The following determines the players
// the first player in the first team deals first
* -- 2..* ScoringTeam; // Exactly 2 if Whist
Integer scoreToWin; // The score agreed to in order to declare winner
1 -- * Game games; // Games continue until a player or team wins
// Assume that the last game in games is the current one
}
class Game {
trumps; // a suit (if any) that is the trumps for this game
// One player is the dealer each game
// The dealer deals out all or most of the cards at the start
// Players take turn laying down cards to form the next trick
* -- 1 Player dealer;
// As the cards are laid down the following set is created.
// After all players have contributed a new trick is created from the
// following and awarded to a player
0..1 -- * Card currentTrickBeingBuilt;
* gameLed -- 0..1 Player currentLead; // the player next to lay down a card
}
Load the above code into UmpleOnline
Requirements for this system are as follows:
A take-out pizza restaurant wants to set up an online ordering system. A customer must have an account to use the system. When the customer creates his or her account, the following information is stored: Email address (which becomes the user id), contact phone number, password, name, address, preferred credit card number, and credit card expiry date. When the customer creates an order the following information is stored: The time the order was placed, the address for delivery, the contact phone number, the total price, the credit card number charged, the expiry date of the credit card, the items ordered and the total price. An item can be pizza or drinks.
For each pizza item, the information stored will include the kind of pizza (thin crust, thick crust or gluten-free crust), the size (small, medium, large), the list of toppings (e.g. cheeze, bacon, vegetables, etc.), the number of items like this (e.g. 10 would mean 10 identical pizzas) and the total price for this pizza item. For each drink item, the information stored is type, size, number, and total price. The system also records each delivery: Associated with each delivery is the name of the delivery driver; the time the driver picked up the order(s) and the time each order was delivered. A driver may take more than one order on a delivery run.
// UML Class diagram representing a system for taking online orders for Pizza
class Account
{
emailAddress;
contactPhoneNumber;
password;
name;
address;
preferredCredCard;
expiryDate;
0..1 -- * Order;
}
class Order
{
timePlaced;
contactPhoneNumber;
Float totalPrice;
creditCardCharged;
expiryDate;
1 -- * OrderItem;
}
class OrderItem
{
Integer number;
Float totalPrice;
}
class PizzaOrder
{
isA OrderItem;
kind;
* -> * ToppingType toppings;
* -> 1 StandardPizzaSize;
}
class ToppingType
{
description;
}
class StandardPizzaSize
{
sizeLabel;
}
class DrinkOrder
{
isA OrderItem;
drinkSize;
size;
}
class Delivery
{
Time timePickedUp;
Time timeDelivered;
* -- 0..1 Driver;
0..1 -- 1..* Order;
}
class Driver
{
name;
}
Load the above code into UmpleOnline
Requirements for this system are as follows:
You are in charge of the website of a community. Residents in the community can sign up to join the community association for a fee of $30. If they do, then they can vote for the executive of the association, can use facilities and attend certain events for free. Only one membership is required per residence and it must be renewed by the end of October each year (it is valid for one year). For each member the system stores the street address, apartment number (if there is one) the email address, the telephone number, and the names of the residents. Anyone under 18 is flagged, as there are special events for these people. The community runs a rink in the winter and three tennis courts in the summer. Members of the community association are given priority to sign up for blocks of time in these facilities, to a maximum of four hours per week. Residents who are not members can sign up 24 hours before their booked time, if there are still any free time slots. When a non-member signs up in this way, they need to give their name, street address and email address. Some time slots in the rink and tennis courts are left unbooked for free 'first-come-first-served' access.
// UML class diagram in Umple showing a simple
// system for managing the data maintained by a
// community association
class Facility
{
id;
type;
openPeriod;
1 -- * Booking booked;
}
class Resident
{
name;
Boolean under18;
emailAddress;
telephoneNumber;
executivePosition;
}
class CommunityResidence
{
streetAddress;
Integer apartmentNumber;
feePaidToDate;
1 -- * Resident;
}
class Event
{
Date date;
Time time;
Float fee;
name;
}
class Booking
{
Date date;
Time startTime;
Time endTime;
Float feePaid;
Boolean isReservedForFCFS;
* -- 0..1 Resident;
}
class Under18Event
{
isA Event;
}
class Rink
{
isA Facility;
}
class TennisCourt
{
isA Facility;
}
class CommunityAssociation
{
singleton;
1 -- * CommunityResidence;
1 -- * Facility;
1 -- * Event;
}
Load the above code into UmpleOnline
Requirements for a University System to Manage Co-Op Programs
The co-op system works as follows. Employers contact the university and list potential jobs. Each job has a description, employer, location, start and end date, and a list of programs (e.g. SEG, CSI, MCG) for which it is applicable.
Each student in the system has a name, student number, list of available time slots (when they are not in courses, or not doing interviews), resume and transcript.
Students in various programs apply for jobs. Students choose a set of jobs they are interested in. The system shows the list of interested students to employers, and employers pick a set of students to interview. The system sets interview times that match the employee’s and student’s availability (set of available time slots).
At the end of the process, the system arranges for the employer to offer each job to a student. If the first student does not accept, the system arranges for other students (the employer’s second, third choices, etc. ) to be offered the job.
// UML class diagram in Umple showing the data managed by
// a co-operative education system that has to place students with employers
class Program
{
name;
1..* -- * Student;
}
class Application
{
* -- 1 Student;
* -- 1 Job;
1..* -- 0..1 Interview;
1 -- 0..1 Offer;
}
class Job
{
description;
location;
Date startDate;
Date endDate;
* -- 1..* Program;
}
class Employer
{
name;
1 -- * Job;
0..1 -> * TimeSlot;
}
class Interview
{
location;
0..1 -> 0..1 TimeSlot;
}
class TimeSlot
{
startTime;
endTime;
status;
}
class Student
{
Integer stNum;
1 -- 1 Transcript;
0..1 -> * TimeSlot;
}
class Resume
{
text;
0..1 -- 1 Student;
}
class Transcript
{
text;
}
class Offer
{
ranking;
Boolean accepted;
}
Load the above code into UmpleOnline
The following are basic requirements for a vending machine.
A vending machine dispenses a variety of products. Each product is held in one or more dispensers, identified by slot and row in the machine. The system keeps track of the number of each product type in each dispenser, so it knows when a dispenser becomes empty.
The vending machine has several coin holders. Each coin holder can contain a specific type of coin worth a particular number of cents, and with a certain weight and diameter. The system tracks the number of coins in each holder, so it can determine whether it can give change, and what coins it should give as change when somebody buys a product. Each holder also has a maximum capacity. The system keeps an electronic record of each successful purchase (transaction); it records the product dispensed from a dispenser and the number of coins added (i.e. paid by the customer) or deleted (i.e. given as change) from coin holders.
// UML class diagram of a vending machine
class VendingMachine {
singleton;
1 -- * Dispenser slots;
}
class Dispenser {
Character row;
Character column;
}
// It is possible for a dispenser to have
// one product type 'in front' and another in behind
class ProductInDispenser {
* -- 1 Dispenser;
* -- 1 ProductType;
Integer numberProductsOfThisTypeLeft;
}
class ProductType {
Integer pricePerUnit; // cents
}
class VendingMachine {
1 -- * CoinHolder;
}
class CoinType {
Integer value; // cents
Integer weight; // grams
Integer diameter; // micrometers
}
class CoinHolder {
* -- 1 CoinType canHold;
Integer numCoinsCapacity;
Integer currentNumberOfCoins;
}
// Every product purchase is recorded
class ProductTransaction {
* -- 1 ProductInDispenser;
1 -- * CoinHolderTransaction; // coins entered and change given
}
// The number of coins transferred to or from a CoinHolder
class CoinHolderTransaction {
Integer numCoinsInOrOut; // negative if used to provide change
* -- 1 CoinHolder sourceOrDestination;
}
//Positions used for diagram display
class VendingMachine
{
position 50 29 119 45;
position.association Dispenser:slots__VendingMachine 120,23 0,8;
position.association CoinHolder__VendingMachine 27,45 5,0;
}
class Dispenser
{
position 290 29 149 80;
}
class ProductInDispenser
{
position 166 157 291 63;
position.association ProductInDispenser__ProductType 10,63 30,0;
position.association Dispenser__ProductInDispenser 217,0 56,80;
}
class ProductType
{
position 120 254 166 63;
}
class CoinType
{
position 45 531 144 97;
}
class CoinHolder
{
position 29 362 236 80;
position.association CoinHolder__CoinType:canHold 40,80 90,0;
}
class ProductTransaction
{
position 337 277 136 45;
position.association CoinHolderTransaction__ProductTransaction 112,46 179,0;
position.association ProductInDispenser__ProductTransaction 3,0 93,63;
}
class CoinHolderTransaction
{
position 283 501 201 63;
position.association CoinHolder:sourceOrDestination__CoinHolderTransaction 16,0 223,80;
}
Load the above code into UmpleOnline
// UML state machine diagram of a vending machine
// There is also a class diagram example separately
class VendingMachine
{
controlUnit {
ReceivingMoney {
enterCoin -> DeliveringItem;
}
DeliveringItem {
deliveryComplete -> ReturningMoney;
}
ReturningMoney {
returningComplete -> Waiting;
}
Waiting {
pressSelection -> ReceivingMoney;
}
}
}
Load the above code into UmpleOnline
This example has been built for the Comparing Modeling Approaches Workshop

// RoutesAndLocations.ump Class diagram represented in Umple
//
// Author: Timothy C. Lethbridge
namespace routesAndLocations;
/*
This file describes reusable model elements that are used in the
bCMS Crisis Management System. It is necessary to have a rudimentary
Graphical Information System such as described in this submodel as part
of bCMS in order to plan routes and to track where crises are. This file
has the necessary classes.
*/
/*
* A CityMap contains the precompiled streets and landmarks
* This must be read in from the database on system initialization
*/
class CityMap {
singleton;
0..1 -> * Landmark fireStn;
0..1 -> * Landmark policeStn;
0..1 -> * Landmark otherLm;
0..1 -> * NamedRoad;
}
/*
* A Location describes a place such as an intersection, landmark, bend in a road, etc.
*/
class Location {
Float lattitude;
Float longitude;
}
class Landmark {
isA Location;
// Name of landmark (name of fire station, business, address)
description;
landmarkType { fireStation { } policeStation { } touristDestination { } other { } }
}
/*
* RoadNodes are places where RoadSegments connect. A node with just one incoming
* and one outgoing is used to handle changes in direction, e.g. as a road turns
* a corner, changes in speed limit, changes in number of lanes, and other factors.
* When there is more than one outgoing or incoming, the node represents points
* where traffic flow can split and join.
* A crossroads is one type. Entry into a roundabout would be another,
* Highway merges and exits are other kinds as are parking lots and entries
* into or out of fire stations..
*
* RoadSegments leaving the city lead to no RoadNode
* RoadSegments entering the city come from no RoadNode
*/
class RoadNode {
Integer id;
// Could be at a landmark
0..1 -> 1 Location nodeLocation;
0..1 end -- * RoadSegment incomingRoads;
0..1 start -- * RoadSegment outgoingRoads;
}
class Intersection {
isA RoadNode;
// illegal, but possible turns for police and fire
0..1 -> * Turn illegalTurns;
// Impossible turns , e.g. because of barriers, turning radius
0..1 -> * Turn impossibleTurns;
}
/*
* Turns are used to model illegal turns, e.g. turning left
* when there is 'no left turn' allowed, or 'no U turn' allowed.
*/
class Turn {
RoadSegment turnFrom;
RoadSegment turnTo;
}
/*
* A named road might have the name of a street, the number of
* a highway, etc. A RoadSegment can have several names because
* for example, sometimes several numbered highways share a segment
*/
class NamedRoad {
name;
// Most roads have two directions, e.g. North and South
direction;
// Listed in order
* -- 1..* RoadSegment segments;
}
/*
* A RoadSegment represents a section of road on which a vehicle can drive.
* The ends of each segment have been modeled using RoadNodes.
* Note that distance can be calculated from the speed limit, and locations
*/
class RoadSegment {
Integer speedLimit;
// Indicator of real-time congestion; 0=blocked
Integer currentReportedSpeed;
Integer lanes;
// The following are used to determine addresses
Integer streetNumberAtStart;
Integer streetNumberAtEnd;
* -> * RoadSegment inverseSegments;
}
/*
* A route is a plan to get from one location to another
* It is built by algorithms that traverse the nodes and arcs of the map
* taking into account speed, congestion, etc.
*/
class Route {
// Ordered list of segments
0..1 -> 1..* RoadSegment;
// Time seconds at current flow speeds
Integer estimatedTime;
}
Load the above code into UmpleOnline
This example has been built for the Comparing Modeling Approaches Workshop
Note that this file is too large for the 'Open In UmpleOnline' to work in most browsers. You will need to copy the text to the clipboard and paste it into UmpleOnline.
// CoordinationStateMachine.ump
// This UML state machine diagram in Umple is for the
// bCMS car crash management system
// See http://cserg0.site.uottawa.ca/cma2012/CaseStudy.pdf
// and http://www.cs.colostate.edu/remodd/v1/content/repository-model-driven-development-remodd-overview
// Author: Timothy C. Lethbridge
/*
* State machine for co-ordination of the
* crisis, as seen from one SC. If
* communication is operating properly the
* other coordinators' state machines will
* generally be in the same states and
* substates.
*
* Modelled given Section 4 of the requirements
* This is a mixin to class crisis.
*/
class Crisis {
// Number of ms allowed to negotiate routes,
// establish credentials
Integer timeoutInMs = 20000;
// True if we are the initiator of the crisis
// request, false otherwise
Boolean thisSideInitiator;
Boolean thisSideInitiatorOfTermination;
Boolean routeAgreedYet;
// True of we are the PSC, false of we are
// the FSC
Boolean police;
// Top level state machine
crisisCoordinationStage {
// 0. When initiated the crisis is in
// noCrisis state
// It has been created but not yet
// populated, awaiting initiation
// of coordination and data..
noCrisis {
entry / {setThisSideInitiator(false);}
// We are initiating and requesting the
// other side to respond
initiateCrisis / {
setThisSideInitiator(true);
sendInitiateCrisisRequestToOtherSC();
} -> establishingCommunication;
// We are responding to a request from
// the other SC
receiveInitiateCrisisRequest ->
establishingCommunication;
}
// 1. Establish communication and
// identification when a crisis begins
establishingCommunication {
entry / {sendSecureCredentials();}
secureCredentialsConfirmed ->
managingCrisis;
// Return to idle after some delay if
// other side initiated and did not
// respond. It might have been a
// hacker. Alternatively if there is a
// real crisis, normal manual processes
// would happen.
after (timeoutInMs)
[!isThisSideInitiator()] -> noCrisis;
}
// Managing crisis involves continually
// exchanging information
// Negotiating or renegotiating routes and
// other crisis details
// These are handled concurrently.
managingCrisis {
// A crisis is underway. We initially
// start with empty data
// which will be populated over time
entry / {initiateEmptyCrisis(); }
// 2,4,5,6. Exchanging details about what
// each knows about the crisis
// So the information each coordinator
// has is the same.
exchangingDetails {
// Requirement Scenario 2
ourUpdateToCrisisData
/ {sendCrisisData();}
-> exchangingDetails;
receiveCrisisData
/ {updateCrisisData();}
-> exchangingDetails;
// Requirement Scenario 4
ourVehicleDispatched
/ {sendVehicleDispatch();}
-> exchangingDetails;
receiveVehicleDispatched
/ {updateTheirDispatch();}
-> exchangingDetails;
// Requirement Scenario 5
ourVehicleArrived
/ {sendVehicleArrived();}
-> exchangingDetails;
receiveVehicleArrived
/ {updateTheirArrival();}
-> exchangingDetails;
// Requirement Scenario 6
ourVehicleMetObjective
/ {sendVehicleMetObjective();}
-> exchangingDetails;
receiveMetObjective
/ {updateTheirMetObjective();}
-> exchangingDetails;
// Requirement 5.a - breakdown
breakdown / {dispatchAndUpdateOther();}
-> exchangingDetails;
// Requirement 5.b -
// congestion/blockage
// TO DO
// Requirement 5.c escalate crisis -
// renegotiate routes
// TO DO
} // End of exchangingDetails
//concurrent substate
||
// 7. Both parties must agree to close
// the crisis; either can initiate
crisisEndManagement {
// Normal substate of crisisEndManagement - no end in sight yet
ongoingCrisis {
// We could initiate termination
initiateTermination / {
setThisSideInitiatorOfTermination(true);
sendTerminationRequestToOtherSC();
} -> waitingForTerminationConfirmation;
receiveTerminationRequestFromOtherSC
->
waitingForUserTerminationAgreement;
}
waitingForUserTerminationAgreement {
do {confirmWithUserToTerminate();}
confirmTermination -> tearDown;
after (timeoutInMs) -> ongoingCrisis;
}
// Substate of where we are waiting for
// the other end to agree
waitingForTerminationConfirmation {
receiveTerminationConfirmation
-> tearDown;
// If the other side has not agreed,
// we keep the crisis active
after (timeoutInMs) -> ongoingCrisis;
}
// End of crisis
tearDown {
entry / {deleteCrisis();}
-> noCrisis;
}
} // End of crisisEndManagement
// concurrent substate
||
// 3. Negotiating route plan
negotiatingRoutePlan {
// Negotiation happens in parallel with
// reporting timeout
negotiation {
entry / {setRouteAgreedYet(false);}
informOfNumberOfVehicles
/ {sendNumberOfVehicles();}
-> negotiation;
receiveNumberOfVehicles [isPolice()]
-> planningRoute;
receiveRouteProposal [!isPolice()]
-> approvingRoute;
// Requirement 3.3.a2.a1
receiveNoAgreeableRoute
[!isPolice()] -> noRouteAgreement;
// The PSC plans the route -- only
// PSC can be in this state
planningRoute {
do {planRoute();}
routePlanComplete
/ {sendPlanToFSC(); }
-> awaitingRouteApproval;
// Requirement 3.3.a2.a1 - no more
// possible routes
noMoreRoutes
/ {sendNoMoreRoutesToFSC(); }
-> noRouteAgreement;
}
// The FSC approves the route --
// only FSC can be in this state
approvingRoute {
do {userConfirmRouteAcceptable();}
routeAcceptable
/ {sendApprovalToPSC();}
-> routeAgreed;
routeUnacceptable
/ {sendDisapprovalToFSC();}
-> negotiation;
}
// The PSC awaits for approval from
// the FSC. Only the PSC can be in
// this state
awaitingRouteApproval {
receiveApprovalFromFSC
-> routeAgreed;
// Requirement 3.3.a - FSC
// disagrees
receiveDisapprovalFromFSC / {
addRouteToDisapprovedChoices();
} -> planningRoute;
}
routeAgreed {
entry / {setRouteAgreedYet(true);}
}
noRouteAgreement {
// requirement 3.3.a2.a1
}
} // End of Negotiation concurrent
// substate of negotiatingRoutePlan
||
managingTimeliness {
timeAcceptable {
// Requirement 3.a1. Negotiations
// are taking excessive time
after (timeoutInMs)
[!isRouteAgreedYet()]
-> timeUnacceptable;
}
timeUnacceptable {
// Although negotiations may yet
// complete, we are going to send
// out our own vehicles because too
// much time has passed
do {
promptAndLogReasonForTimeout(); }
}
} // End of managingTimeiness
//concurrent substate of
// negotiatingRoutePlan
} // End of NegotiatingRoutePlan
//concurrent substate
} // End of Managing Crisis top level state
} // End of crisisCoordinationStage state
// machine
} // End of state machine mixin for
// Crisis
Load the above code into UmpleOnline
The tips below will appear as the tips of the day in UmpleOnline. You can read them all here.
An association between two classes can be specified in either class (see an example in the user manual) or separately from either class, using the association keyword
If you specify singleton; in any class, then the singleton pattern will be applied, meaning that there will only be one instance.
By default each attribute in a class becomes a constructor argument (along with associations that have a multiplicity of 1 at their other end).
If you want to avoid this, then add the keyword lazy before the association. The attribute will then be initialized with a null, empty or zero value.
In Umple you can specify a data type before any attribute. But if you do not, then attribute will default to type String.
If you use the datatypes String, Double, Float, Integer, Boolean, Date or Time as the types of attributes, then Umple generates code tailored to the target language.
For example, when generating Java, an Integer attribute is implemented as an int variable. This is important to know, since the methods Umple generates to access those variables will use the Java type. If you specify Integer id; in Umple, and generate Java, then the API will have a method with signature setId(int)
Why does Umple then bother with an Integer datatype if it will be converted to int when generating Java? Because we want key types to be independent of the target programming language.
Under Tasks, you can create numerous assignments with different names, instructions, Umple models, and completion URLs (such as feedback quizzes) with the option of detailed logging. Simply create a task and distribute the participant URL or ask the responders to look up the name of the task under "Load Task" in order to start their submissions.
To acquire all the submissions, click "Request all Directories as a zip" under the task editing panel and all of the submissions will be saved on your local computer.
At the bottom-left of each user manual page is a link called Combined Version. If you select this you can then use the built-in search function in your browser (control-f or command-f) to find information. Beware though that the combined version web page is extremely big. There is also a pdf version of the manual available.
Umple follows the Java, C and C++ approach of specifying the type of an attribute: The type is specified followed by the name. For example:
Integer count;
But class diagrams created in Umple follow the UML convention whereby the type follows the name of the attribute, with a colon separating them. So the above example in a diagram appears as:
count: Integer
In UmpleOnline you are able to write code in multiple tabs. The tabs appear above the text-editing area in the top-left. To add a new tab, click on the + symbol.
You can rename a tab by double-clicking on its name, and typing the new name.
Consider the tabs to be separate files. You can arrange for the model in a tab to know about the model in another tab you have named Utilities by including the expression use utilities.ump
You can select Hide Tabs to hide model tabs if you don't want to use them, and Show Tabs to show them again.
Note that tabs can also be shown in the generated code area; these are entirely separate
If you hover the cursor over the right edge of the text panel (just to the left of the menu) or the left edge of the diagram panel (just to the right of the menu), the cursor will change. When the cursor has changed you can press the mouse/trackpad and drag left or right to change the relative portion of the screen devoted to either panel.
In UmpleOnline, by toggling the T and D buttons above the text editor, you can choose to hide and show the text panel (T) or the diagram panel (D).
Hiding the diagram panel temporarily can sometimes speed up your work, although you will receive less feedback about your model. When the diagram is visible it updates automatically 3 seconds after you stop typing new code in the model panel.
Hiding the text panel temporarily can help you display a large diagram on the screen.
By hovering over a button or some text in UmpleOnline, a message will be displayed with extra information about that item.
License: All use of Umple and UmpleOnline is subject to the Umple MIT license. Please read it carefully, since it disclaims liability. This is not because we don't want to be 'good engineers' and take responsibility for work, rather it is because we are following the open source model, which allows a wide variety of people to modify Umple.
Risk due to support by hosting organizations: UmpleOnline is hosted by the Digital Research Alliance of Canada, and maintained by the University of Ottawa with funds from research grants and donations. Should these supports cease and donations not suffice, then support for Umple may cease unless others take over responsibility. Similarly, the code is hosted on Github. If Github decides to cease hosting projects for free, the Umple code would need to be hosted somewhere else.
Risk of deprecation, missing features and defects: It is possible, although unlikely, that Umple code which works today may cease working in the future. Development is performed in the context of research. You will therefore find incomplete features, which may have bugs. We encourage you to report new bugs (and fix them) and to realize that you may need to work around the existing ones if you use experimental features. That said, we do use test-driven development to maintain what we believe is a high level of quality for the core features.
Limitations of UmpleOnline: The purpose of UmpleOnline is to allow people to explore Umple and model-oriented programming, particularly in an educational context. UmpleOnline is not intended to be a full-fledged tool for either commercial or open source; this is one of the reasons why it is only capable of working with a small number of Umple files per user session. If you want to do serious development in Umple, with many files, you should download it and run it on the command line, or some other supported IDE.
Not certified for safety critical or mission critical use: At the current time Umple-generated code should not be used for mission-critical or safety critical uses, including software for any device that may pose a safety risk if it performs incorrectly, or software that would cause economic damage if it failed. We intend that, in time, Umple and tools like it will in fact help improve safety and reliability. But at the current time we have not subjected Umple to the rigorous validation it needs for such uses, and there are known issues that would preclude such current use.
Need to apply best practices: Should you choose to use Umple for production use, it is critical that you follow rigorous software engineering practices including (but not limited to): Requirements analysis, careful design, code inspection, and thorough automated testing. See here for a list of Umple best practices.
UmpleOnline stores a copy of your most recent edited Umple code and various settings in cookies. This protects against losing data by accidental closure of the browser. Upon starting UmpleOnline again, the user will be presented with an option to 'Restore saved state' by loading the model and settings from such cookies. This does mean that someone else might be able to find out what you were editing if they had access to your computer. You should not, therefore, use UmpleOnline if you are concerned about such access.
Models entered in UmpleOnline are automatically stored on servers managed by the Digital Research Alliance of Canada. Each time you type and pause for three seconds, each time you make an edit to a diagram, and each time you generate code, your data is saved. The data includes one or more .ump files, plus the data you have generated from those files (Java code, Python code, etc.).
Data saved automatically in this way remains stored in the cloud by the Digital Research Alliance of Canada (backed up periodically to the University of Ottawa) for two days or slightly more. This is so you can continue an editing session, even if you walk away from your computer for an extended period. We have an automated process that will normally delete such data after a few days. However we reserve the right to record general statistics about the size of models and other uses of Umple tools before we delete such data.
If you choose 'Save as URL' then your model is stored for an extended period, subject to deletion rules described below. Your files can be edited and deleted by anyone to whom you give the URL, or by anyone who guesses the URL (there is less than a 1 in a trillion chance of this though).
If we detect abuse of UmpleOnline, we reserve the right to attempt to track the user using such tools as the originating IP address, and to block access from such an address or address range.
We will occasionally use external tools such as SurveyMonkey to conduct surveys of users, links to which may appear from time to time on the screen. People who complete such surveys would then be subject to the privacy rules of such external tools. Users are requested to give informed consent prior to taking such a survey, and such informed consent is first approved by the University of Ottawa's Research Ethics Board.
The only data saved by UmpleOnline is the model you create, either graphically or textually or both. There is currently no login mechanism so there is no userid, name or other personal data associated with your model. We may impose a login requirement in the future, but in that case we would only store the minimum of data (loginID, your name, an encrypted salted password, and an email address for account confirmation, to contact you and to allow for password reset).
You may, however, embed (at your choice) confidential information in the code or models you write in UmpleOnline. It is important for you to realize that this information is accessible to the site maintainers and to anyone to whom you give the URL of your data.
Since no userid is currently associated with UmpleOnline models, we have no way of determining who has saved which models at the current time. We cannot guarantee to be able to recover any file you may have 'lost'. Nor can we determine whether anyone else has looked at or modified your files.
Models and associated generated outputs are always deleted after a few days unless explicitly saved as a permanent URL. If the user generates a permanent URL our normal policy is to keep the data for two years after the last time it has been edited. But this is not guaranteed, for the reasons mentioned below.
You may delete your own model in UmpleOnline: Simply select all the text and delete it. To delete all records of generated code, it is suggested that you replace your model by a single line of code (such as class X {} and then generate code from it (generate code in all formats you have previously generated).
Staff at the University of Ottawa reserve the right to delete models for any of the following reasons:
If somebody is able to guess the URL of your model, or you give it to them, then they can modify and delete your model. Important models should therefore be saved using other means. Instructions for how to do that are here.
There is currently no login mechanism to UmpleOnline so there is no way to trace users, as stated earlier. This may change in the future.
Below is the complete grammar for Umple . This page is generated automatically from the grammar used to parse Umple code.
Refer to the Grammar Notation section for more explanation of the EBNF syntax used here.
In Umple we use our own extended EBNF syntax for the grammar, with our own parsing tool. The reason for this is that we wanted several advanced features in the grammar and parser.
Samples of syntax in this user manual are generated directly from the input grammar files used to parse Umple code.
Our syntax offers a very simple mechanism to define a new language, as well as extend an existing one. We will be using examples to help explain our syntax.
Let's start with a simple assignment rule (not part of Umple, just an example):
assignment : [name] = [value] ;
Above, the rule name is "assignment". An assignment is comprised of a non-terminal called "name", then the equals symbol ("="), a non-terminal "value" and finally a semi-colon symbol (";").
A non-terminal by default as shown above is a sequence of characters that is a non-whitespace that is delimited by the next symbol (based on the specified grammar). In the above case, the non-terminal "name" will be defined by the characters leading up to either a space, newline, or an equals ("=").
Here are a few examples that satisfy the assignment rule above:
Let us now consider nesting sub-rules within a rule. Sub-rules are words between [[ and ]]. Again, the following is illustrative, and is not Umple itself
directive- : [[facadeStatement]] | [[useStatement]]
facadeStatement- : [=facade] ;
useStatement : use [=type:file|url] [location] ;
Above, we have three rules, "directive", "facadeStatement", and "useStatement". A "directive" is either a "facadeStatement" or a "useStatement" (the "or" expression is defined by the vertical bar "|"). As indicated earlier, to refer to a rule within another rule, we use double square brackets ("[[" and "]]").
By default, rule names are added to the tokenization string (the result of parsing the input, shown in blue below). But, some rules act more like placeholders to help modularize the grammar (and to promote reuse). To exclude a rule name (and just the name, the rule itself will still be evaluated and tokenized as required), simply add a minus ("-") at the end of its name.
Above, we see that the rule names "directive", and "facadeStatement" are not added to the tokenization string because of the trailing minus signs..
For example, the text
"facade;"
is tokenized as follows:
[facade:facade]
Without the ability to exclude rule names, that same text would be tokenized with the following additional (and unnecessary)
text:
[directive][facadeStatement][facade:facade]
Symbols (i.e.terminals), such as "=" and ";" are used in the analysis phase of the parsing (to decide which parsing rule to invoke), but they are not added to the resulting tokenziation string for later processing.
If we want to tokenize symbols, we can create a constant using the notation
[=name]
In the earlier example we see that a "facadeStatement" is represented by the sequence of characters "facade" (i.e. a constant).
To support lists of potential matches we use a similar notation
[=name:list|separated|by|bars].
In the earlier example, we see that the "type" non-terminal can be the constant string sequence "file" or "url".
Hence, here are a few examples that satisfy the earlier example:
Parentheses can be used to group several elements in the grammar into a single element for the purposes of the following special treatment.
An asterisk * means that zero or more of the preceding elements may occur.
A plus sign + means that one or more of the preceding elements must occur.
A question mark ? means that the preceding element may occur.
Normally when parsing, all whitespace (spaces, carriage returns, tabs, etc.) around tokens are ignored, and the token output by the parser does not contain them. However, if a # symbol is found after the rule (on the left hand side) then all whitespace is preserved. This is useful for cases where that space is actually useful, such as in Umple's templates.
The grammar syntax supports a simple mechanism for non-terminals that can include whitespace (e.g. comments). Text in [** ] such as [**arbitraryStuff] is not parsed. However if the rule name is followed by a colon, such as [**templateTextContent:<<(=|#|/[**] then a pattern for different types of brackets that can be internally parsed can be specified. So the above says ignore everything except things in <<= <<# <</* , which will be processed.
Let us consider the rules to define inline and multi-line comments.
inlineComment- : // [*inlineComment]
multilineComment- : /* [**multilineComment] */
The [*name] (e.g. [*inlineComment]) non-terminal will match everything until a newline character. The [**name] (e.g. [**multilineComment]) non-terminal will match everything (including newlines) until the next character sequence is matched. In the case above, a "multilineComment" will match everything between "/*" and "*/".
Here are a few examples that satisfy the assignment rule above:
By default, [name] matches identifiers that can include underscore and certain other symbols. To match alphanumeric identifiers only, then use
[~name]To match based on a regular expression (such as a sequence of one or more digits in this case):
[!bound:\d+]
To match one or more identifiers, but with some being optionally omitted use this notation:
[attr_qualifier,attr_type,attr_name>2,1,0]
This states that there will be one, two, or three identifiers. The priority of inputs is attr_name,attr_type and attr_qualifier.
The following table describes the API generated from various Umple features. This is designed as a quick reference. To find the exact API for any system that would be generated in Java, use UmpleOnline and request to generate JavaDoc output.
| Summary of the API generated by Umple from attributes, associations, state machines and other features | ||||||||||||
| API GENERATED IN ALL CASES | ||||||||||||
| void delete() | removes object, correctly handling cascade deletion and referential integrity | |||||||||||
| any methods in the code are emitted as-is; they are made public if this is not declared | ||||||||||||
| API GENERATED FROM ATTRIBUTES | ||||||||||||
| T is the type of the attribute (String if omitted); note that Umple builtin types such as Integer become native types such as int | ||||||||||||
| z is the attribute name | ||||||||||||
| Note that the API for array attributes is shown as a column in the associations table further down | ||||||||||||
| Umple concept | basic | initialized | lazy | defaulted | lazy immutable | immutable | autounique | constant | internal | key | ||
| Umple notation | T z; | T z = val; | lazy T z; | defaulted T z = val; | lazy immutable T z; | immutable z; | autounique z | const T z=val | internal T z; | key { z } | ||
| Querying value | ||||||||||||
| T getZ() | return the value | yes | yes | yes | yes | yes | yes | yes; T always int | depends | |||
| boolean isZ() | return true if value is true | if T Boolean | if T Boolean | if T Boolean | if T Boolean | if T Boolean | if T Boolean | depends | ||||
| boolean equals(Object) | is equal to another? | yes | ||||||||||
| Mutating | ||||||||||||
| boolean setZ(T) | mutates the attribute | yes | yes | yes | yes | yes; true only once | depends | |||||
| boolean resetZ() | restores original default | yes | ||||||||||
| Other | ||||||||||||
| T getDefaultZ() | returns original default | yes | ||||||||||
| int hashCode() | Likely unique value | yes | ||||||||||
| constructor args | T | T | ||||||||||
| initial value | constructor val | val | null/0/false | val | null/0/false | constructor val or val | next int | static val | construtor val | |||
| API GENERATED FROM ASSOCIATIONS | ||||||||||||
| X is the name of current class | ||||||||||||
| W is the name of the class at the other end of the association; used in method names unless a role name is present; pluralization rules are applied | ||||||||||||
| r is a role name used when referring to W (optional, except in reflexive associations) | ||||||||||||
| Umple concept | ? To many | ? To many with role | optional | ? To one | required many | directional | immutable | immutable optional | reflexive | symmetric reflexive | array attribute | |
| Umple notation | -- * W; | -- * W r; | -- 0..1 W; | -- 1 W; | -- 1..* W; | -> 1--* W; | immutable 1 -> * W; | immutable 1 -> 0..1 W; | * -- * X r; | * self r; | W [] r; | |
| Querying link(s) | ||||||||||||
| W getW() | return the W | yes; W or null | yes | W or null | ||||||||
| W getW(index) | pick a specific linked W | yes | yes; getR(index) | yes | yes | yes | R and X | R | yes; getR(index) | |||
| List<W> getWs() | ges immutable list of links | yes | yes; getR() | yes | yes | yes | R and Xs | yes; W[] getR() | ||||
| boolean hasWs() | is cardinality > 0? | yes | yes; hasR() | yes | yes | yes | R and Xs | R | yes; hasR() | |||
| int indexOfW(W) | look up specific W -1 if none | yes | yes; … ofR(W) | yes | yes | yes | R and X | R | yes; … ofR(W) | |||
| int numberOfWs() | cardinality | yes | yes; … ofR() | yes | yes | yes | R and Xs | R | yes; … ofR() | |||
| Mutating | ||||||||||||
| boolean setW(W) | add a link to existing W | yes | if * -- or 0..1 -- | never | never | |||||||
| W addW(args) | construct a new W and adds link | if 1 -- * W | if 1 -- * W r | never | never | |||||||
| boolean addW(W) | add a link to existing W | yes | yes; addR(W) | yes | yes | never | never | R and X | R | yes; addR(W) | ||
| boolean setWs(W…) | add a set of links | yes | yes | never | never | |||||||
| boolean removeW(W) | remove link to W if possible | yes | yes; removeR(W) | yes | yes | never | never | R and Xs | R | yes; removeR(W) | ||
| Other | ||||||||||||
| static int minimumNumberOfWs() | multiplicity lower bound | yes | yes; … ofR() | yes | yes | yes | R and Xs | R | ||||
| static int maximumNumberOfWs() | multiplicity upper bound if > 1 | |||||||||||
| static int requiredNumberOfWs() | fixed multiplicity if > 1 | |||||||||||
| boolean isNumberOfWsValid() | false if breaching constraints | yes; true initially | ||||||||||
| constructor args | W (W args if 1 -- 1) | W … | W | |||||||||
| initial value | empty | empty | empty | constructor val | empty | empty | constructor val | constructor val | empty | empty | empty | |
| API GENGERATED FROM STATE MACHINES | ||||||||||||
| sm is the name of the state machine | ||||||||||||
| Umple concept | Sm with events | Enum with no events | ||||||||||
| enum getSm() | current state for statemachine sm | yes | yes | |||||||||
| String getSmFullName() | current state for statemachine sm | yes | yes | |||||||||
| enum getSmS2() | state of substate s2 | yes | ||||||||||
| boolean e() | event method e (for all events) | yes | yes | |||||||||
| boolean setSm(enum) | set state directly | yes | ||||||||||
| Substates allowed | yes | |||||||||||
| initial value | first state listed | |||||||||||
| API GENERATED FROM SINGLETON | ||||||||||||
| static X getInstance() | ||||||||||||
The subsequent pages in the user manual describe each of the errors or warnings that can be emitted by the compiler. These can appear in UmpleOnline, Eclipse and the command-line compiler.
An error is a situation where the compiler can't generate code because the Umple code doesn't make sense; i.e. there is something critical missing, or there is an inconsistency.
A warning is a situation where code can be generated, but the resulting system may not to have the intended semantics (it may not behave as intended) because of an inconsistency, redundancy or assumption that may not be correct.
For developers of Umple itself: The file defining the messages in English is called
en.error and is located in cruise.umple/src. Errors have severity 1 or 2, and warnings have severity 3, 4 and 5. When adding a message, a user manual
page should be added describing it.
All
messages should be detected in the parsing phase by calling setFailedPosition.
It is intended in the future that
internationalized versions of Umple will be created; for example fr.error would be the
French version. In the near future, it is intended to enable messages from Java or other
compilers to be passed through as part of the Umple compilation process; these would be
the same as the native language compiler, except that line numbers would be changed to
point to the correct line of Umple code.
A singleton class can't have any arguments in its constructor. In general in Umple, unless an attribute is specified as 'lazy', then an argument for the attribute is added to the constructor. In the case of singletons, this is not done. This warning is to let programmer know this. To avoid the warning, add the keyword 'lazy' to all attributes of a singleton class. However, whether or not this is done, the generated code will behave as if it had been done.
// This example generates the warning message
class X {
singleton;
Integer x;
}
Load the above code into UmpleOnline
// The following shows how to avoid the warning
class X {
singleton;
lazy Integer x;
}
Load the above code into UmpleOnline
The constructor of a singleton can't take any arguments. Therefore, it can't have a required link to another object, since this would have to be specified in the constructor. Any associations to other classes should therefore have multiplicity with lower bound of zero.
Note: Conceptually, this warning would also have been produced if the lower bound was something greater than 1 (e.g. 5). However, Umple treats a multiplicity specified with a lower bound > 1 as if the multiplicity lower bound was 0. The programmer is supposed to add the n elements immediately after construction. The API has a validity check method to verify this has been done.
// This example generates the warning message
class X {
singleton;
0..1 -- 1 Y;
}
class Y {
}
Load the above code into UmpleOnline
// The following shows how to avoid the warning
class X {
singleton;
0..1 -- 0..1 Y;
}
class Y {
}
Load the above code into UmpleOnline
The function of the 'lazy' keyword is to indicate that an attribute is not to appear in the constructor. However an initializer for the attribute has the same effect, so specifying both 'lazy' and an initializer is redundant, and hints that there may be a mistake. The solution is just to remove the extraneous 'lazy'.
// This example generates the warning
class X3lazy {
lazy Integer a = 1;
}
Load the above code into UmpleOnline
// This shows how the warning can be removed.
class X3lazy {
Integer a = 1;
}
Load the above code into UmpleOnline
Valid multiplicities in Umple include the following, where n and m are positive integers and where n <= m:
When this error message appears, the multiplicity doesn't fit any of the above patterns. A common error, for example, is to use the notation 'n' as found in Entity-Relationship Diagrams, instead of *. This is not valid in Umple; only integers, and * may appear.
// This example generates the error message
class X {
1 -- 0..1..2 Y;
}
class Y {
}
Load the above code into UmpleOnline
// The following shows how to avoid the error
class X {
1 -- 0..2 Y;
}
class Y {
}
Load the above code into UmpleOnline
The classes at both ends of an association must exist in the system being compiled. It might be that the specified class is spelled wrongly or has been omitted from the compilation. If you are making an association to a class in existing code, then simply declare the class as external, as shown in the third example below.
// This example generates the error message
class X {
1 -- * Y;
}
Load the above code into UmpleOnline
// The following shows how to avoid the error
class X {
1 -- * Y;
}
class Y {}
Load the above code into UmpleOnline
// It is also possible to designate that
// the class Y is external in the following manner
class X {
1 -- * Y;
}
external Y {}
Load the above code into UmpleOnline
// The following will also generate the error message
class X {}
class Y {}
association {
1 X -- * Z;
}
Load the above code into UmpleOnline
The keyword 'defaulted' means that the attribute will be given a default value if the value is not set in the constructor. Omitting the default value is therefore illogical. The default value is specified after an equals sign.
// This example generates the error message
class X {
defaulted Integer a;
}
Load the above code into UmpleOnline
// The following shows how to avoid the error
class X {
defaulted Integer a = 5;
}
Load the above code into UmpleOnline
To avoid confusion, a class should normally only have one key specification. This warning is intended to direct the programmer to list the multiple attributes within the same key directive, rather specifying them separately.
The reason for this is that without this warning, code that is separated by many lines or found in a mixin file might modify the key in a way that wasn't anticipated by the developer who is not aware of the existence of multiple key statements.
Developers can ignore this warning without any consequences. The examples below will generate the same compiled code.
// This example generates the message
class X {
name;
id;
key { name }
key { id }
}
Load the above code into UmpleOnline
// This example below avoids the message
class X {
name;
id;
key { name, id }
}
Load the above code into UmpleOnline
An association class must have two classes designated as its ends. Instances of the association class represent links between instances of the associated classes, so it is illogical for an association class to have only one end.
// This example generates the error message
class A {}
class B {}
associationClass C {
* A;
}
Load the above code into UmpleOnline
// The following shows how to avoid the error
class A {}
class B {}
associationClass C {
* A;
* B;
}
Load the above code into UmpleOnline
A reflexive association must have multiplicity with lower bounds of zero at both ends (e.g. *, 0.1 or or 0..2), otherwise an illogical situation would result. For example, creating a parent-child association on class Person (the example below) with a lower bound of 2 would mean that every Person in the system must have parents, ad infinitum.
// This example generates the error message
class Person {
* -- 2 Person parents;
}
Load the above code into UmpleOnline
// The following shows how to avoid the error
class Person {
* -- 0..2 Person parents;
}
Load the above code into UmpleOnline
Since there can only be one instance of a singleton class, it is logically impossible for another class to have links to more than one instance of the singleton class.
// This example generates the warning message
class X {
singleton;
}
class Y {
0..1 -- * X;
}
Load the above code into UmpleOnline
// The following shows how to avoid the warning
class X {
singleton;
}
class Y {
0..1 -- 1 X;
}
Load the above code into UmpleOnline
The inheritance hierarchy cannot have cycles. It must be a strict tree. It is therefore not allowed to make a class into a subclass of itself.
// This example generates the error message
class X {
isA X;
}
Load the above code into UmpleOnline
// The following shows how to avoid the error
class Y {}
class X {
isA Y;
}
Load the above code into UmpleOnline
The inheritance hierarchy cannot have cycles. It must be a strict tree. It is therefore not allowed to make a cycle or loop, in which a class is indirectly a subclass of itself.
// This example generates the error message
class A {
isA C;
}
class B {
isA A;
}
class C {
isA B;
}
Load the above code into UmpleOnline
// The following shows how to avoid the error
class A {
}
class B {
isA A;
}
class C {
isA B;
}
Load the above code into UmpleOnline
By definition, an immutable class can't change state, so it can't have an association that can change state or an association to a class that can change state.
// The following example generates
// the error message
class X {
Integer x;
}
class Y {
String s;
immutable;
0..1 -> 0..1 X;
}
Load the above code into UmpleOnline
// One way to solve this is to make
// the association point to
// another immutable class
// But note that this only works for
// one-way associations
class X {
Integer x;
immutable;
}
class Y {
immutable;
String s;
0..1 -> 0..1 X;
}
Load the above code into UmpleOnline
// Another solution is to not require
// the association to be immutable,
// just the attributes. But this may
// not match the intended semantics.
class X {
immutable Integer x;
}
class Y {
immutable String s;
0..1 -- 0..1 X;
}
Load the above code into UmpleOnline
Immutability means that no aspect of the state (attribute, association, state machine) can change in a class once constructed. However if a superclass has mutable elements, they are inherited as mutable. As a result it is not allowed for an immutable class to be a subclass of a mutable class.
Note that this will occur if the entire subclass is being declared as immutable and if any element of the superclass is not immutable. It is possible to have mixes of immutable elements and mutable elements in any given class. In the example below, one solution would be to declare attribute b as immutable and remove the class-level immutable status. Class X14immut would be mutable because it would inherit mutable attribute a.
// This example generates message 14
class B {
a;
}
class X14immut {
isA B;
immutable;
b;
}
Load the above code into UmpleOnline
By definition, an immutable class can't change state, so it can't have a state machine. Any state machine defined is ignored.
// The following example shows how to
// generate this warning.
// Removing the immutable keyword will
// solve the problem.
class X {
immutable;
Integer y;
sm {
S1 {
}
}
}
Load the above code into UmpleOnline
In an inheritance hierarchy, all classes must be immutable, or all non-immutable, otherwise the substitutability principle would broken.
// The following example generates the error message
// A solution is to make class X immutable
class X {
a;
}
class Y {
immutable;
isA X;
}
Load the above code into UmpleOnline
Allowing two-way associations to be immutable would be impossible since it would require change to one object when it is linked to the other, and that would break the concept of immutability.
// The following example generates the error message
// Change the -- to -> to solve the problem
class Y {
immutable;
1 -- * Z;
isA X;
}
class Z {
immutable;
y;
}
Load the above code into UmpleOnline
This is a special case of the general rule that reflexive associations must have upper bounds greater than zero.
// The following example generates the error message
class X {
immutable;
0..1 -> 1 X other;
}
Load the above code into UmpleOnline
Associations between the same classes must be given different names. This error can occur when two associations have the same role name; the solution is to change one of the role names. The error can also occur when two associations are created without any role name at all. In that case the default name is generated from the associated class. The solution is to add a role name to one of the associations.
The first example below is a simple case where there are identical associations with no role name. The second example shows how to solve this.
The third example shows that error 19 can also occur with association classes. The solution to this can be found in the manual page for association classes.
Note that if warning W093 is being raised, resolve that issue first. This will resolve the error in some cases.
// The following example shows how
// to generate error 19.
// The solution is to at least one
// role name one or both of the Y ends
// and at least one role name on one
// of both of the X ends.
class X {
}
class Y {
0..1 -> * X;
0..1 -> * X;
}
Load the above code into UmpleOnline
// Using role names rn1 and rn2 to
// avoid error 19
class X {
}
class Y {
1 -- * X;
1 rn2 -- * X rn1;
}
Load the above code into UmpleOnline
// Example of an association class
// definition that generates error 19
// The solution is to add a role name
// such as menteeAssignments between
// the first * and Member
class Member {
name;
}
associationClass Assignment {
Date dateEstablished;
* Member mentor;
* Member mentee;
}
Load the above code into UmpleOnline
An association can be declared from a class to an interface, but if this is done, it must be one way using the '->' notation. The reason for this is that no concrete methods can be generated in an interface.
// This example generates the message
class X20classintfarrow {
1 -- * IA;
}
interface IA {}
Load the above code into UmpleOnline
// This example generates the message
class X20classintfarrow {
1 <- * IA;
}
interface IA {}
Load the above code into UmpleOnline
Code cannot be generated for asymmetric reflexive associations unless there is a role name at at least one end. This ensures the generated API has distinct words for each end.
For more information about reflexive associations, see this page.
// The following example shows
// how to generate this error.
class X {
0..1 -- 0..1 X;
}
Load the above code into UmpleOnline
// The following example shows how
// to fix the error if this is an
// asymmetric association.
class X {
0..1 -- 0..1 X right;
}
Load the above code into UmpleOnline
// The following example shows how to fix
// the error if this is a symmetric association.
class X {
0..1 self right;
}
Load the above code into UmpleOnline
Attributes in a class must have distinct names. The solution to this error is to rename or delete one of the attributes. This error is particularly prone to appear when a class is composed of two or more files using Umple's 'mixin' capability; the attribute should be defined in one file or the other, but not both.
// The following example shows how
// to generate this error.
class X {
a;
a;
}
Load the above code into UmpleOnline
An association generates a variable and methods that would clash with an attribute of the same name. If a role name is used, then it must be distinct from all attributes. If no role name is used then the class name (with first character converted to lower case) at the 'other end' of the association must be distinct from all attributes.
Ths problem can sometimes be hard to notice if an association is declared 'backwards' in the 'other' class, or independently of either class. It is especially tricky if the clashing association or attribute is in a separate mixin.
// This example generates error 23
// because an attribute and role name share a name
class X23atdupassoc1 {
a;
1 -- 0..1 Another a;
}
class Another {}
Load the above code into UmpleOnline
// This generates error 23 because
// attribute b clashes with
// class name B in the association
class X23atdupassoc2 {
b;
1 -- 0..1 B;
}
class B {}
Load the above code into UmpleOnline
The sort key for an sorted association must have one of the simple types Integer, Short, Long, Double, Float or String. This allows sensible code to be generated for comparisons. The set of allowed types may be expanded in the future.
// This example generates the error message
class X {
1 -- * Y sorted {endDate};
}
class Y {
Date endDate;
}
Load the above code into UmpleOnline
The sort key of a sorted association must be one of the attributes of the class at the other end of the association.
// This example generates the error message
class X {
* -- 1 Y sorted {nom};
}
class Y {
name;
}
Load the above code into UmpleOnline
If an item (attribute, association, state machine) appears twice in a key, it is an error, since Umple cannot tell the preferred order of items.
// The following example has error 26
// since the key has 'a' twice
class X26dupiteminkey {
a;
b;
key {a, b, a}
}
Load the above code into UmpleOnline
The list of identifiers in a key statement can include attributes, associations (role name for example) or state machines. This message indicates that the referenced identifier could not be found. This is usually the result of a typographical error. The extraneous identifier is ignored, which is likely to result in incorrect code.
// This example generates the message
class X27itemkeynotdef {
a;
key {b};
}
Load the above code into UmpleOnline
Currently, constraints can refer to attributes in the current class; in the future they will be able to refer to other model elements. This message indicates that an identifier referenced in the constraint was not found. This is often just due to a typographical error, but it might be due to the current limitations of constraints.
// This example generates the message
class X28attrconsrnotdef {
Integer a;
[b > 5]
}
Load the above code into UmpleOnline
It is only possible to compare a String to a String, a Boolean to a Boolean, and a number to a number, etc. Violations result in a type mismatch error.
// This example generates the message
class X29attrtypeconstr {
a;
[a > 5]
}
Load the above code into UmpleOnline
// The following shows how to avoid the message
class X29attrtypeconstr {
Integer a;
[a > 5]
}
Load the above code into UmpleOnline
Since a class can only be in one namespace, the last namespace declaration overides earlier ones. This can sometimes be useful, e.g. when creating a mixin to change the default location of a class. However, it is normally a sign of a mistake, hence the warning.
// This example generates the message
// Namespace b, encountered later, will
// be the namespace of the class
namespace a;
class X30redefnamespace {
}
namespace b;
class X30redefnamespace {
}
Load the above code into UmpleOnline
If you declare a namespace and then declare another before using the first namespace, this warning is issued. The reason for the warning is that this can happen accidentally, for example, if you add a namespace declaration before a comment and then add a different one after a comment, but before the class is declared.
// This example generates the message because
// namespace n is never used
namespace n;
namespace m;
class X21namespacenotused {}
Load the above code into UmpleOnline
In order to define a reflexive association, it is necessary to specify role names. There is a situation where it is possible to define a reflexive association with one role name. When this happens, Umple uses an implicit name for the second role name which is the plural form of the class name (e.g. if the class name is Computer, plural form would be computers). Therefore, if a user uses plural form of the class name as role name, Umple produces an error.
// This example generates the error message
class Course {
* -- * Course courses;
}
Load the above code into UmpleOnline
// The following shows how to avoid the error
class Course {
* -- * Course course_s ;
}
Load the above code into UmpleOnline
// This example generates the error message
class Course {
* courses -- * Course;
}
Load the above code into UmpleOnline
// The following shows how to avoid the error
class Course {
* course_s -- * Course;
}
Load the above code into UmpleOnline
When you declare a superclass of a class, that class must exist. If the class does not exist, then this warning is issued.
It might be the case that the class is in fact declared in some code that is defined externally. In that case, the existence of the external class should be made known to Umple using the external keyword, such as in the second example.
// This example generates the warning
// since T is not defined
class S {
isA T;
}
Load the above code into UmpleOnline
// This example solves the problem
// by defining T as an external class
// Umple will not generate any code for T,
// but now knows it exists
class S {
isA T;
}
external T {};
Load the above code into UmpleOnline
Umple does not currently support multiple inheritance, in order to be consistent with code generated in Java, and also to make models simpler.
// The following will generate this error
class P1 {}
class P2 {}
class Sub {
isA P1, P2;
}
Load the above code into UmpleOnline
// The following is another way of
// formulating the same declarations,
// also resulting in the error
class P1 {}
class P2 {}
class Sub {
isA P1;
isA P2;
}
Load the above code into UmpleOnline
// If all but one of the parents is
// declared as an Interface, the problem is solved
interface P1 {}
class P2 {}
class Sub {
isA P1;
isA P2;
}
Load the above code into UmpleOnline
It makes little sense to have a constant unless it is given a value. If a constant is of one of the built-in Umple data types we will set it to a default value: Integer, Double and Float will be set to zero, String will be set to an empty String, Boolean will be set to false, Date will be set to the date where the code was generated and Time will be set to midnight (00:00:00). However, the warning is issued since forgetting to initialize a constant is a common source of errors.
// The following will generate this warning
class X {
const String A; //same as const String a = "";
}
Load the above code into UmpleOnline
// The following will resolve the issue
class X {
const String A = "Something Interesting";
}
Load the above code into UmpleOnline
Umple generates code to manage the manipulation of the directed end (with the arrowhead) of a directed association. However there are no inverse references in such a case. In the example below, there are no references from class B to class X. As a result, the multiplicity on the undirected end is purely 'documentation'.
Specifying a hard constraint such as 1 or 2 for the upper or lower bound in such a case may be misleading and is typically incorrect. This error is raised whenever the multiplicity is other than * or 0..1
// The following will generate this warnbing
class X {
1 -> * B first;
1..3 -> * B second;
0..2 -> * B third;
}
class B {}
Load the above code into UmpleOnline
// The following solves the problem
// by either making the association unndirected
// or making the bounds have soft constraints
namespace W036UnmanagedMultiplicity2;
class X {
0..1 -> * B first;
* -> * B second;
0..2 -- * B third;
}
class B {}
Load the above code into UmpleOnline
It makes little sense to have a constant unless it is given a value. Since there is no obvious default value for arbitrary data types, it is an error to declare an uninitialized constant unless it is of one of the builtin Umple data types. (For builtin datatypes this is not a problem since a number can be initialized as zero by default, and a string as empty by default).
// This example generates error 37
class X {
const Y A;
}
class Y {
Integer a;
}
Load the above code into UmpleOnline
// This example resolves error 37
class X {
const Y A=new Y(3);
}
class Y {
Integer a;
}
Load the above code into UmpleOnline
Some attribute generate two variables, one representing the attribute itself, and one representing associated information. In particular an autounique attribute will generate a static variable prefixed with 'next' and an immutable attribute will generate a variable prefixed with 'canSet'. This error message occurs when conflicts with these occurs.
//The error is generated because of
//the name conflict between attr
//and the attribute canSetAttr,
//which is automatically generated
//for an immutable attribute
//The same occurs for the attr2
//and nextAttr2
class A {
immutable attr;
canSetAttr;
autounique attr2;
nextAttr2;
}
Load the above code into UmpleOnline
//The error can be fixed by
//modifying the names of the
//attributes
class A {
immutable attr;
otherAttr;
autounique attr2;
otherAttr2;
}
Load the above code into UmpleOnline
If an interface extends a second interface, that second interface must exist in the system. It can also be declared as external to the class, if it has been defined externally to the code.
//Since B is not defined,
//the warning will be generated
interface A {
isA B;
}
Load the above code into UmpleOnline
//The problem can be solved by
//defining B
interface A {
isA B;
}
interface B {}
Load the above code into UmpleOnline
Singleton is a software pattern to allow only one instance of a class. A singleton class has a private constructor and cannot be inherited.
// In this example a singleton class
// has subclasses and it generates an error
class Airplane
{
singleton;
}
class F16
{
isA Airplane;
}
Load the above code into UmpleOnline
//I this example the singleton class
// does not have a subclass and is correct
class Airplane
{
}
class TheAirplane
{
singleton;
}
class F16
{
isA Airplane;
}
Load the above code into UmpleOnline
The queued keyword cannot be used on methods with a non-void return type. Declare the method as 'queued void' or 'void'.
//Causes the error due to the return type of
//method1 being Integer
class A
{
queued Integer method1() { /* implementation */ }
}
Load the above code into UmpleOnline
//No error is raised, as both methods
//have a void return type
class A
{
queued method1() { /* implementation */ }
queued void method2() { /* implementation */ }
}
Load the above code into UmpleOnline
If you declare an entity in the default namespace and then declare another entity that extends, implements, or has an association with the first entity, this warning is issued. The reason for the warning is that if two related entities are in different namespaces, import will be generated for those entities, and many programming laguages do not support import from the default namespace. Therefore, the namespace for entities in the default namespace will be changed.
// Classes A, B and C are in the
// default namespace. Class D is in
// namespace m. All these classes are
// linked to each other via associations,
// therefore, and because they are not all
// in the same namespace, an import text
// will be generated. However, many programming
// languages do not support import from
// the default namespace so the namespace of
// C will become m because it is linked to
// D, and the same goes for B because C is
// now in namespace m, and then A is placed
// in m because B is now in m.
class A{}
class B{*--*A;}
class C{*--* B;}
namespace m;
class D{*--* C;}
namespace -;
// The same issue occurs when an
// entity in a non-default namespace
// extends or implements an entity
// in the default namespace
interface E{}
interface F{isA E;}
interface J{isA F;}
namespace n;
interface K{isA J;}
// Here an import text will be generated for D in X
// because D is in a different namespace
// This feature is not yet supported for interfaces
// and the import text will not be generated for K in Y
namespace p;
class X{isA D;}
// interface Y{isA K;}
Load the above code into UmpleOnline
The purpose of this warning is to alert the developer that they have to resolve the issue by changing the name of the duplicated attribute in either the superclass or subclass, or else remove one of them entirely, as you should not define an attribute twice with a different type.
// This example generates the warning message
class A {
Integer attr;
}
class B {
isA A;
attr;
}
Load the above code into UmpleOnline
//This example solves the problem
class A {
Integer attr;
}
class B {
isA A;
differentAttr;
}
Load the above code into UmpleOnline
If an attribute is given an initial value and is part of a key, then there is potential for keys of all instances of a class to be the same, meaning that they would be treated as equal and would have the same hash value. It is unlikely that a developer intends for this to be the case, so a warning is thrown to inform them of this behaviour.
// This example generates the message
class X {
Integer z = 1;
key { z }
}
Load the above code into UmpleOnline
// The following shows how to avoid the message
class X {
Integer z;
key { z }
}
Load the above code into UmpleOnline
Template types do not follow Umple modelling conventions. Umple encourages users to take full advantage of associations in their modelling, which in almost all contexts replace the need for template types. Multivalued attributes can also be used.
// This example generates the message
class A {
depend java.util.List;
List<OtherClassA> otherClassGroup;
}
class OtherClassA {}
Load the above code into UmpleOnline
// The following shows how to avoid
// the message using a multivalued attribute
class B {
OtherClassB[] otherClassGroup;
}
class OtherClassB {}
Load the above code into UmpleOnline
// The following shows how to avoid
// the message using an association
class C {
0..1 -- * OtherClassC;
}
class OtherClassC {}
Load the above code into UmpleOnline
An empty key statement has no meaning, but Umple will detect the key statement and generate methods associated with having a key. This might lead the developer to think that they have defined a key, when in fact the generated methods cannot differentiate between instances of the class in question. The warning is shown to notify the developer of the potential mistake.
// This example generates the message
class A {
id;
key { }
}
Load the above code into UmpleOnline
// The following shows how to avoid the message.
class A {
id;
key { id }
}
Load the above code into UmpleOnline
An attribute may autogenerate multiple methods, which can lead to duplicates if the methods have already been generated. Changing the name of the attribute causing the duplicate can fix the error.
//The error will be issued, attr
//and Attr both generating setAttr
//and getAttr causing a name conflict
class A {
attr;
Attr;
}
Load the above code into UmpleOnline
//The following example is a
//way to fix the error
class A {
attr;
attr2;
}
Load the above code into UmpleOnline
You cannot have two methods that have the same names and return types. The warning is shown to notify the developer of the potential mistake.
// This example generates the message
class A{
String test1(){return("hello world");}
String test1(){return("dlrow olleh");}
}
Load the above code into UmpleOnline
// The following shows how to avoid the message.
class A{
void test1() Java {}
void test2() Java {}
void test1() Python { ''' code here ''' }
void test2() Python { ''' code here ''' }
}
Load the above code into UmpleOnline
An end state (with no outgoing transitions) is generated. The purpose of the warning is to alert the developer that they may have a typographical error in the target state name.
// This example generates the error message
class X {
sm {
s1 {
e1 -> s2;
}
}
}
Load the above code into UmpleOnline
// This example solves the problem
class X {
sm {
s1 {
e1 -> s2;
}
s2 {}
}
}
Load the above code into UmpleOnline
When parameters are specified on a state machine event, all transitions with the same event name must have identical parameters, both in name and type. The reason for this is that there is only one event method generated.
// This example generates the error message
class X {
sm {
s1 {
e1(String s) -> s2;
}
s2 {
e1(Float f) -> s2;
}
}
}
Load the above code into UmpleOnline
// This example solves the problem
class X {
sm {
s1 {
e1(String s) -> s2;
}
s2 {
e1(String s) -> s2;
}
}
}
Load the above code into UmpleOnline
Since, in effect, a state machine defines a special kind of attribute (whose value is enumerated as one of the states and is controlled by events) it is not allowed to have an attribute or association with the same name as a state machine.
// This example generates the message
// because the state machine a
// clashes with the attribute a
class X52assattnamestatemachine1 {
a;
a {
s1 {}
s2 {}
}
}
Load the above code into UmpleOnline
// The sample generates the message
// because the state machine a
// clashes with the association role name a
class X52assattnamestatemachine2 {
1 -- 0..1 B a;
a {
s1 {}
s2 {}
}
}
class B {}
Load the above code into UmpleOnline
A state machine must be in one top level state at all times. Concurrent substates can exist in any substate at any level, but not directly in a top level state. The second example below shows how this can be handled simply by adding a level of nesting.
If the intent is simply to create concurrent do activities, an alternative is to use Umple's active objects notation.
// This example generates the message
class X53conctoplevel {
sm {
s1 {
do {System.out.println(
"Reached s1");}
}
||
s2
{
do {System.out.println(
"Reached s1");}
}
}
}
Load the above code into UmpleOnline
// The following shows how to avoid the message
class X53conctoplevel {
sm {
s0 {
s1 {
do {System.out.println(
"Reached s1");}
}
||
s2
{
do {System.out.println(
"Reached s1");}
}
}
}
}
Load the above code into UmpleOnline
In the example below, the second transition e from s1 can never be triggered because when e occurs the first transition is taken.
class X {
sm {
s1 {
e-> s2;
e-> s3;
}
s2 {}
s3 {}
}
}
Load the above code into UmpleOnline
In the example below, the event e from the s1 superstate and the event e in the s1a substate are ambiguous. Current semantics is that the event in the superstate takes precedence, but this semantics may be changed.
class X {
sm {
s1 {
e-> s2;
s1a {
e-> s3;
}
}
s2 {}
s3 {}
}
}
Load the above code into UmpleOnline
A queued state machine must have events to be queued, or this warning will be issued.
//The warning will be generated
//as there are no events to be
//queued in the state machine sm
class A {
queued sm {
s0 {
}
s1 {
}
}
}
Load the above code into UmpleOnline
//The following avoids the warning
//by adding an event to the state machine
class A {
queued sm {
s0 {
e -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
A pooled state machine must have events to be pooled, or this warning will be issued.
//The warning will be generated
//as there are no events to be
//pooled in the state machine sm
class A {
pooled sm {
s0 {
}
s1 {
}
}
}
Load the above code into UmpleOnline
//The following avoids the warning
//by adding an event to the state machine
class A {
pooled sm {
s0 {
e -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
An Umple class cannot contain in the same class a queued state machine, a pooled state machine and/or a regular state machine.
All the state machines in a given class must be of the same type (pooled, queued, regular), or could be distributed in different classes.
//The error will be generated as A
//contains a queued, pooled and
//regular state machine at once
class A {
pooled sm1 {
s0 {
e -> s1;
}
s1 {
}
}
queued sm2 {
s0 {
e -> s1;
}
s1 {
}
}
sm3 {
}
}
Load the above code into UmpleOnline
//The error can be fixed by having each
//state machine in a different class
class A {
pooled sm1 {
s0 {
e -> s1;
}
s1 {
}
}
}
class B {
queued sm2 {
s0 {
e -> s1;
}
s1 {
}
}
}
class C {
sm3 {
}
}
Load the above code into UmpleOnline
An Umple class cannot contain both a queued state machine and a pooled state machine.
The state machines must be of the same type (all pooled, or all queued) or else could be distributed in more than one class.
//The error will be generated as
//class A contains both a queued
//and a pooled state machine
class A {
pooled sm1 {
s0 {
e -> s1;
}
s1 {
}
}
queued sm2 {
s0 {
e -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
//The error can be fixed by having each
//state machine in a different class
class A {
pooled sm1 {
s0 {
e -> s1;
}
s1 {
}
}
}
class B {
queued sm2 {
s0 {
e -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
An Umple class cannot contain both a pooled state machine and a regular state machine.
The state machines must be of the same type (e.g. both pooled), or else distributed in more than one class.
//The error will be generated as
//class A contains both a regular
//and a pooled state machine
class A {
pooled sm1 {
s0 {
e -> s1;
}
s1 {
}
}
sm2 {
s0 {
e -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
//The error can be fixed by having each
//state machine in a different class
class A {
pooled sm1 {
s0 {
e -> s1;
}
s1 {
}
}
}
class B {
sm2 {
s0 {
e -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
An Umple class cannot contain both a queued state machine and a regular state machine.
The state machines must be of the same type (e.g. both queued), or else distributed in more than one class.
//The error will be generated as
//class A contains both a regular
//and a queued state machine
class A {
queued sm1 {
s0 {
e -> s1;
}
s1 {
}
}
sm2 {
s0 {
e -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
//The error can be fixed by having each
//state machine in a different class
class A {
queued sm1 {
s0 {
e -> s1;
}
s1 {
}
}
}
class B {
sm2 {
s0 {
e -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
A pooled state machine cannot use the "unspecified" event in a transition. This is because the unspecified functionality is designed to handle events that occur unexpectedly, which only makes sense in a regular and pooled state machine. Pooled state machines instead just leave such events on the queue, and process events further back in the queue.
In a pooled state machine, an event with the "unspecified" label is treated as a regular event and will be pooled.
To catch and immediately process unspecified events, a queued or regular state machine could be used instead.
//The warning is generated for
//sm due to the use of the unspecified
//event
class A {
pooled sm {
s0 {
unspecified -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
//The warning can be avoided by using
//a queued state machine to be able
//to use the unspecified event
class A {
queued sm {
s0 {
unspecified -> s1;
}
s1 {
}
}
}
Load the above code into UmpleOnline
Certain state names in Umple are reserved for the implementation of history and deep history states.
An error is raised when using a reserved name such as H or HStar as a state name.
//The error occurs as state machine
//sm uses the reserved name H as a
//state name
class A {
sm {
H {
}
}
}
Load the above code into UmpleOnline
//The error can be avoided by
//using a non reserved state
//name
class A {
sm {
s1 {
}
}
}
Load the above code into UmpleOnline
A transition to the history of a state must be declared on an existing state for Umple to be able to complete the
transition to its stored history state.
The error will be raised if the state is not found in the state machine.
//The following generates the error,
//OtherState not existing within sm
class A {
sm {
s1 {
e -> OtherState.H;
}
}
}
Load the above code into UmpleOnline
//The error can be resolved by
//declaring OtherState in sm
class A {
sm {
s1 {
e -> OtherState.H;
}
OtherState {
OtherStateA {
}
/* ... other substates */
}
}
}
Load the above code into UmpleOnline
A transition to a history state can only be declared on a state with substates, as a state with no substates
has no history to be managed.
//The error is generated because
//s2 does not contain a substate
//and therefore no history to
//be managed
class A {
sm {
s1 {
e -> s2.H;
}
s2 {
}
}
}
Load the above code into UmpleOnline
//The following does not generate
//the error as s2 contains substates
//and can keep the last substate in
//memory
class A {
sm {
s1 {
e -> s2.H;
}
s2 {
s2a {
}
s2b {
}
/* ... more substates */
}
}
}
Load the above code into UmpleOnline
If a transition's destination state name has multiple occurrences in the state machine,
this warning will be issued, as it is possible the developer means to reference a specific
substate of the same name. The dot notation should be used to clarify which substate is
intended to be the destination state.
The transition destination is by default the highest level state in the state machine.
In the case of multiple states at the same level using the same state name,
Umple currently assumes the state that has been defined first is being referenced.
//The following generates the warning
//as s1 could designate both s1 and s2.s1
//By default, it is s1
class A {
sm {
s1 {
e -> s1;
}
s2 {
s1 {
}
}
}
}
Load the above code into UmpleOnline
//The warning does not occur
//by removing the ambiguity
class A {
sm {
s1 {
e -> s2.s1;
}
s2 {
s1 {
}
}
}
}
Load the above code into UmpleOnline
A state that is never the destination state of a transition in the state machine or is not
the initial state of the state machine is considered non-reachable by the Umple compiler.
The generated methods will not assign this state to the machine.
The warning can be avoided by removing the non-reachable state or by adding an
appropriate transition to the state machine.
//The warning is generated for
//s3, as no transition leads to it
class A {
sm {
s1 {
e -> s2;
}
s2 {
}
s3 {
}
}
}
Load the above code into UmpleOnline
//The warning can be avoided
//by adding a transition with s3
//as destination state
class A {
sm {
s1 {
e -> s2;
}
s2 {
e2 -> s3;
}
s3 {
}
}
}
Load the above code into UmpleOnline
When using dot notation to define the destination state of a transition in a nested state machine (e.g. sm1.s2), then the destination state must exist, otherwise the transition
will be ignored. The warning is most likely caused by a typographical error. (Note that when not using dot notation, behaviour is a bit different, and a new end state will be created by default with warning 50).
The warning can be resolved by correcting the destination state name or by creating the state.
//The warning is generated due
//to the transition destination
//of e -> s3.s2a not being defined in sm
class A {
sm {
s1 {
e -> s3.s2a;
}
s2 {
s2a {
}
}
}
}
Load the above code into UmpleOnline
//The following example does
//not generate the warning
//as s2.s2a is found in sm
class A {
sm {
s1 {
e -> s2.s2a;
}
s2 {
s2a {
}
}
}
}
Load the above code into UmpleOnline
An auto-transition in a state that is declared after another auto-transition will be ignored, and only the
first auto-transition will be executed. No warning is issued if the destination state
of both auto-transitions is the same.
//The warning is generated due
//to the auto-transition to s2
//conflicting with the auto-
//transition to s3
class A {
sm {
s1 {
entry /{doSomething();}
-> s2;
do {doSomethingElse();}
-> s3;
}
s2 {
}
s3 {
}
}
void doSomething() {}
void doSomethingElse() {}
}
Load the above code into UmpleOnline
//The warning is avoided here
//by keeping only one auto-
//transition
class A {
sm {
s1 {
entry /{doSomething();}
do {doSomethingElse();}
-> s2;
}
s2 {
}
}
void doSomething() {}
void doSomethingElse() {}
}
Load the above code into UmpleOnline
In some programming languages like Java, you cannot have the same method name for multiple methods even if the return types are different. The warning is shown to notify the developer of the potential mistake.
// This example generates the message
class A{
String test1(){return("hello world");}
int test1(){return(1);}
}
Load the above code into UmpleOnline
// The following shows how to avoid the message.
class A{
void test2(){}
Integer test1(){}
}
// @@@skipcompile no return from test1
Load the above code into UmpleOnline
In Umple, final states are allowed to be empty, or they can contain entry actions.
// The following shows how to generate the warning
class InvalidFinalState {
status{
on{
turnoff -> off;
powerOff-> FINAL;
}
off{
turnOn -> on;
}
final FINAL{
entry/{entry();}
do{exe();}
reboot -> on;
nestedSm {
s1 {
-> s2;
}
s2 {
}
}
exit/{exit();}
}
}
}
// @@@skipcompile no method entry written for line 15
Load the above code into UmpleOnline
// The following shows how to avoid the warning
class X {
status{
on{
turnoff -> off;
powerOff-> FINAL;
}
off{
turnOn -> on;
}
final FINAL{
entry/{entry();}
}
}
}
// @@@skipcompile no method entry written line 13
Load the above code into UmpleOnline
// The following shows how to avoid the warning
class X {
status{
on{
turnoff -> off;
powerOff-> FINAL;
}
off{
turnOn -> on;
}
final FINAL{
}
}
}
Load the above code into UmpleOnline
In Umple, parallel state machines within the same composite state must have different names.
// The following example generates the error
// "s1" has two parallel state machines that are named "t1"
class X {
sm{
s1{
t1{
goT2-> t2;
}
t2{ }
||
t1{
goT4-> t4;
}
t4{}
}
}
}
Load the above code into UmpleOnline
// The following example shows how to avoid the error
class X {
sm{
s1{
t1{
goT2-> t2;
}
t2{ }
||
t3{
goT4-> t4;
}
t4{}
}
}
}
Load the above code into UmpleOnline
In Umple, 'Final' is a reserved keyword. It is used to define the final state for the top-level state machine.
// The following example generates the error
// "s1" has a state named "Final"
class X {
sm {
s1 {
Final {}
}
}
}
Load the above code into UmpleOnline
// The following example does not generate the error
class X {
sm {
s1 {
goToFinal-> Final;
}
}
}
Load the above code into UmpleOnline
In Umple, 'timer' cannot be used as a state machine name. This is because generated code for 'after' statements creates timers and there would be a naming conflict in the generated code. To fix the problem, give the state machine a slightly different name,
class X {
timer {
s1 {
after(1) -> s2;
}
s2 {
}
}
}
Load the above code into UmpleOnline
class X {
sm_timer {
s1 {
after(1) -> s2;
}
s2 {
}
}
}
Load the above code into UmpleOnline
An association with an abstract class must either be a directed association or must have a multiplicity with lower bound
of zero at both ends. This is necessary to prevent situations where it would be needed to instantiate the abstract class (which
is never allowed).
//Class A contains an association
//with abstract class B, causing
//the error by using mandatory
//multiplicity
class A {
1 -- 1 B;
}
abstract class B{
abstract;
}
Load the above code into UmpleOnline
//The following association does not
//cause the error
class A {
0..1 -- 0..1 B;
}
abstract class B{
abstract;
}
Load the above code into UmpleOnline
When indicating initial values for a multivalued attribute, an error is raised if the values to
assign cannot be parsed properly.
The error might be caused by a typographical mistake.
//The attribute attr cannot be initialized
//as the values are not correct
class A {
String[] attr = {invalid.values};
}
Load the above code into UmpleOnline
//attr can now be initialized
class A {
String[] attr = {"valid", "values"};
}
Load the above code into UmpleOnline
This warning is shown when conflicting method modifiers are provided for state-dependent methods. The example below illustrates this scenario by marking the method 'printState' as both public and private.
// The following shows how to generate the warning
class ConflictingModifiers {
status{
on{
turnoff -> off;
public void printState() {
System.out.println("on");
}
}
off{
private void printState() {
System.out.println("off");
}
}
}
}
Load the above code into UmpleOnline
When indicating initial values for a multivalued attribute, an error is raised if the values to
assign cannot be parsed properly.
The error might be caused by a typographical mistake.
// For derived attributes remove list indicator []
// For list initializer, there should be a semicolon on the end
class Office {
Integer number;
String[] emails = {"abc@umple.org", "def@umple.org"}
Integer [] incomingNumber = {765432, 987654}
}
Load the above code into UmpleOnline
//emails and incomingNumber can now be initialized
class Office {
Integer number;
String[] emails = {"abc@umple.org", "def@umple.org"};
Integer [] incomingNumber = {765432, 987654};
}
Load the above code into UmpleOnline
The role name of an association is used to explain how a class participates in a relationship.
A role name that matches the class name may be unnecessary, since it provides little clarification as to the relationship between the classes.
This warning can be avoided by removing or changing the role name.
Note that in certain cases this could raise syntactic errors such as E019.
//This example generates the warning message
class Person {
name;
}
class Intern {
isA Person;
* -- 0..2 Employee employee;
}
class Employee {
isA Person;
}
Load the above code into UmpleOnline
//This example shows how to avoid the warning
class Person {
name;
}
class Intern {
isA Person;
* -- 0..2 Employee supervisor;
}
class Employee {
isA Person;
}
Load the above code into UmpleOnline
Model constraints can be applied to Umple classes to ensure they respect certain properties, as defined in their constraints.
This error is raised if a class does not contain an attribute with a name specified in the constraint.
The attribute might have been defined in a separate file previously, but no longer exists, causing the error.
//Class A does not contain
//the appropriate attribute,
//the constraint causes the error
class A {
[model: A has attribute named attr]
}
// @@@skipcompile
Load the above code into UmpleOnline
//The class A now contains an
//attribute with the appropriate name
class A {
attr;
[model: A has attribute named attr]
}
Load the above code into UmpleOnline
Model constraints can be applied to Umple classes to ensure they respect certain properties, as defined in their constraints. This error is raised if a class does not contain an attribute of a specified type in the constraint.
//The error is raised, A does
//not contain an attribute of
//type B
class A {
[model: A has attribute of B]
}
class B {
}
Load the above code into UmpleOnline
//A now contains an
//attribute of type B
class A {
B attr;
[model: A has attribute of B]
}
class B {
}
Load the above code into UmpleOnline
Model constraints can be applied to Umple classes to ensure they respect certain properties, as defined in their constraints. This error is raised if a class is not the subclass of a given class as expected from the constraint.
//The error occurs as A
//does not respect the constraint
//Alternative syntax is indicated
//in comments
class A {
//[model: A child of B]
//[model: A inherits from B]
[model: A isA B]
}
class B {
}
Load the above code into UmpleOnline
//A respects the constraint
//and avoids the error
class A {
isA B;
[model: A isA B]
}
class B {
}
Load the above code into UmpleOnline
Model constraints can be applied to Umple classes to ensure they respect certain properties, as defined in their constraints. This error is raised if a class is not the superclass of a given class as expected from the constraint.
//The error is produced, the
//constraint is not respected because
//A is not a superclass of B
//Alternative syntax in comment
class A {
//[model: A parent of B]
[model: A superclass B]
}
class B {
}
Load the above code into UmpleOnline
//The constraint is now respected
//and the error does not occur
class A {
[model: A superclass B]
}
class B {
isA A;
}
Load the above code into UmpleOnline
Model constraints can be applied to Umple classes to ensure they respect certain properties, as defined in their constraints. This error is raised if an association required by a constraint is not found in the class. The multiplicity can optionally be specified.
//The class A generates the error
//by not containing the required
//association
class A {
[model: A -- B]
}
class B {
}
Load the above code into UmpleOnline
//The error is not generated
//A contains an association
//fulfilling the requirements
//of the constraint
class A {
0..1 -- *B;
[model: A -- B]
}
class B {
}
Load the above code into UmpleOnline
In Umple, enumerations must have unique names.
// This example causes the error
enum Month {x,y,z}
enum Month {o,p,q}
class A{
Month m;
Month p;
}
Load the above code into UmpleOnline
// This example causes the error
class A{
enum Month {x,y,z}
enum Month {o,p,q}
}
Load the above code into UmpleOnline
// This example does not cause the error.
// The enumeration within the class
// is prioritized over the enumeration
// defined outside of the class
enum Month {x,y,z}
class A{
enum Month {o,p,q}
Month m;
Month p;
}
Load the above code into UmpleOnline
In Umple, class enumerations must not have the same name as the class they are defined in. Model level enumerations must have unique names.
// This example generates the error
// since the enumeration "X" will be added
// to the class "X" because of attribute "t".
enum X{ Red, Blue, Green }
class X{
X t;
}
Load the above code into UmpleOnline
// This generates the error
// because the enumeration "X"
// has the same name
// as the class it's defined in
class X{
enum X { Red, Blue, Green }
}
Load the above code into UmpleOnline
// This example generates the error
// since enumeration "Y"
// conflicts with interface "Y"
interface Y {
name;
}
class X {
isA Y;
}
enum Y { Red, Blue, Green }
Load the above code into UmpleOnline
// This example generates the error
// since enumeration "Y" conflicts with trait "Y"
class X {
isA Y;
}
trait Y {
name;
}
enum Y { Red, Blue, Green }
Load the above code into UmpleOnline
// This example does not generate the error
enum Z { Orange, Yellow }
class X {
enum Y { Red, Blue, Green }
Z attr;
}
Load the above code into UmpleOnline
In Umple, enumerations and state machines within the same class cannot have the same name.
// This example generates the error
// because enumeration "Y" has the
// same name as state machine "Y"
class X {
enum Y { Red, Blue, Green }
Y {
s1 {
goToS2 -> s2;
}
s2 { }
}
}
Load the above code into UmpleOnline
// This example generates the error
// because enumeration "Y" will be
// added to class "X" since the "attr"
// parameter of "showY" is "Y".
enum Y { Red, Blue, Green }
class X {
showY(Y attr) {
System.out.println(attr); }
Y {
s1 {}
}
}
Load the above code into UmpleOnline
// This example does not generate the error
class X {
enum Y { Red, Blue, Green }
Z {
s1 {
goToS2 -> s2;
}
s2 { }
}
}
Load the above code into UmpleOnline
In Umple, identifiers used for classes, association role names, types, attributes, state machines, states, events and other elements must be alphanumeric. In addition, class and interface names should start with a capital letter (or _), and other elements should start with a lower case letter. The exact error message you received will tell you which identifier has the problem. The examples below will generate these messages.
// Class with non-alphanumeric name (100)
class @ {}
Load the above code into UmpleOnline
// Warnings from attribute starting with
// upper case letter (131)
class X {
Attrib;
}
class Y {}
Load the above code into UmpleOnline
// Attribute name with special characters (130)
class X {
na$me;
}
Load the above code into UmpleOnline
// Attribute name with special characters
// that looks like an association (132)
// If this is supposed to be an association,
// put spaces before and after the -- and *
class X {
1--*Y;
}
class Y {}
Load the above code into UmpleOnline
// Attribute type with special characters
// that looks like an association (140)
// If this is supposed to be an association,
// put spaces before and after the --
class X {
1--* Y;
}
class Y {}
Load the above code into UmpleOnline
// State machine name with special
// characters (150)
class X {
ed%4 {
s1 {}
}
}
Load the above code into UmpleOnline
// State name with special characters (152)
class X {
ed4 {
s*1 {}
}
}
Load the above code into UmpleOnline
// This example generates the warning
// because it is ambiguous if "param"
// is an object of class "Y" or
// the enumeration "Y".
class X {
enum Y { Red, Blue, Green }
showY(Y param) {
System.out.println(param); }
}
class Y { }
Load the above code into UmpleOnline
// This example does not generate the warning
class X {
enum Y { Red, Blue, Green }
showY(Y param) {
System.out.println(param); }
}
class Z { }
Load the above code into UmpleOnline
// This example does not generate the warning
enum Z { Red, Blue, Green }
class X {
showY(Y param) {
System.out.println(param); }
}
class Y { }
Load the above code into UmpleOnline
// This example generates the warning
// because "goToS2" has "param" which could be
// either an object of class "Y"
// or the enumeration "Y"
class X {
enum Y { Red, Blue, Green }
sm {
s1 {
goToS2(Y param) /{
System.out.println(param); } -> s2;
}
s2 {}
}
}
class Y { }
Load the above code into UmpleOnline
// This example does not generate the warning
class X {
enum Y { Red, Blue, Green }
sm {
s1 {
goToS2(Y param) /
{ System.out.println(param); } -> s2;
}
s2 {}
}
}
class Z { }
Load the above code into UmpleOnline
In Umple, enumerations cannot be used in bi-directional associations.
// This example generates the error
class X {
enum Y { Red, Blue, Green }
0..1 -- * Y;
}
class Y{ }
Load the above code into UmpleOnline
// This example does not generate the error
class X {
enum Y { Red, Blue, Green }
0..1 -- * Z;
}
class Z { }
Load the above code into UmpleOnline
In Umple, enumerations cannot be used in compositions.
// This example generates the error
class X {
enum Y { Red, Blue, Green }
0..1 <@>- * Y;
}
class Y {
name;
}
Load the above code into UmpleOnline
// This example does not generate the error
class X {
enum Y { Red, Blue, Green }
0..1 <@>- * Z;
}
class Z {
name;
}
Load the above code into UmpleOnline
// This example generates the warning
class X {
enum Y{ Red, Blue, Green }
0..1 -> * Y;
}
class Y { }
Load the above code into UmpleOnline
// This example generates the warning
class X {
enum Y{ Red, Blue, Green }
0..1 <- * Y;
}
class Y { }
Load the above code into UmpleOnline
// This example does not generate the warning
class X {
enum Y { Red, Blue, Green }
0..1 -> * Z;
}
class Z { }
Load the above code into UmpleOnline
Constants in an attribute must have distinct names. The solution to this error is to rename or delete one of the constants.
// The following example shows how to generate
// this error.
interface X {
const A="dog";
const A="cat";
}
Load the above code into UmpleOnline
Numbers must be initialized with numbers, strings with strings in double quotes, and Booleans with true or false. For Dates the value format is a string "yyyy-mm-dd"; for Times the format is "hh:mm:ss".
Note that for an initialization value with no type specified will result in the attribute having its type inferred from the value. This is demonstrated in the third example.
// The following will generate
// this warning on every line of the class
class X {
Date d = "20130708";
Integer i = "abc";
String s = 123;
Boolean b = 1;
Time t = "120000";
}
Load the above code into UmpleOnline
// The following shows how to solve the above problem
class X {
Date d = "2013-07-08";
Integer i = 7;
String s = "123";
Boolean b = true;
Time t = "12:00:00";
}
Load the above code into UmpleOnline
// The following shows how to solve
// the above problem not even showing the type at all
class X {
d = "2013-07-08";
i = 7;
s = "123";
b = true;
t = "12:00:00";
m = 2.3;
}
Load the above code into UmpleOnline
Umple attributes do not support visibility specifiers such as public, private and protected. An attribute is private by default, and programmers are supposed to use the corresponding generated get method to read it, or the set method to modify it.
This warning appears when one of the visibility keywords precedes an attribute.
// This case raises the warning
// because it is probably an error
// Umple will consider "x" to have type "public"
class X {
public x;
}
Load the above code into UmpleOnline
// This is probably what was intended,
// attributes have private access by default
// but the programmer would call
// public String getX() to read it
// and public boolean setX(String) to set it
class X {
x;
}
Load the above code into UmpleOnline
// Although not recommended, the programmer
// can also bypass Umple and directly specify
// both the visibility directive and the type.
// Umple will not see that as an attribute
// and will inject the line of code into the
// output directly.
class X {
public String x;
}
Load the above code into UmpleOnline
A subclass can not have an association with the same role name as an association of its superclass, unless it is a valid specialization. A valid specialization would be to the same class, but with a refined multiplicity (see the second example)
class Person {
* -> * Person friends;
}
class Student {
isA Person;
* -> * Dog friends;
}
class Dog {
}
Load the above code into UmpleOnline
// This example shows a valid specialization
// of the friends association in which the
// multiplicity 0..3 is refined to 0..2, so a
// person in general may have 0 to 3 dogs but
// students are limited to 2.
// This conforms to the Liskov substitution
// principle: The data invariant on Person
// which limits them to 3 dogs
// is still true in the subclass Student.
class Person {
* -> 0..3 Dog friends;
}
class Student {
isA Person;
* -> 0..2 Dog friends;
}
class Dog {
}
Load the above code into UmpleOnline
When performing an Association Specialization, the multiplicities are more specific than that of the previously defined association.
If the multiplicities on either side of the specialized association are less strict/specific, the association is considered invalid and this error is raised.
If you intend to perform specialization, this error can be avoided by narrowing the multiplicity to be more specific than that of the superclass association.
If you did not intend to perform specialization, you may have reused a rolename in the association. See E019.
// This example generates the error
class Vehicle {}
class Wheel {}
class Bicycle {isA Vehicle;}
// Parent multiplicity of 0..1 to 0..2
association { 0..1 Vehicle vehicleA -- 0..2 Wheel vehicleWheel;}
// Broader child multiplicity of 0..1 to 0..3
association { 0..1 Bicycle vehicleA -- 0..3 Wheel vehicleWheel;}
Load the above code into UmpleOnline
// This example shows how to resolve the error
class Vehicle {}
class Wheel {}
class Bicycle {isA Vehicle;}
// Parent multiplicity of 0..1 to 0..2
association { 0..1 Vehicle vehicleA -- 0..2 Wheel vehicleWheel;}
// Narrower child multiplicity of 0..1 to 0..1
association { 0..1 Bicycle vehicleA -- 0..1 Wheel vehicleWheel;}
Load the above code into UmpleOnline
In Umple, identifiers used for traits must be alphanumeric. It means that must start with an alpha character, or _ .
//This example shows an error
// in the name of trait
trait T@ {
//traits elements
}
Load the above code into UmpleOnline
//This example shows an error
// in the name of trait
trait 1T {
//traits elements
}
Load the above code into UmpleOnline
//This example shows a valid name for the trait
trait Color {
//traits elements
}
Load the above code into UmpleOnline
//This example shows a valid name of traits
trait Equality {
//traits elements
}
Load the above code into UmpleOnline
In Umple, identifiers used for traits, classes and interfaces should start with a capital letter (or "_"), and other elements should start with a lower case letter.
// This example shows a warning
// in the name of traits because
// they start with lower case.
trait color {
//traits elements
}
trait equality{
//traits elements
}
// @@@skipcompile no code
Load the above code into UmpleOnline
//This example shows a valid name for the trait
trait Color {
//traits elements
}
Load the above code into UmpleOnline
//This example shows a valid name of traits
trait Equality {
//traits elements
}
Load the above code into UmpleOnline
In Umple, when traits are used inside of classes or traits they have to be defined. The Umple compiler does not allow the use of traits that are not defined in the system.
//In this example, trait "T"
// uses trait "T1" which is not available.
interface I{
//elements
}
class A {
isA I;
isA T;
}
trait T{
isA T1;
}
Load the above code into UmpleOnline
//In this example, the error
// has been resolved just by
// defining trait T1.
interface I{
//elements
}
class A {
isA I;
isA T;
}
trait T{
isA T1;
}
trait T1{
//elements
}
Load the above code into UmpleOnline
In Umple, all elements which are capable of being reused should have unique identifiers. Traits, as reusable elements in Umple also have to follow the same rule. Identifiers of traits should be unique in the system. The conflict happens among classes, interfaces, and traits. Therefore, these three elements always should have unique identifiers.
// In this example, Identifier of
// trait "I" is not unique.
class A{
isA I;
}
class I {
//elements
}
trait I{
//elements
}
Load the above code into UmpleOnline
//In this example, Identifier of
// trait "T" is unique.
class A{
isA T;
}
class I {
//elements
}
trait T{
//elements
}
Load the above code into UmpleOnline
In Umple, traits cannot be used in an explicit or implicit cyclic way. It means that a trait cannot use itself and it also cannot be used in a cyclic use. This error happens when a trait extends itself.
// In this example, there is an explicit
// use of a trait inside of itself.
class A{
isA T;
}
trait T{
isA T;
}
Load the above code into UmpleOnline
In Umple, traits cannot be used in an explicit or implicit cyclic way. This means that a trait cannot use itself and it also cannot be used in a cyclic hierarchy. This error happens when a hierarchy is created completely based on traits. Moreover, this issue generally arises because of invalid design or error in typing a trait name.
// In this example, there is a cycle
// created in a hierarchy.
class A{
isA T;
}
trait T{
isA T1;
}
trait T1{
isA T;
}
Load the above code into UmpleOnline
If clients bind types to the template parameters of used traits and the types exist but they do not satisfy the constraints of the template parameters, this error is raised. The constraint is related to the implementation of interfaces.
// In this example, there is an error
// because class C1 does not implement
// interface I. Any bound value to template
// parameter TP must implement interface I.
trait T1<TP isA I>{
/*implementation*/
}
interface I{/*implementation*/}
class C1{/*implementation*/}
class C{
isA T1< TP = C1 >;
/*implementation*/
}
Load the above code into UmpleOnline
Traits need to have required methods in order to provide the functionality they have designed to provide. These required methods can provide special functionality or be a way of accessing states (attributes) in host classes. This error is raised when a required method is not available.
// In this example, the required method
// "FinalResult()" in Trait "T" is
// not satisfied by class "A".
class A{
isA T;
}
trait T{
Integer FinalResult();
void calculate(){
//method FinalResult() will be used here;
}
}
Load the above code into UmpleOnline
// In this example, the require method
// "FinalResult()" in Trait "T" is
// satisfied by class "A".
class A{
isA T;
internal Integer x;
Integer FinalResult(){
return x/100;
}
}
trait T{
Integer FinalResult();
void calculate(){
//method FinalResult() will be used here;
}
}
Load the above code into UmpleOnline
Traits can be used in several hierarchies without any priority. It means that classes can be composed of several traits and a trait can be composed of other traits. This brings cases in which two methods with the same signature come from either different traits or a different hierarchy path. If those methods come from two different traits, it is obvious that there is a conflict because those have been implemented for different purposes. On the other hand, if two methods come from two different paths but the source of those methods is the same trait, then there is no conflict. However, there is a case in which the source is the same but one of the methods is overridden by traits somewhere in the path. In this case, there is a conflict because now, the functionality is not unique. The Umple compiler detects these cases and raises this error.
// In this example, there is a conflict
// in class "A" on the method "test()".
class A{
isA T1;
isA T2;
}
trait T1 {
void test(){
//special implementation by T1
}
}
trait T2 {
void test(){
//special implementation by T2
}
}
Load the above code into UmpleOnline
// In this example, there is
// a conflict in trait "T"
// on the method "test()".
class A{
isA T;
}
trait T{
isA T1;
isA T2;
}
trait T1{
void test(){
//special implementation by T1
}
}
trait T2{
void test(){
//special implementation by T2
}
}
Load the above code into UmpleOnline
// In this example, there is a
// no conflict in class "A".
class A{
isA T1;
isA T2;
}
trait T1 {
isA M;
}
trait T2 {
isA M;
}
trait M{
void test(){
//special implementation by M
}
}
Load the above code into UmpleOnline
// In this example, there is a conflict
// in class "A" because method "test"
// is overridden in trait "T2".
class A{
isA T1;
isA T2;
}
trait T1 {
isA M;
}
trait T2 {
isA M;
void test(){
//special implementation by T2
}
}
trait M{
void test(){
//special implementation by M
}
}
Load the above code into UmpleOnline
When traits are used inside classes or traits, it is possible to add or remove provided methods. This feature is used to resolve conflicts and when we do not need some provided methods or just need one of them. Logically, it is not correct to add a method twice, or add and then remove a method. These problems are detected by the Umple compiler.
// In this example, there are
// two modifications ("add") for
// the method "show()" when trait "T2"
// is used inside of trait "T1".
class A{
isA T1;
}
trait T1{
isA T2 <+show(),+show()>;
}
trait T2{
void show(){
//implementation
}
}
Load the above code into UmpleOnline
// In this example, there are
// two modifications ("add" and "remove")
// for the method "show()" when trait "T2"
// is used inside of trait "T1".
class A{
isA T1;
}
trait T1{
isA T2 <-show(),+show()>;
}
trait T2{
void show(){
//implementation
}
}
Load the above code into UmpleOnline
When traits are used inside classes or traits, it is possible to add or remove provided methods, and to change their visibility and names. This feature is used to resolve conflicts when we do not need some provided methods, just need one of them, need different visibilty, or need a different name. Logically, it is not correct to do these operations on methods which are not available. These problems are detected by the Umple compiler.
// In this example, there is an error
// because trait "T1" tries to remove
// method "show()" from trait "T2"
// while it is not available
// in trait "T2".
class A{
isA T1;
}
trait T1{
isA T2 <-show()>;
}
trait T2{
}
Load the above code into UmpleOnline
// In this example, there is an error
// because trait "T1" tries to add
// just method "show()" from trait "T2"
// to itself. while it is not
// available in trait "T2".
class A{
isA T1;
}
trait T1{
isA T2 <+show()>;
}
trait T2{
}
Load the above code into UmpleOnline
// In this example, there is an error
// in class "A" because it tries to
// change visibility of method "test()"
// which is not available in trait T.
// Consider that the method "test()"
// defined in trait "T" is a
// required method.
class A{
isA T<test() as private>;
}
trait T{
void test();
}
Load the above code into UmpleOnline
Traits can make associations with interfaces, classes, and template parameters. If one end of the association is a template parameter, the binding type must be checked to make sure it is compatible with the type of the association. For example, if a trait has a bidirectional association with a template parameter, the binding value cannot be an interface and it must be a class. Breaking this constraint is reported to modelers using this error code.
// In this example, there is an error
// because a bidirectional association
// is created with interface I,
// which is not valid.
interface I {
/*implementation*/
}
trait T <RelatedClass> {
0..1 -- * RelatedClass;
/*implementation*/
}
class C{
isA T<RelatedClass=I>;
/*implementation*/
}
Load the above code into UmpleOnline
When defining traits, it is possible to define template parameters for traits. The names of these parameters should be unique in order to let the compiler perform the correct binding for them. Therefore, when there are two or more template parameters of the same name, the Umple compiler detects it as an error.
// In this example, there is an error
// because trait T has two template
// parameters with the same name.
trait T<TP,TP>{
TP name;
}
class C1{
isA T;
}
Load the above code into UmpleOnline
When using traits, we can bind types to template parameters. In the process of binding, we can just refer to the name of the parameters which are available. The Umple compiler detects cases in which there are template parameters that are not defined in a trait.
// In this example, there is an error
// because class A cannot bind
// type String to template parameter Y,
// which is not defined. for trait T.
class A{
isA T< X= Integer, Y = String>;
}
trait T<X>{
X variable;
}
Load the above code into UmpleOnline
When using traits, we can bind values for template parameters. In the process of binding, we can bind two values for a template parameter. This brings a case in which there is no clear binding. The Umple compiler detects this case and prevents the system from being compiled.
// In this example, there is an error
// because there are two bindings for
// template parameter "X" in class "A".
class A{
isA T< X = B , X = C >;
}
Class B{
//elements
}
Class C{
//elements
}
trait T<X,Z>{
//elements
}
Load the above code into UmpleOnline
We can define template parameters for traits and use them with different bindings in several hierarchy paths. If types of some attributes are based on template parameters, there is a case in which those are bound with different values. In a case that a trait is going to be used in a diamond form of hierarchy, this can result in a conflict. Note that if the types are the same, then there is no conflict.
// In this example, there is a
// conflict because in trait "T"
// there will be two attributes
// with the same name "data" but
// with different types
// which are "B" and "C".
class A{
isA T;
}
class B{
//elements
}
class C{
//elements
}
trait T{
isA T1;
isA T2;
}
trait T1{
isA Share<Type = B>;
}
trait T2{
isA Share<Type = C>;
}
trait Share<Type> {
Type data;
}
Load the above code into UmpleOnline
When classes uses traits, all attributes in traits are flattened in classes. Therefore, if there are attributes with the same name, they might create a conflict. The Umple compiler considers this as a warning, because it is the developers' responsibility to decide about the nature of the conflict. Sometimes, developers indicate exactly the same attributes and therefore there is no need to consider the conflict as an error. However, generally, if there are some attributes in host classes which traits need to use them, traits define them as required methods (needed accessors). In this case, host classes need to have accessors for those attributes. In the case of this warning, the Umple compiler just removes one of those attributes and proceeds.
// In this example, there is a warning
// because in class "A" there will be
// two attributes with the name called "name".
class A{
isA T;
name;
}
trait T{
name;
}
Load the above code into UmpleOnline
// In this example, there is a
// warning because in trait "T"
// there will be two attributes
// with the name called "name".
class A{
isA T;
}
trait T{
isA T1;
name;
}
trait T1{
name;
}
Load the above code into UmpleOnline
When defining traits, it is possible to define template parameters for traits. It means when traits with template parameters are going to be used by classes or traits, they must bind values for the parameters. If there is no binding for a parameter, the Umple compiler raises an error and shows which parameter does not have a value.
// In this example, there is an error
// because class "A" doesn't bind
// a value to one of the template
// parameters of trait "T" named "Y".
class A{
isA T<X = B>;
}
class B{
//elements
}
trait T<X,Y>{
//elements
}
Load the above code into UmpleOnline
// In this example, there is an error
// because class "A" doesn't bind
// a value to template parameters
// of trait "T".
class A{
isA T;
}
class B{
//elements
}
trait T<X,Y>{
//elements
}
Load the above code into UmpleOnline
When changing the name of provided methods in traits, it is necessary to be sure that there are no other methods with the same names that come from other traits. If the changed name already exists inside of a class, in this case there is no problem becase methods of classes have priority over ones coming from traits. In this case, the method from traits will be disregarded. Otherwise, there is a conflict on the name of methods. The Umple compiler detects this case and raises the error.
// In this example, there is an error
// because in class "A" there will be
// two methods with the name "ShowInConsole".
class A{
isA T<show() as ShowInConsole>;
}
trait T{
isA T1;
void show(){/*T*/}
}
trait T1{
void ShowInConsole(){/*T1*/}
}
Load the above code into UmpleOnline
// In this example, there is an error
// because in class "A" there will be
// two methods with the name "ShowInConsole".
class A{
isA T<show() as ShowInConsole>;
isA T1;
}
trait T{
void show(){/*T*/}
}
trait T1{
void ShowInConsole(){/*T1*/}
}
Load the above code into UmpleOnline
// In this example, there is no error
// because in class "A"
// method "ShowInConslole" has high priority.
class A{
isA T<show() as ShowInConsole>;
isA T1;
void ShowInConsole(){
//Implementation
}
}
trait T{
void show(){
//Implementation
}
}
trait T1{
void ShowInScreen(){
//Implementation
}
}
Load the above code into UmpleOnline
When using a trait with a template parameter, a type must be bound to that template parameter. If the bound type is not available in the system, the Umple compiler raises this error.
// In this example, there is an error
// because class C binds type C1 to the
// template parameter of trait T,
// while type C is not available
// in the system.
trait T<TP>{
/*implementation*/
}
class C{
isA T<TP=C1>;
/*implementation*/
}
Load the above code into UmpleOnline
When a class uses traits, it needs to implement the required interfaces of those traits, otherwise, the Umple compiler detects missing interfaces and raises this error code. If a trait uses other traits with required interfaces, those required interfaces are added to the set of required interfaces of the trait and final clients are required to implement all of those required interfaces as well.
// In this example, there is an error
// because class C must implement
// required interface of trait T,
// which is interface I.
trait T{
/*implementation*/
isA I;
}
interface I{
/*implementation*/
}
class C{
isA T;
/*implementation*/
}
Load the above code into UmpleOnline
If traits define template parameters and put constraints on them, the classes and interfaces involved in the constraints must exist in the system under design, otherwise, this error is raised.
// In this example, there is an error
// because type I used to constraint
// template parameters TP in trait T
// does not exist.
trait T<TP isA I>{
/*implementation*/
}
class C1{
/*implementation*/
}
class C1{
isA T< TP = C1 >;
/*implementation*/
}
Load the above code into UmpleOnline
If a multiple inheritance is applied as a constraint to a template parameter, it is detected and this error is raised. Umple does not support multiple inheritance.
// In this example, there is an error
// because trait T puts multiple
// inheritance constraint on its
// template parameter TP.
trait T<TP isA C1&C2>{
/*implementation*/
}
class C1{
/*implementation*/
}
class C2{
/*implementation*/
}
Load the above code into UmpleOnline
If clients bind types to the template parameters of used traits and the types exist but they do not satisfy the constraints of the template parameters, this error is raised. The constraint is related to inheritance.
// In this example, there is an error
// because class C1 is not subclass
// of class C2.
// Any bound value to template parameter
// TP must be a subclass of class C2.
trait T<TP isA C2>{
/*implementation*/
}
class C{
isA T< TP = C1 >;
/*implementation*/
}
class C1{/*implementation*/}
class C2{/*implementation*/}
Load the above code into UmpleOnline
If two state machines or regions are being composed and do not the same initial states.
// In this example, there is an warning
// because two traits T1 and T2 have
// state machines with the same name but
// with different initial states.
trait T1{
sm{
s1{ e1 -> s2;}
s2{ e3 -> s3;}
s3{ e2 -> s2;}
}
}
trait T2{
sm{
t1{ t1 -> t2;}
t2{ t3 -> s3;}
s3{ t2 -> t2;}
}
}
class C1{
isA T1,T2;
}
Load the above code into UmpleOnline
When a state is to be renamed, it should not be renamed more than one time. If this happens, the Umple compiler detects that and raises this error.
// In this example, there is an error
// because class C tries to
// rename states s0 of trait T two times.
trait T {
sm{
s0{
e1-> s1;
s11{ e12-> s12; }
s12{ e11-> s11; }
}
s1{ e0-> s1; }
}
}
class C {
isA T<sm.s0 as state0, sm.s0 as state01>;
}
Load the above code into UmpleOnline
When a state machine or state with a given name is specified by the renaming operator, it must be available in the trait being operated on, either directly in the trait or another trait used by the trait. Otherwise, the Umple compiler raises this error.
// In this example, there is an error
// because state machine sm3 is
// not available in trait T.
trait T {
sm1{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
sm2{
s0 {e1-> s1;}
s1 {e0-> s0;}
}
}
class C3 {
isA T<sm3 as mach1>;
}
Load the above code into UmpleOnline
When an event name is used with a specific name for its state machine, the state machine and event must be available in the trait, otherwise, the Umple compiler raises this error.
// In this example, there is an error
// because event e2() is not available
// in state machine sm.
trait T {
sm{
s0{
e1-> s1;
s11{ e12-> s12; }
s12{ e11-> s11; }
}
s1{ e0-> s1; }
}
}
class C {
isA T<sm.e2() as event2>;
}
Load the above code into UmpleOnline
When an event name is used with a specific name for its state machine, the state machine and event must be available in the trait. The same restriction is applied when the symbol * is used for the name of state machines. If the event is not available in at least one of the state machines existing in the trait, then the Umple compiler raises this error code.
// In this example, there is an error
// because event e2() is not available
// in state machines of trait T.
trait T {
sm{
s0{
e1-> s1;
s11{ e12-> s12; }
s12{ e11-> s11; }
}
s1{ e0-> s1; }
}
}
class C {
isA T<*.e2() as event2>;
}
Load the above code into UmpleOnline
The removing operator cannot be applied to the initial states of a state machine or a composite state. If the modeler applies it in such cases, the Umple compiler raises this error.
// In this example, there is an error
// because the initial state of a
// state machine cannot be removed.
trait T {
sm{
s0{
e1-> s1;
s11{ e12-> s12; }
s12{ e11-> s11; }
}
s1{ e0-> s1; }
}
}
class C {
isA T<-sm.s0>;
}
Load the above code into UmpleOnline
Umple does not support non-deterministic state machines and so composed state machines must be deterministic as well. Our composition algorithm automatically detects transitions that cause the composed state to be non-deterministic and raises this error code.
The example below shows how a transition in a base state could be cause to have non-determinism. As seen, both state machines in class C1 and trait T1 have state s1 and they need to be composed. The state s1 in trait T1 has transition e1[x>0] and the transition’s destination is s2. The base state s1 has transition e1 without a guard and its destination state is state s3. This transition does not exist in the state s1 coming from the trait, so it can be added to the composed state s1. However, this causes a situation in which the composite state machine can be in two states s2 and s3 simultaneously. Therefore, the composition is not allowed.
// In this example, there is an error
// because the composed state machine
// will be nondeterministic.
trait T1{
sm{
s1{ e1[x>0] -> s2; }
s2{ e2 -> s1; }
}
}
class C1{
isA T1;
sm{
s1{
e1 -> s3;
e3 -> s3;
}
s3{ }
}
}
Load the above code into UmpleOnline
When clients use more than one trait, using the keyword superCall can cause a conflict. This happens because an order of execution is required.
As seen in the example below, class C1 uses two traits T1 and T2 and there is matching state s1 and matching transition e1 needed to be composed. Since the keyword has been used in the base transition e1, it indicates that the actions of matching transitions are to be executed, but there is more than one action to be executed. Therefore, the Umple compiler prevents these models from being composed.
// In this example, there is an error
// because the keyword superCall can be
// pointed out to two used traits.
trait T1{
sm{
s1{ e1 -> /{action1();} s1; }
}
}
trait T2{
sm{
s1{ e1 -> /{action2();} s2;}
s2{}
}
}
class C1{
isA T1,T2;
sm{
s1{ e1 -> /{superCall; action3();} s3; }
s3{}
}
}
Load the above code into UmpleOnline
A client can use more than one trait (and obtain more than one state machine) and so it is possible to have more than two states whose entry (or exit) actions (and do activities) need to be composed with the base state’s entry action. In this case, the composition algorithm needs to consider an order among them. Since we do not consider any order when traits are used by clients, this should be respected in the composition of actions. Therefore, the Umple compiler detects this case and raises this error. Note that this conflict happens if more than one state coming from used traits have an entry action.
The example below shows a case in which composition of entry actions is considered as a conflict. The base state s1 in class C1 has no entry action and so it can accept entry actions coming from state machines in T1 and T2. However, there are two entries coming from used traits which cause a conflict. Note that if class C1 did not have state machine sm, it would still be a conflict for composition. However, if state s1 in class C1 had an entry then this would not be a conflict because those entries coming from traits would be disregarded.
// In this example, there is an error
// because of having different ways
// to compose entries of two states
// S1 coming from traits T1 and T2.
trait T1{
sm{
s1{ entry /{action1();} }
}
}
trait T2{
sm{
s1{ entry /{action2();} }
}
}
class C1{
isA T1, T2;
sm{
s1{}
}
}
Load the above code into UmpleOnline
A client can use more than one trait (and obtain more than one state machine) and so it is possible to have more than two states whose entry (or exit) actions (and do activities) need to be composed with the base state’s entry action. In this case, the composition algorithm needs to consider an order among them. Since we do not consider any order when traits are used by clients, this should be respected in the composition of actions. Therefore, the Umple compiler detects this case and raises this error. Note that this conflict happens if more than one state coming from used traits have an entry action.
The example below shows a case in which composition of entry actions is considered as a conflict. The base state s1 in class C1 has no entry action and so it can accept entry actions coming from state machines in T1 and T2. However, there are two entries coming from used traits which cause a conflict. Note that if class C1 did not have state machine sm, it would still be a conflict for composition. However, if state s1 in class C1 had an entry then this would not be a conflict because those entries coming from traits would be disregarded.
// In this example, there is an error
// because class C rename the region
// name r1 to r2 which is already
// available in the state machine sm.
trait T{
sm {
s1{
r1{ e1-> r11; }
r11{}
||
r2{ e2-> r21; }
r21{}
}
}
}
class C{
isA T<sm.s1.r1 as r2>;
}
Load the above code into UmpleOnline
When tracing an entity in a class, a warning will be issued if the entity is not found and
the trace directive will be ignored.
The name of the entity might be misspelled.
//The trace directive causes the
//warning to be issued as the attribute
//id is not found
class A {
Integer identifier;
trace id;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
//The warning is resolved
//by correcting the name of the
//attribute to be traced
@SuppressWarnings("deprecation")
class A {
Integer identifier;
trace identifier;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
A certain set of MOTL tracers can be specified for use
in Umple. Indicating a tracer that is not supported will cause the tracer directive
to be ignored, and the Console tracer will be used.
//The tracer used is not recognized,
//the Console tracer will be used
tracer OtherTracer;
@SuppressWarnings("deprecation")
class A {
Integer id;
trace id;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
//Using a supported tracer avoids
//the warning
tracer File;
@SuppressWarnings("deprecation")
class A {
Integer id;
trace id;
}
// @@@skipphpcompile See issue 596 (PHP tracing causes issues)
Load the above code into UmpleOnline
The keyword "constant" is still supported in Umple interfaces due to legacy reasons. However, there is no guarantee that this keyword will be supported in the future. The keyword "const" should be used instead.
// This causes the warning
interface Y {
constant A=5;
}
Load the above code into UmpleOnline
// This does not cause the warning
interface Y {
const A=5;
}
Load the above code into UmpleOnline
In Umple, a template name must be alphanumeric and
start with a letter or the symbol '_'.
//The name of the template is
//not valid and generates
//an error
class A {
!template <<!output!>>
}
Load the above code into UmpleOnline
//The name of the template
//is valid in the following
class A {
template <<!output!>>
}
Load the above code into UmpleOnline
A template emit method cannot be called "main", as it would cause a conflict with the main method.
//The emit method name
//cannot be main, the error
//is produced
class A {
template <<!output!>>
emit main()(template);
}
Load the above code into UmpleOnline
//Using another method name
//solves the error
class A {
template <<!output!>>
emit method()(template);
}
Load the above code into UmpleOnline
A template used in an emit method must exist within the context of the emit directive.
//The template name cannot be
//found as it does not exist
class A {
emit method()(template);
}
Load the above code into UmpleOnline
//The error is resolved by
//declaring the template
class A {
template <<!output!>>
emit method()(template);
}
Load the above code into UmpleOnline
A template reference cannot refer to itself. The logic of the template might be flawed.
//Template otherTemp refers to
//itself causing the error
class A {
temp <<! output !>>
otherTemp <<! <<@otherTemp>> !>>
}
Load the above code into UmpleOnline
//No template refers to itself,
//the error does not occur
class A {
temp <<! output !>>
otherTemp <<! <<@temp>> !>>
}
Load the above code into UmpleOnline
When referencing a template, an error is thrown if the template cannot be found. The
template name might be misspelled.
//The template otherTemplate
//is not found, generating the
//error
class A {
temp <<! <<@otherTemplate>> !>>
emit method()(temp);
}
Load the above code into UmpleOnline
//otherTemplate exists and can
//be referenced
class A {
otherTemplate <<! output !>>
temp <<! <<@otherTemplate>> !>>
emit method()(temp);
}
Load the above code into UmpleOnline
A template reference cannot be used in a cyclically referring way, creating an indirect
reference to itself. The issue might come from a flaw in the templates' design.
//The error arises as temp refers
//to temp3, referring to temp2, which
//causes a cycle due to temp2 referring
//to temp
class A {
temp <<! <<@temp3>> !>>
temp2 <<! <<@temp>> !>>
temp3 <<! <<@temp2>> !>>
emit method()(temp);
}
Load the above code into UmpleOnline
//There is no longer a cycle,
//the error is resolved
class A {
temp <<! <<@temp3>> !>>
temp2 <<! <<@temp>> !>>
temp3 <<! output !>>
emit method()(temp);
}
Load the above code into UmpleOnline
A class should have unique template names for each distinct template. If duplicate templates
are found, the last definition of the template is kept.
The warning might be caused by a template of the same name being defined in a separate file.
//Class A contains two templates
//of the same name, causing
//the warning
class A {
temp <<! output !>>
temp <<! otherOutput !>>
}
Load the above code into UmpleOnline
//The warning is resolved by
//giving the second template
//a distinct name
class A {
temp <<! output !>>
secondTemp <<! otherOutput !>>
}
Load the above code into UmpleOnline
Each emit method name must be unique in a class.
Attributing a different name to the duplicate method will solve the error.
//Class A contains two emit
//methods of the same name
class A {
temp <<! output !>>
otherTemp <<! output !>>
emit aMethod()(temp);
emit aMethod()(otherTemp);
}
Load the above code into UmpleOnline
//Changing the name of the
//second emit method resolves
//the issue
class A {
temp <<! output !>>
otherTemp <<! output !>>
emit aMethod()(temp);
emit aMethod2()(otherTemp);
}
Load the above code into UmpleOnline
A port used in a class must be defined before usage by port bindings and active methods. This is shown in the first example below, with a resolution in the second example.
This error might also be raised if you intended to create an association from the current class to another, but omitted the destination class. This is shown in the third example. The solution would be to add another class and then give the name of that class as the destination of the association after the asterisk.
//inB has not been defined
//in class A, causing the error
class A {
public in Integer inA;
public out Integer outA;
inB -> outA;
}
Load the above code into UmpleOnline
//Both inA and outA are
//defined; the error does
//not occur
class A {
public in Integer inA;
public out Integer outA;
inA -> outA;
}
Load the above code into UmpleOnline
//Destination class name is missing,
//causing the error
class X {
1 -> *;
}
Load the above code into UmpleOnline
In FIXML, a start tag must be closed properly with its respective end tag. Elements must also
be correctly nested within each other.
//The tags are not properly
//nested, causing E4500
<FIXML>
<tag>
<othertag>
</tag>
</othertag>
</FIXML>
Load the above code into UmpleOnline
//Each tag is now correctly
//closed
<FIXML>
<tag>
<othertag>
</othertag>
</tag>
</FIXML>
Load the above code into UmpleOnline
If strictness is set to 'modelOnly', this means that the developer intends to only include classes, associations, state machines and other modeling elements, but not embedded code in another programming language, not even method bodies.
If strictness is set to 'noExtraCode', it is the same as the above, except that method bodies are allowed.
This warning is issued when strictness has been set to one of the above, yet Umple has encountered sytax that interprets as either a method body or some other code in a class that it cannot parse, and is assuming it is native code to be passed to the native compiler.
This warning can often happen when the programmer/modeler wrote Umple code with a syntax error, so Umple thinks it is not Umple, but some other language. Here are some things to try in order to resolve this warning:
// The following example shows how to
// generate this warning.
strictness modelOnly;
class X {
public static void main() {
System.out.println("Hello World");
}
}
Load the above code into UmpleOnline
The strictness clause with 'expected' can be used to indicate that a certain message is expected. An error occurs when the expected warning or error does not actually occur.
Similarly, the strictness clause with 'disallowed' can be used to indicate that a certain message is not expected. An error occurs when the expected warning or error does occur.
In Umple, elements of a class not recognized as valid Umple are assumed to be elements of the target programming language that are embedded in the Umple. However, this warning is raised when the Umple compiler has reason to believe that the developer might have been trying to specify a state machine, because the segment of code starts with something like sm {.
Since that sequence is not found in target languages, and since it is easy to make a mistake specifying states, substates, guards, or events, this message is generated. If you encounter this message and indeed intended to specify a state machine, look carefully at the state machine code.
The following are some common mistakes and things to check if you get this warning when writing a state machine
If you are still stuck when writing details of a state machine, comment out segments until you can narrow down the problem.
// This example generates the warning
// on line 9 there is a missing semicolon
// on line 17 the = should be ==
// on line 24 the -> should be after the guard
// on line 30 there should be an / after entry
class X {
sm1 {
s1 {
a -> sb
}
s2{}
}
Integer v = 0;
sm2 {
s3 {
e1 [v = 5] -> s4;
}
s4 {}
}
sm3 {
s5{
e2 -> [v==1] s6;
}
s6{}
}
sm4 {
s6 {
entry {dosomething();}
e3 -> s7;
}
s7 {}
}
}
class X {
sm {
a -> b
b -> c
}
}
Load the above code into UmpleOnline
Umple emits such elements 'as is' (or what we call 'extra code') in its generated code, in case they are some part of the base language that Umple cannot understand.
// The following will generate two such warnings
class X {
blah blah blah;
1 - * X;
}
Load the above code into UmpleOnline
In Umple, elements of a class not recognized as valid Umple are assumed to be elements of the target programming language that are embedded in the Umple. However, this warning is raised when the Umple compiler has reason to believe that the developer might have been trying to specify a method, but omitted some aspect.
Note that currently, Java main methods generate this warning. It can be safely ignored in that context, and the warning will eventually be removed.
// This example generates the warning
// because there is a missing return type
class X {
m() {}
}
Load the above code into UmpleOnline
Umple generates a setter and getter for most attributes, and will issue a warning if these methods are redefined. The attempt to redefine the method will be ignored. Developers can either rename the redefined method or else use a before or after statement if they want to add functionality to the getter or setter method.
//The getAttr method is already
//generated by the declaration of
//the attribute attr and generates
//the warning
class A {
attr;
getAttr() {/* Implementation */};
}
Load the above code into UmpleOnline
//Modifying the name of the
//method can fix the warning
class A {
attr;
returnAttr() Java {/* Implementation */};
returnAttr() Python {''' Implementation '''};
}
Load the above code into UmpleOnline
When a constraint-like syntax is found but it cannot be processed by Umple, it is treated
as extra code and left as-is. The constraint might not be constructed properly.
The issue could come from unmatched parentheses or from an incorrect usage of operators.
//The warning is raised twice in
//the following as both constraints
//are not properly constructed
class A {
Integer a;
Integer b;
Integer c;
[(a > b)) && a < c]
[c < a | b > a]
}
Load the above code into UmpleOnline
//The warning is not generated
//by fixing the constraint syntax
class A {
Integer a;
Integer b;
Integer c;
[(a > b) && a < c]
[c < a || b > a]
}
Load the above code into UmpleOnline
For Association Classes with explicit keys, each class that participates in the relationship should be declared as a member of that key.
// This example generates the warning
// because one participating class is
// missing from the key
class Passenger {}
class Flight {}
associationClass Booking {
Integer number;
* Passenger;
* Flight;
key {number, flight}
}
Load the above code into UmpleOnline
// This example shows how to remove
// the warning by completing the key
class Passenger {}
class Flight {}
associationClass Booking {
Integer number;
* Passenger;
* Flight;
key {number, flight, passenger}
}
Load the above code into UmpleOnline
Injecting code before or after a method must be done on an existing method. The injection
will otherwise be ignored.
//getAttr does not exist in the class
//which generates the warning
class A {
before getAttr {
doSomething();
}
doSomething(){/* Implementation */}
}
// @@@skippythoncompile
Load the above code into UmpleOnline
//By declaring the attribute attr
//the getAttr method can now be used
class A {
attr;
before getAttr {
doSomething();
}
doSomething() {/* Implementation */}
}
// @@@skippythoncompile - Contains Java Code
Load the above code into UmpleOnline
Parameter specification on code injection does not apply to certain generated methods.
The code injection will be applied to all generated methods.
//The before statement refers to
//the getAttr method specifying no
//parameters, causing the warning
class A {
attr;
before getAttr() {
}
}
Load the above code into UmpleOnline
//The method is referred to without
//parameters in the following, avoiding
//the warning
class A {
attr;
before getAttr {
}
}
Load the above code into UmpleOnline
When excluding methods in a code injection with pattern matching,
a warning will be raised if a method is not found. The exclusion will be ignored.
Verifying which method was meant to be excluded will generally resolve the issue.
//The warning is generated as the code
//injection excludes getAttr3, which
//is not a method in class A
//The exclusion is ignored
class A {
attr;
attr2;
before getAttr*, !getAttr3 {
}
}
Load the above code into UmpleOnline
//Fixing the name of the
//method removes the warning
class A {
attr;
attr2;
before getAttr*, !getAttr2 {
}
}
Load the above code into UmpleOnline
These messages occur in several contexts:
When either a extra curly or extra round bracket is found. A warning will be raised.
Warning will show line number and removing the extra bracket will resolve the issue.
//The warning is generated as the code
// has a extra bracket on top (Could be open or close)
{
class A {
attr;
attr2;
}
Load the above code into UmpleOnline
//The warning is generated as the code
// has a extra bracket on top (Could be open or close)
(
class A {
attr;
attr2;
}
Load the above code into UmpleOnline
//Remove the extra bracket
//Removes the warning
class A {
attr;
attr2;
}
Load the above code into UmpleOnline
The argument to a use statement must be a valid .ump file found in the same directory as the file with the use statement, or in its parent directory, or in a subdirectory named lib. It can also be a builtin Umple library file (prefixed by lib:) or an https URL pointing to an umple file on the Internet.
Check the spelling of the filename, and check file permissions.
An inline mixset is one in a class, interface or trait and where the mixset name is not followed by block denoted by curly brackets. Most of the time to specify a mixset in a class you just specify the keyword mixset, followed by the name of the mixset, followed by the block of items to be included (e.g. attributes, methods, state machines, associations).
However Umple allows inline mixsets for certain entities in Umple. Inline mixsets allow for nested declarations of classes (to create subclasses), traits, and interfaces. However, empty code classes, interfaces, and traits are not allowed for inline mixsets.
If you encounter this error, you can easily add a pair of curly brackets around the code that a mixset introduces. The code bellow shows how to use inline mixsets.
/*
Example to show how to define inline mixsets.
*/
// The mixset M1 has been defined as inline mixset. this because the definition of the mixset is followed by a class definition.
mixset M1 class A {
isA B;
isA C;
x;
}
// M1 also is inline mixset because it has been followed by a trait definition without curly brackets.
// The usuall definition of M1 is:
/*
mixset M1
{
trait B
{
y;
}
}
*/
mixset M1 trait B
{
y;
}
// M2 is an inline mixset that defines an interface.
mixset M1 interface C { void method(); }
class D {
// M3 adds an attribute for class D. It's an inline mixset since there is no mention to which a class attr1 belongs to.
// However, Umple parser understands this implicit definition. Therefore, the attr1 will be added to the class D.
mixset M3 {attr1;}
}
//The line below will cause error since the interface E is empty.
//Mixset M4 interface E {}
use M1; use M2; use M3;
Load the above code into UmpleOnline
Code Labels allow aspects to inject code in specific locations inside method bodies. However, the code injection is only applied to the first encountered label. Therefore, a code label should not be reused multiple times (inside a method).
If you encounter this warning, you can easily rename code labels with unique names for each label inside the method body.
class CodeLabelExample
{
void methodToDoSomething()
{
//code
Label1: ;
int x=0;
//code
Label1: ;
x++;
}
// aspect injection in a code label.
after Label1:methodToDoSomething
{
int y =0;
}
}
// @@@skipcompile - injects code in impossible place
Load the above code into UmpleOnline
If you encounter this warning, you can easily comment out the use statement that causes this warning, or you can declare the mixset with an empty body.
// There are two options to get rid of this warning:
//option1: comment out the use statement below:
use M1;
// option2: remove the comment below to declare M1 with empty body :
//mixset M1 { }
Load the above code into UmpleOnline
Under development: Umple can have code in any programming language embedded in method bodies or other constructs. This warning is issued when the compiler for the embedded language reports an error. This can occur if the -c option is supplied to the Umple compiler, telling it to invoke the base language compiler after the Umple is generated.
Occasionally the Umple compiler may crash with certain code input, causing an error in the parsing phase (E9000), analysis phase (E9100) or generation phase (E9200). As soon as the Umple development team becomes aware of such a situation, we try to deal with it with a high level of priority.
In order to ensure the Umple development team is aware of the problem, please
report the issue, including
the code that generated the error and the stack trace that accompanied the message.
You most likely encountered an error or warning in UmpleOnline, and clicking on the message displayed this page. The web page explaining that message has not yet been created. In the meantime, you can search the manual or browse the links on the left.
Features are often added to the syntax of Umple before they are added to the semantics and code generation. This is to ensure that adding the feature will not break existing code. If you receive this warning, then it means you are using such a feature. No code is yet generated from this feature, or else the generated code is incomplete.
The immutable keyword in Umple can be applied to a class, an attribute or an association to ensure that they can only be set in the constructor, and cannot be modified again subsequently. The immutability of associations means that all associated objects must be specified as unique constructor arguments. Violation of this is detected by the constructor, in which case a RuntimeException is thrown. This can be caught by a try-catch block.
In the example below, an immutable Path has immutable pathElements (instances of Point2D). The Path instances are of an immutable class too (here Point2D), and the only way to construct this association is in arguments to the constructor. But it is necessary to avoid duplicate objects in the constructor and a runtime exception is thrown when this constraint is violated. So, a runtime exception is thrown here when an attempt is made to create a Path with duplicate instances of Point2D.
// This demonstrates code that will throw the
// immutability exception
class Point2D
{
immutable;
Float x;
Float y;
}
class Path
{
immutable;
1 -> * Point2D pathElements;
public static void main(String[] argv) {
Point2D p2d = new Point2D(0,0);
// This will throw an exception since the
// pathElements cannot be duplicate
try {
Path p = new Path(p2d,p2d);
}
catch (RuntimeException re) {
System.out.println("Exception Caught: "+re+"\n");
}
}
}
Load the above code into UmpleOnline
Umple manages multiplicity by blocking operations that would allow too many or too few instances of a class to be linked. There are two ways in which links can be set, hence violating multiplicity: a) in a constructor, or b) after construction using an ordinary method. In a case of a constructor that would violate multiplicity, a RuntimeException is thrown. This can be caught by a try-catch block. After construction, any method that attempts to violate the multiplicity will return false.
In the first example below a student is always required to have a program. A runtime exception is thrown when an attempt is made to create a Student without specifying a required program. A method that attempt to violate multiplicity, and hence returns false, is shown at the end of the first example.
The second example shows a runtime exception that is thrown in the case of a one-to-one association. Since for such associations there must always be equal numbers of both associated classes, and objects of the two classes must be created in pairs, the constructor of either class also creates instances of the other class. An attempt to call such a constructor with a null argument will throw a runtime exception.
// This demonstrates code that will throw the
// multiplicity exception
class Program {
title;
1 -- * Student;
}
class Student {
name;
public static void main(String[] argv) {
Student s1 = null;
Program p1 = null;
// This will throw an exception since there must
// be at least one program
try {
s1 = new Student("Abel", null);
}
catch (RuntimeException re) {
System.out.println("Exception Caught: "+re+"\n");
}
// After we create a program we can repeat the
// attempt.
p1 = new Program("Computer Science");
s1 = new Student("Abel", p1);
// Attempting to change the program back to null
// will not throw an exception but will result
// in null being thrown
if(!s1.setProgram(null)) {
System.out.println("Could not set program "+
"to null as would violate multiplicity \n");
}
}
}
Load the above code into UmpleOnline
// This demonstrates code that will throw a
// multiplicity exception in 1--1 associations
class StockSymbol {
code;
1 -- 1 Company;
}
class Company {
name;
public static void main(String[] argv) {
Company c1 = null;
StockSymbol s1 = null;
// This will throw an exception since the stock
// symbol cannot be null
try {
c1 = new Company("Umpleco", s1);
}
catch (RuntimeException re) {
System.out.println("Exception Caught: "+re+"\n");
}
// This will succeed: Umple 1--1 constructors
// create both objects at once
c1 = new Company("Umpleco","UMPC");
s1 = c1.getStockSymbol();
System.out.println("The company: "+
c1+"\n"+
"The stock symbol: "+
s1+"\n");
}
}
Load the above code into UmpleOnline
The unique keyword in Umple can be applied to an attribute to ensure that each instance of the class in the currently running program has a unique value for that attribute. The code generated by Umple will not allow this constraint to be violated.
If an attempt is made to call the constructor of a class with an argument that would result in a violation of the uniqueness constraint, an exception will be thrown. The text of the constraint will start with the phrase "Cannot create".
In the example below,
Programs should be designed with logic that avoids violation of uniqueness. It is not recommended that production code relies on catching this exception as a normal part of its logic.
// This demonstrates code that will throw the
// uniqueness exception
class Student {
unique Integer number;
name;
public static void main(String[] argv) {
Student s1 = null;
Student s2 = null;
Student s3 = null;
Student s4 = null;
System.out.println("Initial\ns1= "+s1+
"\ns2= "+s2+"\ns3= "+s3+"\n\n");
// We set up the first student s1 with no problem
s1 = new Student(1,"Abel");
// For the second student we use a try catch
// block to catch the exception
// Ideally code would avoid creating violations
// to start with, but the following
// approach can be used as a safety mechanism.
try {
s2 = new Student(1, "Baker");
}
catch (RuntimeException re) {
System.out.println("Exception Caught: "+re+"\n");
}
// We now create a student that doesn't
// violate uniqueness
s3 = new Student(2,"Charlie");
// Uniqueness can also be detected by trying
// to change a value
// This does not throw the exception, since
// the setNumber() method returns false
boolean result = s3.setNumber(1);
if(!result) System.out.println(
"Could not change number as it would have"+
" violated uniqueness\n");
System.out.println("Final\ns1= "+s1+
"\ns2= "+s2+"\ns3= "+s3+"\n\n");
// The following will throw the exception
// without being caught
s4 = new Student(1, "Delta");
// This statement will not be reached
System.out.println(
"This line should not be reached");
}
}
Load the above code into UmpleOnline
Testcase can be embed within the Umple model and will be generated when using the Test generator. A testcase can be embedded at the class-level or the model-level.
A testcase canonsists of the following elements:
Initialization: ~identidier ~name = ~value;
class Student {
id = "ID123";
name = "John";
test checkSetId {
Student s ();
assertTrue(s1.setId("ID432"));
}
}
Load the above code into UmpleOnline
class Student {
id;
name;
test checkSetId {
Student s ("98CS","Jane");
assertEqual(s.getId(),"98CS");
s.setName("Roger");
assertFalse(s.getName() == "Jane");
}
}
Load the above code into UmpleOnline
Test can be automatically generated by compiling the Umple model with the test generator. This can be done using the following commandline
class Advisor
{
name;
id;
int tel;
0..1 -- * Student;
1 -- * Office;
2 -- * Course;
}
class Student {
name;
}
class Office {
name;
lazy address;
}
class Course {
code;
int numberOfStudents;
description;
Date startDate = "2020-12-26";
Time classTime = "12:59:59";
}
Load the above code into UmpleOnline
Tests can be integrated with mixsets to enhance feature-based testing. This allows the user to toggle feature-specific tests using a mixset dedicated for testcases that can be switched on using the use mixsetTest; statement. The following example shows how to create a mixset for testing another mixset. Note the tests can also be embedded in the same mixset or can be defined in a separate one. The only issue that need to be handled is that dependency between mixsets. If your test case contains an instantiated object that uses attribute in a particular mixset then either embed the tests within the mixset to avoid errors or make sure you always switch-on the targeted feature to avoid instantiation errors. Currently, this is not caught by the compiler but will be added.
class Student {
id;
name;
}
mixset Job {
class Student {
job;
Integer jobRank = 1;
void promote () {
this.setJobRank(this.jobRank + 1);
}
}
}
mixset JobTest {
class Student {
test checkPromotion {
Student s1 ("ID123", "John", "Director");
assertTrue(s1.getJobRank() == 1);
s1.promote();
assertTrue(s1.getJobRank() == 2);
}
}
}
use Job;
use JobTest;
Load the above code into UmpleOnline
Generic testcase is an Umple testcase that is defined as generic. This allows you write a test template that has access to the metamodel in order to propagate the template against a number of elements those match a certain pattern. For instance, you can write a generic test that can be generated for each attribute that is string and has a certain prefix 'studentXXX' or a suffix such as 'XXXId'. You can also use regular expression to match attribute name. We can this a fix in the template. Currently, generic tests can be generated for: attributes, methods and associations. Attibutes can be matched using name and type, methods can be matched using name and exact order of parameters and association are matched based on the type of associations and given specfic fixes to handle association variable propagation.
class Student {
String studentId;
nameMemebershipId;
address;
studentAge;
generic test checkifLogged(String attribute.regex(\w*Age)){
Student st1 ( "S1425", "John", "Ottawa",20) ;
String valueToCheck = st1.get<<attribute>>();
assertTrue(valueToCheck > 18);
}
}
Load the above code into UmpleOnline
class Calculator{
1--* Number;
0..1->* Controller;
generic test checkifLogged(0..1->* association){
Calculator c1 () ;
Number n1(c1);
Number n2(c1);
Controller cn1();
Controller cn2();
c1.addNumber(n1);
c1.addNumber(n2);
c1.addController(cn1);
c1.addController(cn2);
String numberInList = c1.numberOf<<association.toSingular()>>s();
if(c1.numberOfNumbers() > 2)
{
assertTrue (numberInList > 2);
}
else {
assertTrue (numberInList < 2)
}
}
}
class Number {
}
class Controller {
}
Load the above code into UmpleOnline
class Calculator{
Integer x;
Integer y;
String someString;
Integer returnInteger (Integer x) { return x+y;}
String returnStirng (Integer x) { return someString;}
generic test checkifLogged(Integer method Integer){
Calculator c1 ( 4, 5) ;
String valueToCheck = p1.get<<method>>();
ps1.getValue(<<method>>);
boolean isLogged = p1.checkIsLogged(valueToCheck);
assertTrue(logged == "true");
}
generic test checkifLogged(String method Integer){
// code omitted
}
}
Load the above code into UmpleOnline